
Ce blog n'a d'autre prétention que de me permettre de mettre à la disposition de tous des petits textes que j'écris. On y parle surtout d'informatique mais d'autres sujets apparaissent parfois.
Fiche de lecture : Bitcoin - métamorphoses
Auteur(s) du livre : Jacques Favier, Benoît
Huguet, Adli Takkal Bataille
Éditeur : Dunod
9-782-100-784646
Publié en 2018
Première rédaction de cet article le 30 décembre 2018
Le Bitcoin suscite toujours autant de passions, et les informations à son sujet varient toujours de l'enthousiasme délirant aux enterrements prématurés. Il est amusant de noter que les uns comme les autres utilisent souvent les mêmes arguments qu'il y a dix ans, au moment du lancement de la cryptomonnaie. Au contraire, le livre de Favier, Huguet et Bataille se demande « où en est le Bitcoin aujourd'hui ? » Certainement pas au même point qu'en 2008.
J'avais déjà parlé du précédent livre de ces auteurs. Celui-ci est destiné à un public plus informé, qui connait déjà le Bitcoin et souhaite s'informer sur les derniers développements.
Comme dans leur livre antérieur, les auteurs n'hésitent pas à nager à contre-courant du discours dominant. Depuis deux ou trois ans, la mode est à dire « le Bitcoin, c'est pas bien mais la chaîne de blocs, c'est la solution à tous les problèmes de l'humanité ». Pour eux, au contraire, le Bitcoin reste la meilleure solution à bien des problèmes pour lesquels on crée de nouvelles chaînes de blocs, et ils sont très confiants dans sa capacité à évoluer pour répondre aux défis d'aujourd'hui. Les auteurs suggèrent que ce discours bruyant sur la chaîne de blocs sert à évacuer le caractère disrupteur du Bitcoin et à ramener le torrent des cryptomonnaies dans son lit, un lit bien contrôlé et bien régulé.
Les auteurs notent bien que la grande majorité des articles sur le Bitcoin sont très médiocres, juste une compilation de clichés (Law, les tulipes et Ponzi). Parfois, la malhonnêteté intellectuelle va plus loin, comme le reportage de France 2 sur le Bitcoin se terminant par… un envol de pigeons. Comme le notent Favier, Huguet et Bataille, « illustre-t-on un reportage sur une banque centrale par des photos de poulets en batterie ? »
Un autre exemple de la propagande contre les cryptomonnaies concerne les ICO, un mécanisme de financement où une entreprise débutante vend des jetons d'une cryptomonnaie… qui n'existe pas encore. Les ICO sont systématiquement diabolisés dans les médias, qui ne parlent que du risque de perdre son argent, si l'entreprise se casse la figure. Mais, comme le disent les auteurs « pourquoi est-il admis qu'on puisse perdre de l'argent avec la Française des Jeux et pas avec les ICO ? »
À juste titre, les auteurs sont hostiles au concept de « chaîne de blocs privée » (ou « chaîne de blocs à permission ») en notant qu'il s'agit soit de banales bases de données partagées, rebaptisées chaîne de blocs pour des raisons marketing, soit d'erreurs techniques où on utilise une chaîne de blocs pour un problème où elle n'est pas la meilleure solution. En effet, tout l'intérêt de Bitcoin est de fournir de la confiance dans un état alors même que les participants ne se connaissent pas. Si les participants se connaissent et ont déjà une structure en place ou, pire, si le seul participant est une entreprise spécifique, la chaîne de blocs n'a guère d'intérêt.
Et pendant ce temps, Bitcoin ne reste pas inactif : si le logiciel et le protocole n'évoluent qu'avec prudence, la communauté autour du Bitcoin, elle, a beaucoup changé et, au milieu de nombreuses crises, a prouvé sa faculté à s'adapter, dans un environnement impitoyable.
Le gros du livre tourne autour d'un enjeu technique essentiel pour toute chaîne de blocs : le passage à l'échelle. Vu que la taille de blocs de Bitcoin est limitée (notamment pour éviter certaines attaques par déni de service) et que l'écart de temps entre deux blocs est fixe, Bitcoin ne peut pas traiter un nombre illimité de transactions. Une chaîne de blocs qui ne mettrait pas de limite aurait d'autres problèmes, notamment la croissance illimitée de la chaîne, que tous les pairs doivent charger. Bref, on ne peut pas envisager, avec le Bitcoin classique, un monde où chacun paierait son café à la machine avec des bitcoins. Il faut donc améliorer le passage à l'échelle. Ce sujet est bouillonnant en ce moment dans le monde Bitcoin. (Le livre remarque que cela évoque l'époque où les experts auto-proclamés répétaient que l'Internet n'avait pas d'avenir, qu'il s'écroulerait dès qu'on essaierait de s'en servir vraiment, pendant que les vrais experts travaillaient à améliorer l'Internet, afin qu'il puisse assurer le service qu'en attendaient les utilisateurs.)
Les auteurs décrivent donc les solutions comme les « chaînes de côté » (sidechains, comme par exemple Blockstream ou RootStock) où une chaîne ayant moins de limites sert pour les transactions courantes, et son état final est mis de temps en temps sur une chaîne principale, par exemple celle de Bitcoin. Ainsi, la chaîne de côté croît vite mais on n'a pas besoin de la garder éternellement. Autre possibilité, les échanges hors-chaîne mais reportés sur la chaîne comme avec le Lightning Network. Cette partie du livre est plus difficile à lire, reflétant le caractère très mouvant de ces innovations.
Le livre couvre également en détail le cas des scissions, notamment la plus grosse qui a affecté Bitcoin depuis deux ans, et qui est toujours en cours, Bitcoin Cash (sans compter Bitcoin SV.)
Le cas des contrats automatiques est aussi traité, en exprimant un certain scepticisme quant à la possibilité d'en produire sans bogues. Mais, surtout, le livre note que la plupart des problèmes « intéressants » qu'on pourrait traiter avec des contrats automatiques nécessitent de l'information sur le monde extérieur à la chaîne. Si le déroulement d'un contrat automatique d'assurance dépend du temps, par exemple, il faudra bien accéder à des informations météorologiques, et cela ne sera plus pair-à-pair, cela ne pourra pas se faire entièrement sur la chaîne de blocs. (Il faudra utiliser ce qu'Ethereum appelle des oracles, qui ne sont pas pair-à-pair, donc posent un problème de confiance.)
Le monde Bitcoin, sans même parler des autres cryptomonnaies, est très actif en ce moment et des nouvelles propositions émergent tous les jours et d'innombrables essais sont lancés. Ce livre est donc un document utile pour avoir une vision relativement synthétique de l'état actuel de Bitcoin et de ses dernières évolutions. J'ai apprécié le côté ouvert de ce livre, qui présente des changements en cours, sans essayer d'imposer une vision unique.
Note : j'ai reçu (sans engagement) un exemplaire gratuit de ce livre par l'éditeur.
L'article seul
Fiche de lecture : Cyberfatale
Auteur(s) du livre : Clément Oubrerie (Dessin), Cépanou
(Scénario)
Éditeur : Rue de Sèvres
9-782369-815266
Publié en 2018
Première rédaction de cet article le 29 décembre 2018
Première (?) BD à parler de cybersécurité et de cyberguerre, « Cyberfatale » est une bonne introduction au monde de la lutte « cyber » entre États.
Il est significatif de l'état de la communication et de l'information en matière de « cyber » qu'une BD soit plus sérieuse et mieux informée que la plupart des livres supposés sérieux sur le sujet. Pas de sensationnalisme dans « Cyberfatale », juste une bonne description des attaques (de la plus triviale, un site Web de l'État défiguré, à la plus ennuyeuse, un engin de guerre piraté informatiquement) et des réactions (qui sont, on n'en sera pas surpris, surtout axées sur la communication : « si ça sort, on est morts »). L'un des personnages doit à un moment rédiger un texte officiel sur la cyberdéfense et, après avoir aligné les poncifs dans son texte, se dit « c'est incompréhensible, c'est parfait ».
Il est recommandé de connaitre un peu le sujet, pour comprendre les clins d'œil mais, sinon, l'auteur a pensé aux débutants avec un excellent glossaire, très drôle, et a inventé un personnage d'officière débutante dans le « cyber », excellent prétexte pour donner des explications au lecteur / à la lectrice.
J'ai particulièrement apprécié que le livre fasse une place importante à la question de l'attribution des attaques. Si l'exemple d'analyse d'un logiciel malveillant est ultra-simplifié (mais c'est une BD, pas un livre de rétro-ingénierie), en revanche, la difficulté à être sûr de l'identité de l'attaquant est bien rendue.
Ah, et comme rien n'est parfait, un reproche : le texte utilise à tort le terme « crypter ».
L'article seul
Books - Internet, pièges et maléfices
Première rédaction de cet article le 26 décembre 2018
Tout a commencé par une panne d'un Eurostar. Immobilisé sur la voie, il bloquait toute la ligne à grande vitesse du nord de Paris. Mon TGV pour Lille a eu une heure et demie de retard. En attendant ce TGV, je pouvais perdre du temps sur des réseaux sociaux futiles, ou bien lire les vrais penseurs qui écrivent sur du papier. J'ai donc acheté un hors-série de la revue Books, « Internet, pièges et maléfices ». Conseil : n'achetez pas cette revue. Il faut le faire une fois pour savoir mais, après, on peut s'abstenir, c'est très mauvais.
Le hors-série est consacré aux problèmes liés à l'Internet, ou plutôt essentiellement aux GAFA car c'est presque tout ce que les auteurs connaissent de l'Internet. La plupart des textes sont de la simple propagande anti-Internet, style Finkielkraut ou Joffrin, mais traduits de l'anglais, et publiés initialement dans des revues intellectuelles états-uniennes prestigieuses (genre The New York Review of Books ou The New Yorker), avant d'être rassemblés par Books dans ce hors-série.
Cela peut paraitre bizarre de parler de « propagande ». Après tout, l'Internet n'est ni un parti politique, ni une idéologie. Mais pourtant, la plupart des articles collectés ici ne sont effectivement pas du niveau de l'argumentaire mais de celui de la propagande : aucune référence précise, aucune vérification des faits, aucune mise en perspective. Ainsi, l'inévitable article sur le darknet ne manque pas de reprendre le cliché classique « tous les groupes terroristes ont une présence sur Internet » (p. 65), ce qui est factuellement exact (de même que « tous les terroristes utilisent une voiture ou le métro » ou bien « tous les terroristes boivent de l'eau ») mais n'offre aucune information, à l'époque où tout le monde a une présence sur Internet.
Books se veut intellectuel donc la propagande est légèrement plus subtile que sur BFM TV. Ainsi, l'article sur le darknet reconnait à mots couverts que le recrutement de tueurs à gages sur le darknet est une légende urbaine. C'est un des rares cas où il y a eu un scrupule tardif de l'auteur.
Mais autrement, tous les clichés se succèdent. On y trouve la traditionnelle bulle de filtres, comme si, avant Internet, le militant communiste lisait autre chose que l'Humanité et le patron autre chose que le Figaro, comme si, au café du commerce, on ne parlait pas déjà uniquement avec des gens proches, comme si les intellectuels qui passent à la télé allaient de temps en temps sur les rondspoints pour parler avec des gilets jaunes. On y voit le méchant Internet tuer les artistes car tout est gratuit. Bien sûr, Wikipédia n'est pas fiable et est trumpiste, puisque prétendant que toutes les vérités se valent. On y trouve les jeunes qui ne lisent plus, l'ordiphone qui rend bête, etc. On reconnait les deux ou trois mêmes personnes qui sont systématiquement cités dans les articles anti-Internet, Morozov et Lanier. Notez que je ne les compare pas : Morozov dit des choses qui font réfléchir, lui. Lanier n'est cité que parce que la propagande aime bien les repentis.
Bref, rien d'original ou de nouveau, pour une revue qui parait fin 2018 (certains articles sont des reprises et sont plus anciens). Question clichés, il ne manque que celui comme quoi les dirigeants de la Silicon Valley mettraient leurs enfants dans des écoles sans ordinateurs.
Critiquer Internet est chic dans certains cercles intellectuels, aux États-Unis comme en France. Par contre, critiquer le capitalisme est tabou : pas question de dire que Google est une entreprise capitaliste, et que cela explique mieux son comportement que de fumeuses références au transhumanisme. Critiquer le capitalisme, ou même simplement l'appeler par son nom, vous fait tout de suite classer chez les affreux communistes. Il faut donc prendre les devants et plusieurs articles de la revue mentionnent les pays de l'ex-URSS, notamment la Biélorussie, en décrivant l'horreur des régimes staliniens, pour bien enfoncer le clou « nous attaquons l'Internet mais nous n'attaquons pas le capitalisme, nous ne sommes pas des communistes, rassurez-vous ». Seul l'interview de Chris Hedges (par ailleurs très réactionnaire) nomme simplement les choses, en disant que Facebook et Google agissent comme ils agissent parce que ce sont des entreprises capitalistes.
Et, pour les lecteurs paresseux qui, contrairement à moi, n'auraient pas lu tous les articles, l'introduction anonyme fournit une synthèse toute faite « Books a été parmi les tout premiers organes de presse à attirer l'attention sur les risques que le développement d'Internet fait peser sur les démocraties ».
Tous les articles de ce numéro ne sont pas aussi caricaturaux que ceux que j'ai résumés ici. L'article de Frank Furedi sur la surinformation est une bonne synthèse historique. L'auteur y fait bien remarquer qu'à chaque saut technologique (notamment l'écriture et l'imprimerie), les contemporains ont eu peur de cet « excès d'information ». Et il analyse à juste titre que cette peur vient du fait qu'on n'a pas tout de suite les outils (techniques et intellectuels) pour gérer cet afflux d'information rendu possible par la nouvelle technique. De même, James Gleick sur les Anonymous, et Ben Jackson sur le harcèlement ont fait de bons articles qui ne sont pas unilatéraux dans leurs conclusions.
Mais cela ne devait pas plaire à la rédaction : les articles exprimant un point de vue nuancé sont systématiquement dotés d'encadrés qui les contredisent. (Une belle violation du droit moral, à mon avis, que ces pavés placés au milieu de l'article d'un auteur et qui prennent le contrepied de l'article !) Et, alors que les articles sont signés, ces encadrés sont anonymes (juste signés « Books »). Frank Furedi a même droit à deux encadrés.
La passion du propagandiste va jusqu'à accompagner l'article d'Edward Luttwak consacré à Edward Snowden d'un texte (p. 39) qui affirme que Snowden est lié à la Russie et en donnant pour preuve le fait qu'il encourage à utiliser Tor (stupidement qualifié de « moteur de recherche ») ajoutant que Tor est financé par la Russie ! Dans le monde réel, Tor est financé par l'armée états-unienne, ce que dit d'ailleurs bien un autre article (p. 62). Mais personne ne fait de vérification chez Books. On voit donc que les mensonges à des fins de propagande ne sont pas une exclusivité de RT.
La rédaction ne s'est pas acharnée uniquement à coups d'encadrés dans les articles qui ne convenaient pas au discours souhaité. Elle a aussi utilisé les chapeaux. Ainsi dans un article sur le darknet, le chapeau affirme que Bitcoin est « intraçable », alors que l'article, p. 64, explique à juste titre que c'est le contraire (à propos de l'enquête Silk road).
Autre malhonnêteté intellectuelle utilisée dans cette revue, c'est l'allusion. Au contraire des mensonges francs et clairs (le financement de Tor par la Russie…), l'allusion n'affirme rien de précis, mais laisse entendre. Ainsi, p. 63, le Bitcoin est critiqué car ne reposant pas sur l'or ou l'argent (ce qui est exact, mais est également vrai de toutes les autres monnaies), et laisse entendre que les monnaies fiat (celles des États), elles, le seraient.
Enfin, la revue use largement de formules jolies mais ne reposant pas sur des faits précis et vérifiables. On lit par exemple que Bitcoin repose sur une « formule mathématique obscure ». On joue ici sur l'aversion des médias pour la mathématique, présentée comme difficile et obscure, pour éviter que les citoyens ne se penchent sur les questions compliquées, afin de laisse entendre qu'il y aurait un secret caché dans Bitcoin. Ce n'est pas le cas, le logiciel est libre, on peut vérifier qu'il utilise de la cryptographie classique et bien connue. Certaines cryptomonnaies comme Monero ou Zcash utilisent en effet des algorithmes cryptographiques moins connus et difficiles à appréhender, mais, comme pour le Bitcoin, ils n'ont rien d'obscur et sont largement documentés. Mais l'effet visé était purement rhétorique : « obscur » (comme le dark de darknet) fait peur.
L'article seul
RFC 8493: The BagIt File Packaging Format (V1.0)
Date de publication du RFC : Octobre 2018
Auteur(s) du RFC : J. Kunze (California Digital
Library), J. Littman (Stanford
Libraries), E. Madden (Library of
Congress), J. Scancella, C. Adams (Library of Congress)
Pour information
Première rédaction de cet article le 20 décembre 2018
Le format BagIt, très utilisé dans le monde des bibliothèques (monde d'où sont issus les auteurs de ce RFC), décrit une série de conventions pour un ensemble de fichiers décrivant un contenu numérique quelconque. En fait, BagIt n'est pas vraiment un format (on ne peut pas le comparer à tar ou à zip), il définit juste les fichiers qui doivent être présents dans l'archive.
Une archive BagIt est appelée un sac (bag). Elle est composée des fichiers de contenu, qui sont d'un format quelconque, et des fichiers de métadonnées, qui décrivent le contenu (ces fichiers de métadonnées se nomment tags). BagTit met l'accent sur le contrôle de l'intégrité des données (les tags contiennent un condensat cryptographique des données) et sur la facilité d'accès à un fichier donné (les fichiers de données ne sont pas sérialisés dans un seul grand fichier, comme avec tar ou zip, ils restent sous la forme d'une arborescence).
La section 2 du RFC décrit la structure d'un sac :
- Des fichiers de métadonnées (les
tags) dont deux sont obligatoires,
bagit.txtqui indique le numéro de version BagIt, etmanifest-HASHALGO.txtqui contient les condensats. - Un répertoire
data/sous lequel se trouvent les fichiers de données. - Si on veut, des répetoires contenant des fichiers de métadonnées optionnels.
Voici un exemple d'un sac, contenant deux fichiers de données,
Makefile et
bortzmeyer-ripe-atlas-lapaz.tex :
% find /tmp/RIPE-Atlas-Bolivia
/tmp/RIPE-Atlas-Bolivia
/tmp/RIPE-Atlas-Bolivia/manifest-sha512.txt
/tmp/RIPE-Atlas-Bolivia/data
/tmp/RIPE-Atlas-Bolivia/data/Makefile
/tmp/RIPE-Atlas-Bolivia/data/bortzmeyer-ripe-atlas-lapaz.tex
/tmp/RIPE-Atlas-Bolivia/manifest-sha256.txt
/tmp/RIPE-Atlas-Bolivia/tagmanifest-sha256.txt
/tmp/RIPE-Atlas-Bolivia/bag-info.txt
/tmp/RIPE-Atlas-Bolivia/tagmanifest-sha512.txt
/tmp/RIPE-Atlas-Bolivia/bagit.txt
% cat /tmp/RIPE-Atlas-Bolivia/bagit.txt
BagIt-Version: 0.97
Tag-File-Character-Encoding: UTF-8
% cat /tmp/RIPE-Atlas-Bolivia/bag-info.txt
Bag-Software-Agent: bagit.py v1.7.0 <https://github.com/LibraryOfCongress/bagit-python>
Bagging-Date: 2018-12-20
Contact-Email: stephane+atlas@bortzmeyer.org
Contact-Name: Stéphane Bortzmeyer
Payload-Oxum: 6376.2
% cat /tmp/RIPE-Atlas-Bolivia/manifest-sha256.txt
6467957fa9c06d30c1a72b62d13a224a3cdb570e5f550ea1d292c09f2293b35d data/Makefile
3d65d66d6abcf1313ff7af7f94b7f591d2ad2c039bf7931701a936f1305ac728 data/bortzmeyer-ripe-atlas-lapaz.t
Les condensats ont été faits avec SHA-256.
Le fichier obligatoire bagit.txt doit
indiquer le numéro de version et
l'encodage. Le RFC décrit la version 1.0
mais, comme vous pouvez le voir plus haut, j'ai utilisé un outil un
peu ancien pour fabriquer le sac. Le répertoire
data/ contient les fichiers de données, non
modifiés (BagIt les traite comme du contenu binaire, copié au bit
près). manifest-sha256.txt contient une ligne
par fichier de données, indiquant le condensat. Notez qu'il peut y
avoir plusieurs manifestes, avec des
algorithmes différents. Cela permet, si un nouvel algorithme de
condensation plus
solide apparait, d'ajouter le manifeste au sac. Les noms
d'algorithmes de condensation sont tirés du registre
IANA du RFC 6920. Quant aux fichiers
(non obligatoires) dont le nom commence par
tagmanifest, ils indiquent les condensats des
fichiers de métadonnées :
% cat /tmp/RIPE-Atlas-Bolivia/tagmanifest-sha256.txt 16ed27c2c457038ca57536956a4431de4ac2079a7ec8042bab994696eb017b90 manifest-sha512.txt b7e3c4230ebd4d3b878f6ab6879a90067ef791f1a5cb9ffc8a9cb1f66a744313 manifest-sha256.txt 91ca8ae505de9266e37a0017379592eb44ff0a2b33b240e0b6e4f2e266688a98 bag-info.txt e91f941be5973ff71f1dccbdd1a32d598881893a7f21be516aca743da38b1689 bagit.txt
Enfin, le facultatif bag-info.txt contient des
métadonnées qui ne sont typiquement prévues que pour les humains,
pas pour être analysées automatiquement. La syntaxe est la classique
Nom: Valeur. Certains des noms sont
officiellement réservés (Contact-Name,
Bagging-Date…) et on peut en ajouter d'autres à
volonté.
Le sac est un répertoire, pas un fichier, et ne peut donc pas être transporté simplement, par exemple avec le protocole HTTP. On peut utiliser rsync, ou bien le sérialiser, par exemple en zip.
Il est amusant de noter qu'un sac peut être incomplet : des
fichiers de données peuvent être stockés à l'extérieur, et récupérés
dynamiquement lorsqu'on vérifie l'intégrité du sac. Dans ce cas, le
condensat dans le manifeste permettra de vérifier qu'on a bien
récupéré le contenu attendu. Les URL où
récupérer ce contenu supplémentaire seront dans un fichier
fetch.txt.
Un sac peut être complet (ou pas) et ensuite
valide (ou pas). La section 3 de notre RFC
définit ces termes : un sac est complet s'il contient tous les
fichiers obligatoires, et que tous les fichiers dans les manifestes
sont présents, et que les fichiers comme
bagit.txt ont une syntaxe correcte. Un sac est
valide s'il est complet et que tous les
condensats sont corrects.
La section 5 du RFC détaille quelques questions de sécurité liées à BagIt :
- BagIt va fonctionner entre systèmes
d'exploitation différents. Les noms de fichiers
peuvent comporter des caractères qui sont spéciaux pour un système
d'exploitation mais pas pour un autre. Une mise en œuvre de BagIt
sur Unix, par exemple,
ne doit donc pas accéder aveuglément à un fichier commençant par
une barre oblique, ou bien comprenant
/../../../. (Une suite de tests existe, avec plusieurs sacs… intéressants, permettant de tester la robustesse d'une mise en œuvre de BagIt.) - La possibilité de récupérer des fichiers distants ouvre évidemment plein de questions de sécurité amusantes (les plus évidentes sont résolues par l'utilisation de condensats dans les manifestes, je vous laisse chercher les autres).
Sans que cela soit forcément un problème de sécurité, d'autres différences entre systèmes d'exploitation peuvent créer des surprises (section 6 du RFC), par exemple l'insensibilité à la casse de certains systèmes de fichiers, ou bien la normalisation Unicode. La section 6 est d'ailleurs une lecture intéressante sur les systèmes de fichiers, et leurs comportements variés.
Passons maintenant aux programmes disponibles. Il en existe en plusieurs langages de programmation. Le plus répandu semble bagit-python, en Python. Il a été développé à la bibliothèque du Congrès, un gros utilisateur et promoteur de BagIt. La documentation est simple et lisible. On installe d'abord :
% pip3 install bagit Collecting bagit Downloading https://files.pythonhosted.org/packages/ee/11/7a7fa81c0d43fb4d449d418eba57fc6c77959754c5c2259a215152810555/bagit-1.7.0.tar.gz Building wheels for collected packages: bagit Running setup.py bdist_wheel for bagit ... done Stored in directory: /home/bortzmeyer/.cache/pip/wheels/8d/77/f7/8f91043ef3c99bbab558f578d19ce5938896e37e57609f9786 Successfully built bagit Installing collected packages: bagit Successfully installed bagit-1.7.0
On peut ensuite utiliser cette bibliothèque depuis Python :
% python3
Python 3.5.3 (default, Sep 27 2018, 17:25:39)
[GCC 6.3.0 20170516] on linux
Type "help", "copyright", "credits" or "license" for more information.
>>> import bagit
>>> bag = bagit.make_bag('/tmp/toto', {'Contact-Name': 'Ed Summers'})
>>>
Le répertoire /tmp/toto aura été transformé en
sac.
Cette bibliothèque vient aussi avec un outil en ligne de commande. J'ai créé le premier sac d'exemple de cet article avec :
% bagit.py --contact-name 'Stéphane Bortzmeyer' --contact-email 'stephane+atlas@bortzmeyer.org' \
/tmp/RIPE-Atlas-Bolivia
Et ce même outil permet de vérifier qu'un sac est valide :
% bagit.py --validate /tmp/RIPE-Atlas-Bolivia
2018-12-20 16:16:09,700 - INFO - Verifying checksum for file /tmp/RIPE-Atlas-Bolivia/data/bortzmeyer-ripe-atlas-lapaz.tex
2018-12-20 16:16:09,700 - INFO - Verifying checksum for file /tmp/RIPE-Atlas-Bolivia/data/Makefile
2018-12-20 16:16:09,701 - INFO - Verifying checksum for file /tmp/RIPE-Atlas-Bolivia/manifest-sha256.txt
2018-12-20 16:16:09,701 - INFO - Verifying checksum for file /tmp/RIPE-Atlas-Bolivia/manifest-sha512.txt
2018-12-20 16:16:09,701 - INFO - Verifying checksum for file /tmp/RIPE-Atlas-Bolivia/bagit.txt
2018-12-20 16:16:09,701 - INFO - Verifying checksum for file /tmp/RIPE-Atlas-Bolivia/bag-info.txt
2018-12-20 16:16:09,702 - INFO - /tmp/RIPE-Atlas-Bolivia is valid
Il existe d'autres mises en œuvre comme bagit ou bagins en Go. L'article « Using BagIt in 2018 » donne des informations utiles dans d'autres langages.
L'article seul
Fiche de lecture : En construction
Auteur(s) du livre : Valérie Schafer
Éditeur : INA
9-782869-382534
Publié en 2018
Première rédaction de cet article le 19 décembre 2018
Derrière un titre qui évoque les fameuses mentions « En construction » du début du Web, un ouvrage d'une historienne spécialisée dans l'histoire de l'Internet. Valérie Schafer décrit les débuts de l'Internet et du Web en France, au cours des années 1990.
On y trouve les débats franco-français « Minitel ou Internet », qui agitaient les gens d'en haut de 1994 à 1997 (les gens d'en bas avaient tranché depuis longtemps), les absurdités des intellectuels français face à un phénomène qu'ils ne comprennent pas, l'incompréhension des médias officiels (voir d'ailleurs l'excellente compilation de reportages télévisés faite par l'auteure), l'histoire de Fnet et d'autres acteurs, puis l'explosion de l'intérêt pour l'Internet, passant par les phases successives (on ignore, puis on ricane, puis on en fait des éloges démesurés), les problèmes concrets (kits de connexion, documentations incompréhensibles, compensées par le fait que les utilisateurs étaient des passionné·e·s, décidé·e·s à réussir), les débuts des sites Web (au HTML fait à la main), les relations avec les nouveaux utilisateurs qui arrivent en masse (le septembre sans fin), les premières censures, et les combats pour la liberté, par exemple le rôle de l'AUI, etc.
À propos de documentation, celle de l'accès au
CNAM par modem,
citée p. 55 et suivantes, est en ligne, en trois fichiers : acces-cnam-modems-1.pdf, acces-cnam-modems-2.pdf et acces-cnam-modems-3.pdf.
Question absurdités, le rapport Théry est évidemment mentionné, mais je pense que la prime revient à Philippe Val qui écrivait dans Charlie Hebdo en 2001 (p. 26 du livre) : « Qui est prêt à dépenser de l'argent à fonds perdus pour avoir son petit site personnel ? Des tarés, des maniaques, des fanatiques, des mégalomanes, des paranoïaques, des nazis, des délateurs [...] » Comme vous êtes en train de lire un « petit site personnel », je vous laisse chercher dans quelle(s) catégorie(s) est son auteur…
Les sources sont systématiquement citées, ce qui est normal pour une historienne, mais n'est pas toujours fait dans les livres parlant d'histoire de l'Internet. (Et qui répètent parfois en boucle des légendes, du genre c'est en France qu'on a inventé l'Internet. De telles légendes sont fréquentes dans les « histoires d'Internet », contrairement à ce livre, qui est très rigoureux.) Plus étonnant, des sources informelles sont très utilisées, notamment Usenet. C'est tout à fait justifié, vu le peu de sources formelles sur cette époque, mais c'est rare, Usenet est ignoré de la majorité des ouvrages et articles parlant d'Internet.
Pour ces citations tirées d'Usenet, Schafer n'a pas mis le nom de l'auteur·e de la citation. Le problème est complexe, car il faut arbitrer entre le droit d'auteur (citer l'auteur), la valeur historique du témoignage (qui dépend de qui parle) et le droit à la vie privée. Contrairement à un livre ou à un article dans un journal formel, l'auteur·e d'un message sur Usenet ne pensait pas forcément être retrouvé·e vingt ans après. Si vous voulez approfondir la question, l'auteure du livre recommande « Ethics and the Archived Web Presentation: “The Ethics of Studying GeoCities” » ou « Par-delà la dichotomie public/privé : la mise en visibilité des pratiques numériques et ses enjeux éthiques ».
Le fameux logo « En construction » orne logiquement la
couverture du livre : 
Notez enfin que le site de l'Armada de la Liberté, mentionné p. 73, a été récemment remis en ligne à partir d'une sauvegarde personnelle dans le cadre d'une page d'histoire du CNAM à l'occasion d'une conférence. J'ai appris dans le livre de Valérie Schafer (p. 80) que le site Web du CNAM n'avait pas été le premier serveur Web en France, contrairement à ce que je répétais tout le temps. Heureusement que les historien·ne·s sont là pour vérifier.
Déclaration d'éventuel conflit d'intérêts : j'ai reçu (sans engagement) un exemplaire gratuit de ce livre par l'auteur.
L'article seul
RFC 8483: Yeti DNS Testbed
Date de publication du RFC : Octobre 2018
Auteur(s) du RFC : L. Song (Beijing Internet
Institute), D. Liu (Beijing Internet
Institute), P. Vixie (TISF), A. Kato
(Keio/WIDE), S. Kerr
Pour information
Première rédaction de cet article le 17 décembre 2018
Ce RFC décrit une expérience, celle qui, de mai 2015 à décembre 2018, a consisté à faire tourner une racine DNS alternative nommée Yeti. Contrairement aux racines alternatives commerciales qui ne sont typiquement que des escroqueries visant à vendre à des gogos des TLD reconnus par personne, Yeti était une expérience technique ; il s'agissait de tester un certain nombre de techniques qu'on ne pouvait pas se permettre de tester sur la « vraie » racine.
Parmi ces techniques, l'utilisation d'un grand nombre de
serveurs
racine (pour casser la légende comme quoi l'actuelle
limite à 13 serveurs aurait une justification technique),
n'utiliser qu'IPv6, jouer avec des
paramètres DNSSEC différents, etc. J'ai
participé à ce projet, à la fois comme gérant de deux des serveurs
racine, et comme utilisateur de la racine Yeti, reconfigurant des
résolveurs DNS pour utiliser Yeti. Les deux serveurs racines
dahu1.yeti.eu.org et
dahu2.yeti.eu.org appartenaient au groupe
Dahu, formé par l'AFNIC (cf. cet
article sur le site de l'AFNIC),
Gandi et eu.org. (Le
nom vient d'un animal aussi
mythique que le yéti.)
Outre l'aspect technique, un autre intéret de Yeti était qu'il s'agissait d'un projet international. Réellement international, pas seulement des états-uniens et des européens de divers pays ! Yeti est d'inspiration chinoise, la direction du projet était faite en Chine, aux États-Unis et au Japon, et parmi les équipes les plus impliquées dans le projet, il y avait des Russes, des Indiens, des Français, des Chiliens… Le projet, on l'a dit, était surtout technique (même si certains participants pouvaient avoir des arrière-pensées) et la zone racine servie par Yeti était donc exactement la même que celle de l'IANA, aux noms des serveurs et aux signatures DNSSEC près. Un utilisateur ordinaire de Yeti ne voyait donc aucune différence. Le projet étant de nature expérimentale, les utilisateurs étaient tous des volontaires, conscients des risques possibles (il y a eu deux ou trois cafouillages).
L'annexe E du RFC est consacrée aux controverses sur le principe même du projet Yeti. Le projet a toujours été discuté en public, et présenté à de nombreuses réunions. Mais il y a toujours des râleurs, affirmant par exemple que ce projet était une racine alternative (ce qui n'est pas faux mais attendez, lisez jusqu'au bout) et qu'il violait donc le RFC 2826. Outre que ce RFC 2826 est très contestable, il faut noter qu'il ne s'applique pas à Yeti ; il concerne uniquement les racines alternatives servant un contenu différent de celui de la racine « officielle » alors que Yeti a toujours été prévu et annoncé comme servant exactement la même racine (comme le faisait ORSN). Rien à voir donc avec ces racines alternatives qui vous vendent des TLD bidons, que personne ne pourra utiliser. Comme le disait Paul Vixie, Yeti pratique le Responsible Alternate Rootism. Notez quand même que certains participants à Yeti (notamment en Chine et en Inde) avaient des objectifs qui n'étaient pas purement techniques (s'insérant dans le problème de la gouvernance Internet, et plus spécialement celle de la racine).
La racine du DNS est quelque chose d'absolument critique pour le bon fonctionnement de l'Internet. Quasiment toutes les activités sur l'Internet démarrent par une ou plusieurs requêtes DNS. S'il n'y a plus de résolution DNS, c'est à peu près comme s'il n'y avait plus d'Internet (même si quelques services pair-à-pair, comme Bitcoin, peuvent encore fonctionner). Du fait de la nature arborescente du DNS, si la racine a un problème, le service est sérieusement dégradé (mais pas arrêté, notamment en raison des mémoires - les « caches » - des résolveurs). On ne peut donc pas jouer avec la racine, par exemple en essayant des idées trop nouvelles et peu testées. Cela n'a pas empêché la racine de changer beaucoup : il y a eu par exemple le déploiement massif de l'anycast, qui semblait inimaginable il y a dix-sept ans, le déploiement de DNSSEC (avec le récent changement de clé, qui s'est bien passé), ou celui d'IPv6, plus ancien. Le fonctionnement de la racine était traditionnellement peu ou pas documenté mais il y a quand même eu quelques documents utiles, comme le RFC 7720, la première description de l'anycast, ou les documents du RSSAC, comme RSSAC 001. Celle ou celui qui veut se renseigner sur la racine a donc des choses à lire.
Mais le point important est que la racine est un système en production, avec lequel on ne peut pas expérimenter à loisir. D'où l'idée, portée notamment par BII, mais aussi par TISF et WIDE, d'une racine alternative n'ayant pas les contraintes de la « vraie » racine. Yeti (section 1 du RFC) n'est pas un projet habituel, avec création d'un consortium, longues réunions sur les statuts, et majorité du temps passé en recherches de financement. C'est un projet léger, indépendant d'organismes comme l'ICANN, géré par des volontaires, sans structure formelle et sans budget central, dans la meilleure tradition des grands projets Internet. À son maximum, Yeti a eu 25 serveurs racine, gérés par 16 organisations différentes.
Au passage, puisqu'on parle d'un projet international, il faut noter que ce RFC a été sérieusement ralenti par des problèmes de langue. Eh oui, tout le monde n'est pas anglophone et devoir rédiger un RFC en anglais handicape sérieusement, par exemple, les Chinois.
Parmi les idées testées sur Yeti (section 3 du RFC) :
- Une racine alternative qui marche (avec supervision sérieuse ; beaucoup de services se présentant comme « racine alternative » ont régulièrement la moitié de leurs serveurs racine en panne),
- Diverses méthodes pour signer et distribuer la zone racine,
- Schémas de nommage pour les serveurs racine (dans la
racine IANA, tous les serveurs sont sous
root-servers.net), - Signer les zones des serveurs racine (actcuellement,
root-servers.netn'est pas signé), - Utiliser exclusivement IPv6,
- Effectuer des remplacements de clé (notamment en comptant sur le RFC 5011),
- Sans compter les autres idées décrites dans cette section 3 du RFC mais qui n'ont pas pu être testées.
La section 4 du RFC décrit l'infrastructure de Yeti. Elle a
évidemment changé plusieurs fois, ce qui est normal pour un
service voué aux expérimentations. Yeti utilise l'architecture
classique du DNS. Les serveurs racine sont remplacés par ceux de
Yeti, les autres serveurs faisant autorité (ceux de
.fr ou
.org, par exemple) ne
sont pas touchés. Les résolveurs doivent évidemment être
reconfigurés pour utiliser Yeti (d'une manière qui est documentée sur le site Web du projet). Au
démarrage, un résolveur ne connait en effet que la liste des noms
et adresses IP des serveurs de la racine. La racine « officielle »
est configurée par défaut et doit ici être remplacée (annexe A du RFC). Il faut
aussi changer la clé de la racine (la root trust
anchor) puisque Yeti signe avec sa propre clé.
Voici la configuration de mon résolveur à la maison, avec Knot sur une Turris Omnia :
config resolver 'common'
option keyfile '/etc/kresd/yeti-root.keys'
option prefered_resolver 'kresd'
config resolver 'kresd'
option rundir '/tmp/kresd'
option log_stderr '1'
option log_stdout '1'
option forks '1'
option include_config '/etc/kresd/custom.conf'
et custom.conf contient la liste des serveurs
racine :
hints.root({
['bii.dns-lab.net.'] = '240c:f:1:22::6',
['yeti-ns.tisf.net .'] = '2001:4f8:3:1006::1:4',
['yeti-ns.wide.ad.jp.'] = '2001:200:1d9::35',
['yeti-ns.as59715.net.'] = '2a02:cdc5:9715:0:185:5:203:53',
['dahu1.yeti.eu.org.'] = '2001:4b98:dc2:45:216:3eff:fe4b:8c5b',
['ns-yeti.bondis.org.'] = '2a02:2810:0:405::250',
['yeti-ns.ix.ru .'] = '2001:6d0:6d06::53',
['yeti.bofh.priv.at.'] = '2a01:4f8:161:6106:1::10',
['yeti.ipv6.ernet.in.'] = '2001:e30:1c1e:1::333',
['yeti-dns01.dnsworkshop.org.'] = '2001:1608:10:167:32e::53',
['yeti-ns.conit.co.'] = '2604:6600:2000:11::4854:a010',
['dahu2.yeti.eu.org.'] = '2001:67c:217c:6::2',
['yeti.aquaray.com.'] = '2a02:ec0:200::1',
['yeti-ns.switch.ch.'] = '2001:620:0:ff::29',
['yeti-ns.lab.nic.cl.'] = '2001:1398:1:21::8001',
['yeti-ns1.dns-lab.net.'] = '2001:da8:a3:a027::6',
['yeti-ns2.dns-lab.net.'] = '2001:da8:268:4200::6',
['yeti-ns3.dns-lab.net.'] = '2400:a980:30ff::6',
['ca978112ca1bbdcafac231b39a23dc.yeti-dns.net.'] = '2c0f:f530::6',
['yeti-ns.datev.net.'] = '2a00:e50:f15c:1000::1:53',
['3f79bb7b435b05321651daefd374cd.yeti-dns.net.'] = '2401:c900:1401:3b:c::6',
['xn--r2bi1c.xn--h2bv6c0a.xn--h2brj9c.'] = '2001:e30:1c1e:10::333',
['yeti1.ipv6.ernet.in.'] = '2001:e30:187d::333',
['yeti-dns02.dnsworkshop.org.'] = '2001:19f0:0:1133::53',
['yeti.mind-dns.nl.'] = '2a02:990:100:b01::53:0'
})
Au bureau, avec Unbound, cela donnait :
server:
auto-trust-anchor-file: "/var/lib/unbound/yeti.key"
root-hints: "yeti-hints"
Et yeti-hints est disponible en
annexe A du RFC (attention, comme le note la section 7 du RFC, à
utiliser une source fiable, et à le récupérer de manière sécurisée).
Comme Yeti s'est engagé à ne pas modifier le contenu de la zone racine (liste des TLD, et serveurs de noms de ceux-ci), et comme Yeti visait à gérer la racine de manière moins concentrée, avec trois organisations (BII, TISF et WIDE) signant et distribuant la racine, le mécanisme adopté a été :
- Les trois organisations copient la zone racine « normale »,
- En retirent les clés et les signatures DNSSEC et la liste des serveurs de la racine,
- Modifient le SOA,
- Ajoutent la liste des serveurs Yeti, les clés Yeti, et signent la zone,
- Les serveurs racine copient automatiquement cette nouvelle zone signée depuis un des trois DM (Distribution Master, section 4.1 du RFC).
Voici le SOA Yeti :
% dig SOA .
...
;; ->>HEADER<<- opcode: QUERY, status: NOERROR, id: 45919
;; flags: qr rd ra ad; QUERY: 1, ANSWER: 2, AUTHORITY: 0, ADDITIONAL: 1
...
;; ANSWER SECTION:
. 86400 IN SOA www.yeti-dns.org. bii.yeti-dns.org. (
2018121600 ; serial
1800 ; refresh (30 minutes)
900 ; retry (15 minutes)
604800 ; expire (1 week)
86400 ; minimum (1 day)
)
. 86400 IN RRSIG SOA 8 0 86400 (
20181223050259 20181216050259 46038 .
BNoxqfGq5+rBEdY4rdp8W6ckNK/GAOtBWQ3P36YFq5N+
...
;; Query time: 44 msec
;; SERVER: 127.0.0.1#53(127.0.0.1)
;; WHEN: Sun Dec 16 16:01:27 CET 2018
;; MSG SIZE rcvd: 369
(Notez que l'adresse du responsable de la zone indique le
DM qui a été utilisé par ce résolveur particulier. Un autre
résolveur pourrait montrer un autre SOA, si le DM était différent.)
Comme les serveurs racine « officiels » n'envoient pas de message
NOTIFY (RFC 1996) aux
serveurs Yeti, la seule solution est d'interroger régulièrement
ces serveurs officiels. (Cela fait que Yeti sera toujours un peu
en retard sur la racine « officielle », cf. section 5.2.2.) Plusieurs de ces serveurs acceptent le
transfert de zone (RFC 5936), par exemple
k.root-servers.net :
% dig @k.root-servers.net AXFR . > /tmp/root.zone
% head -n 25 /tmp/root.zone
; <<>> DiG 9.11.3-1ubuntu1.3-Ubuntu <<>> @k.root-servers.net AXFR .
; (2 servers found)
;; global options: +cmd
. 86400 IN SOA a.root-servers.net. nstld.verisign-grs.com. (
2018121600 ; serial
1800 ; refresh (30 minutes)
900 ; retry (15 minutes)
604800 ; expire (1 week)
86400 ; minimum (1 day)
)
. 172800 IN DNSKEY 256 3 8 (
AwEAAdp440E6Mz7c+Vl4sPd0lTv2Qnc85dTW64j0RDD7
...
De son côté, l'ICANN gère deux machines qui
acceptent le transfert de zone,
xfr.cjr.dns.icann.org et
xfr.lax.dns.icann.org. On peut enfin
récupérer cette zone par FTP.
Pour l'étape de signature de la zone, Yeti a testé plusieurs façons de répartir le travail entre les trois DM (Distribution Masters) :
- Clés (KSK et ZSK) partagées entre tous les DM. Cela nécessitait donc de transmettre les clés privées.
- KSK unique mais une ZSK différente par DM (chacune étant signée par la KSK). Chacun garde alors la clé privée de sa ZSK. (Voir la section 5.2.3 pour quelques conséquences pratiques de cette configuration.)
Dans les deux cas, Yeti supprime la totalité des signatures de la racine « officielle » avant d'apposer la sienne. Il a été suggéré (mais pas testé) d'essayer d'en conserver une partie, pour faciliter la vérification du fait que Yeti n'avait pas ajouté ou retiré de TLD.
La configuration chez les DM et leur usage de git (les risques de sécurité que cela pose sont discutés en section 7) pour se synchroniser quand c'est nécessaire est documentée ici.
Les serveurs racine de Yeti n'ont plus ensuite qu'à récupérer la zone depuis un des DM ; chaque serveur racine peut utiliser n'importe quel DM et en changer, de façon à éviter de dépendre du bon fonctionnement d'un DM particulier. Voici par exemple la configuration d'un serveur NSD :
server:
ip-address: 2001:4b98:dc2:45:216:3eff:fe4b:8c5b
nsid: "ascii_dahu1.yeti.eu.org"
# RFC 8201
ipv6-edns-size: 1460
zone:
name: "."
outgoing-interface: 2001:4b98:dc2:45:216:3eff:fe4b:8c5b
# We use AXFR (not the default, IXFR) because of http://open.nlnetlabs.nl/pipermail/nsd-users/2016-February/002243.html
# BII
request-xfr: AXFR 240c:f:1:22::7 NOKEY
allow-notify: 240c:f:1:22::7 NOKEY
# TISF
request-xfr: AXFR 2001:4f8:3:1006::1:5 NOKEY
allow-notify: 2001:4f8:3:1006::1:5 NOKEY
# WIDE
request-xfr: AXFR 2001:200:1d9::53 NOKEY
allow-notify: 2001:200:1d9::53 NOKEY
Notez que la configuration réseau était un peu plus complexe, la
machine ayant deux interfaces, une de service, pour les requêtes
DNS, et une d'aministration, pour se connecter via
ssh. Il fallait s'assurer que les messages
DNS partent bien par la bonne interface réseau, donc faire du
routage selon l'adresse IP source. Le fichier de configuration
Linux pour cela est yeti-network-setup.sh
Contrairement aux serveurs de la racine « officielle », qui
sont tous sous le domaine root-servers.net,
ceux de Yeti, ont des noms variés. Le suffixe identique permet,
grâce à la compression des noms (RFC 1035,
section 4.1.4 et RSSAC
023)
de gagner quelques octets sur la taille des messages DNS. Yeti
cherchant au contraire à tester la faisabilité de messages DNS
plus grands, cette optimisation n'était pas utile.
Une des conséquences est que la réponse initiale à un résolveur (RFC 8109) est assez grande :
% dig @bii.dns-lab.net. NS .
...
;; SERVER: 240c:f:1:22::6#53(240c:f:1:22::6)
;; MSG SIZE rcvd: 1591
On voit qu'elle dépasse la MTU
d'Ethernet. Certains serveurs, pour
réduire la taille de cette réponse, n'indiquent pas la totalité
des adresses IP des serveurs racine (la colle) dans la
réponse. (BIND, avec
minimum-responses: yes n'envoie même aucune
adresse IP, forçant le résolveur à effectuer des requêtes pour les
adresses IP des serveurs). Cela peut augmenter la latence avant
les premières résolutions réussies, et diminuer la robustesse (si
les serveurs dont l'adresse est envoyée sont justement ceux en
panne). Mais cela n'empêche pas le DNS de fonctionner et Yeti,
après discussion, a décidé de ne pas chercher à uniformiser les
réponses des serveurs racine.
Au moment de la publication du RFC, Yeti avait 25 serveurs racine gérés dans 16 pays différents (section 4.6 du RFC), ici vus par check-soa (rappelez-vous qu'ils n'ont que des adresses IPv6) :
% check-soa -i .
3f79bb7b435b05321651daefd374cd.yeti-dns.net.
2401:c900:1401:3b:c::6: OK: 2018121400 (334 ms)
bii.dns-lab.net.
240c:f:1:22::6: OK: 2018121400 (239 ms)
ca978112ca1bbdcafac231b39a23dc.yeti-dns.net.
2c0f:f530::6: OK: 2018121400 (170 ms)
dahu1.yeti.eu.org.
2001:4b98:dc2:45:216:3eff:fe4b:8c5b: OK: 2018121400 (18 ms)
dahu2.yeti.eu.org.
2001:67c:217c:6::2: OK: 2018121400 (3 ms)
ns-yeti.bondis.org.
2a02:2810:0:405::250: OK: 2018121400 (24 ms)
xn--r2bi1c.xn--h2bv6c0a.xn--h2brj9c.
2001:e30:1c1e:10::333: OK: 2018121400 (188 ms)
yeti-ns.as59715.net.
2a02:cdc5:9715:0:185:5:203:53: OK: 2018121400 (43 ms)
yeti-ns.datev.net.
2a00:e50:f155:e::1:53: OK: 2018121400 (19 ms)
yeti-ns.ix.ru.
2001:6d0:6d06::53: OK: 2018121400 (54 ms)
yeti-ns.lab.nic.cl.
2001:1398:1:21::8001: OK: 2018121400 (228 ms)
yeti-ns.switch.ch.
2001:620:0:ff::29: OK: 2018121400 (16 ms)
yeti-ns.tisf.net.
2001:4f8:3:1006::1:4: OK: 2018121400 (175 ms)
yeti-ns.wide.ad.jp.
2001:200:1d9::35: OK: 2018121400 (258 ms)
yeti-ns1.dns-lab.net.
2400:a980:60ff:7::2: OK: 2018121400 (258 ms)
yeti-ns2.dns-lab.net.
2001:da8:268:4200::6: OK: 2018121400 (261 ms)
yeti-ns3.dns-lab.net.
2400:a980:30ff::6: OK: 2018121400 (268 ms)
yeti.aquaray.com.
2a02:ec0:200::1: OK: 2018121400 (4 ms)
yeti.bofh.priv.at.
2a01:4f8:161:6106:1::10: OK: 2018121400 (31 ms)
yeti.ipv6.ernet.in.
2001:e30:1c1e:1::333: OK: 2018121400 (182 ms)
yeti.jhcloos.net.
2001:19f0:5401:1c3::53: OK: 2018121400 (108 ms)
yeti.mind-dns.nl.
2a02:990:100:b01::53:0: OK: 2018121400 (33 ms)
Notez que l'un d'eux a un nom IDN,
मूल.येती.भारत (affiché par
check-soa comme
xn--r2bi1c.xn--h2bv6c0a.xn--h2brj9c). 18 des
serveurs sont des VPS, le reste étant des
machines physiques. 15 utilisent le noyau
Linux, 4 FreeBSD, 1
NetBSD et 1 (oui, oui) tourne sur
Windows. Question logiciel, 16 utilisent
BIND, 4 NSD, 2
Knot, 1 Bundy
(l'ex-BIND 10), 1 PowerDNS et 1
Microsoft DNS.
Pour tester que la racine Yeti fonctionnait vraiment, il ne suffisait évidemment pas de faire quelques dig, check-soa et tests avec les sondes RIPE Atlas. Il fallait un trafic plus réaliste. Certains résolveurs (dont les miens, à la maison et au bureau) ont été configurés pour utiliser la racine Yeti et fournissaient donc un trafic réel, quoique faible. En raison des caches des résolveurs, le trafic réel ne représentait que quelques dizaines de requêtes par seconde. Il était difficile d'augmenter ce nombre, Yeti étant une racine expérimentale, où des choses risquées étaient tentées, on ne pouvait pas utiliser des résolveurs de production. Il a donc fallu aussi injecter du trafic artificiel.
Tout le trafic atteignant les serveurs racines Yeti était capturé (c'est une autre raison pour laquelle on ne pouvait pas utiliser les résolveurs de production ; Yeti voyait toutes leurs requêtes à la racine) et étudié. Pour la capture, des outils comme dnscap ou pcapdump (avec un petit patch) étaient utilisés pour produire des pcap, ensuite copiés vers BII avec rsync.
La section 5 du RFC décrit les problèmes opérationnels qu'a
connu Yeti. Si vous voulez tous les détails, vous pouvez regarder
les
archives de la liste de diffusion du projet, et le blog du
projet. D'abord, ce qui concerne
IPv6. Comme d'habitude, des ennuis sont
survenus avec la fragmentation. En raison
du nombre de serveurs racine, et de l'absence de schéma de nommage
permettant la compression, les réponses Yeti sont souvent assez
grandes pour devoir être fragmentées (1 754 octets avec toutes les
adresses des serveurs racine, et 1 975 avec le mode « une ZSK par
DM »). Cela ne serait pas un problème (la fragmentation des
datagrammes étant spécifiée dans
IPv4 et IPv6 depuis
le début) si tout le monde configurait son réseau
correctement. Hélas, beaucoup d'incompétents et de maladroits ont
configuré leurs systèmes pour bloquer les fragments IP, ou pour
bloquer les messages ICMP nécessaires à la
découverte de la MTU du chemin (RFC 8201). Ce triste état des choses a été décrit dans le
RFC 7872, dans draft-taylor-v6ops-fragdrop, et dans
« Dealing
with IPv6 fragmentation in the DNS ». Il a même
été proposé de ne jamais
envoyer de datagrammes de taille supérieure à 1 280
octets.
En pratique, le meilleur contournement de ce problème est de réduire la taille maximale des réponses EDNS. Par exemple, dans NSD :
ipv6-edns-size: 1460
Les réponses resteront à moins de 1 460 octets et ne seront donc en général pas fragmentées.
Les transferts de zone depuis les DM ont levé quelques
problèmes. Les zones sont légèrement différentes d'un DM à l'autre
(SOA et surtout signatures). Les transferts de zone
incrémentaux (IXFR, RFC 1995), ne peuvent
donc pas être utilisés : si un serveur racine interroge un DM,
puis un autre, les résultats seront incompatibles. Ce cas, très
spécifique à Yeti, n'est pas pris en compte par les logiciels. Les serveurs
doivent donc utiliser le transfert complet (AXFR) uniquement (d'où
le AXFR dans la configuration du serveur
racine NSD vue plus haut). Ce
n'est pas très grave, vu la petite taille de la zone racine.
Lors des essais de remplacement de la KSK (on sait que, depuis
la parution de ce RFC, la KSK
de la racine « officielle » a été successivement
remplacée le 11 octobre 2018) quelques problèmes sont
survenus. Par exemple, la documentation de BIND n'indiquait pas,
lorsque le résolveur utilise l'option
managed-keys, que celle-ci doit être configurée
dans toutes les vues. (Au passage, j'ai toujours trouvé que les vues sont
un système compliqué et menant à des erreurs déroutantes.)
La capture du trafic DNS avec les serveurs racine Yeti a
entrainé d'autres problèmes (section 5.4 du RFC). Il existe
plusieurs façons d'enregistrer le trafic d'un serveur de noms, de
la plus courante (tcpdump avec l'option
-w) à la plus précise
(dnstap). dnstap étant encore peu répandu
sur les serveurs de noms, Yeti a utilisé une capture « brute » des
paquets, dans des fichiers pcap qu'il
fallait ensuite analyser. L'un des problèmes avec les fichiers
pcap est qu'une connexion TCP, même d'une seule requête, va se
retrouver sur plusieurs paquets, pas forcément consécutifs. Il
faudra donc réassembler ces connexions TCP, par exemple avec un
outil développé pour Yeti, PcapParser
(décrit plus longuement dans l'annexe D de notre RFC).
Les serveurs racine changent de temps en temps. Dans la racine
« officielle », les changements des noms sont très rares. En
effet, pour des raisons politiques, on ne peut pas modifier la
liste des organisations qui gèrent un serveur racine. Vouloir
ajouter ou retirer une organisation déclencherait une crise du
genre « pourquoi lui ? ». L'ICANN est donc
paralysée sur ce point. Mais les serveurs changent parfois
d'adresse IP. C'est rare, mais ça arrive. Si les résolveurs ne
changent pas leur configuration, ils auront une liste
incorrecte. Un exemple de la lenteur avec laquelle se diffusent
les changements d'adresses IP des serveurs racine est le cas de
j.root-servers.net qui, treize
ans après son changement d'adresse IP, continue
à recevoir du trafic à l'ancienne adresse. Ceci dit, ce
n'est pas très grave en pratique, car, à l'initialisation du
résolveur (RFC 8109), le résolveur reçoit du
serveur racine consulté une liste à jour. Tant que la liste qui
est dans la configuration du résolveur ne dévie pas trop de la
vraie liste, il n'y a pas de problème, le résolveur finira par
obtenir une liste correcte.
Mais Yeti est différent : les changements sont beaucoup plus
fréquents et, avec eux, le risque que la liste connue par les
résolveurs dévie trop. D'où la création d'un outil spécial, hintUpdate
(personnellement, je ne l'ai jamais utilisé, je modifie la
configuration du résolveur, c'est tout). Un point intéressant
d'hintUpdate est qu'il dépend de DNSSEC
pour vérifier les informations reçues. Cela marche avec Yeti, où
les noms des serveurs racine sont (théoriquement) signés, mais cela ne
marcherait pas avec la racine officielle,
root-servers.net n'étant pas signé.
Dernier problème, et rigolo, celui-ci, la compression inutile. En utilisant le logiciel Knot pour un serveur racine, nous nous sommes aperçus qu'il comprimait même le nom de la zone racine, faisant passer sa taille de un à deux octets. Une compression négative donc, légale mais inutile. À noter que cela plantait la bibliothèque Go DNS. Depuis, cette bibliothèque a été rendue plus robuste, et Knot a corrigé cette optimisation ratée.
La conclusion du RFC, en section 6, rappelle l'importance de disposer de bancs de test, puisqu'on ne peut pas faire courir de risques à la racine de production. La conclusion s'achève en proposant de chercher des moyens de rendre le DNS moins dépendant de la racine actuelle. Et, vu la mode actuelle, le mot de chaîne de blocs est même prononcé…
L'article seul
APIdays et mon exposé sur Internet et les droits humains
Première rédaction de cet article le 13 décembre 2018
Dernière mise à jour le 31 mars 2019
Les 11 et 12 décembre 2018, à Paris (enfin, à Montrouge), s'est tenue une édition des API Days, conférence consacrée aux API. J'y ai parlé (en anglais) d'Internet et de ses rapports avec les droits humains.
Globalement, API days verse un peu trop dans le techno-optimisme et la cyber-béatitude : les API vont sauver le monde, la société va devenir « programmable », l'Estonie est le modèle (comme l'était l'URSS pour les communistes, l'Estonie est toujours présentée comme modèle par les startupeurs et les partisans du E-nimportequoi). Les orateurs sont heureux, actifs, ont des titres rigolos (API evangelist…), ont un sourire de publicité pour dentifrice, et répètent en boucle que tout est amazing.
Heureusement, il y a quelques séances moins consensuelles. J'ai particulièrement apprécié la keynote de fin par Jean-Marc Jancovici, sur l'énergie et le climat. Jancovici est un remarquable conférencier, très amateur de petites phrases qui claquent, et illustre son exposé de nombreux chiffres et diagrammes. Il a démoli l'idée qu'on pourrait éviter ou limiter le changement climatique avec juste quelques mesurettes, comme aiment annoncer certaines entreprises du secteur de l'informatique. Notre dépendance aux énergies fossiles, et à des matériaux rares comme l'indium est profondément enracinée et changer les choses va nécessiter des sacrifices douloureux (l'alternative étant une crise climatique grave, avec guerres, on voit que le conférencier était un optimiste). Les machines sont tellement utiles et tellement puissantes, qu'à part des mesures brutales et immorales, comme de rétablir l'esclavage (et encore : les esclaves sont beaucoup moins productifs que les machines), la limitation du réchauffement planétaire va être difficile. (L'orateur ne croit pas aux énergies renouvelables, très insuffisantes par rapport à la demande. Elles sont réalistes - après tout, l'humanité a vécu pendant la plus grande partie de l'histoire en ne consommant que des ressources renouvelables - mais pas adaptées à notre mode de vie.)
Jancovici a aussi démoli la théorie cyber-optimiste comme quoi l'informatique pourrait aider à lutter contre le changement climatique, par exemple par une meilleure allocation des ressources. C'est le contraire qui est vrai : l'informatique, outre sa consommation propre, qui n'est pas nulle, permet une plus grande consommation de ressources non-renouvelables. Ainsi, en permettant un trafic aérien intense, elle contribue à un secteur, le transport, qui est un des plus gros responsables de l'émission de gaz à effet de serre. Jancovici a estimé qu'au contraire, il allait falloir réduire les usages, changer moins souvent d'ordiphone, et ne pas déployer certaines technologies gaspilleuses comme la 5G.
Mon exposé était nettement plus banal, il portait sur les rapports entre l'Internet et les droits humains. Les supports sont en anglais. Voici la version PDF, et le source en LaTeX. Tout a été filmé et est disponible sur le site Web d'API days et sur YouTube.
L'article seul
Détails techniques sur l'écriture de mon livre « Cyberstructure »
Première rédaction de cet article le 12 décembre 2018
Comme vous avez pu le voir dans un autre article, j'ai écrit un livre nommé « Cyberstructure » et qui parle des relations entre l'architecture technique de l'Internet et les questions politiques. Ce nouvel article est destiné uniquement aux détails techniques de l'écriture, pour ceux et celles qui se demandent « tu as utilisé quel logiciel pour faire ce livre ? ». Je ne parlerai donc pas ici du contenu du livre.
D'abord, pour les outils utilisés, il faut bien voir que l'auteur n'a pas une liberté complète puisqu'un livre est un travail collectif. Il faut donc une discussion avec l'éditeur, du moins si, comme moi, on a un éditeur qui se penche sur le texte, au lieu de demander à l'auteur des images qu'on imprimera telles quelles. D'autre part, dans mon cas, la mise en page était faite par l'éditeur (avec InDesign), donc je n'avais pas à me soucier du rendu, je pouvais me concentrer sur le texte. Enfin, certains choix ne concernaient que moi, puisqu'ils ne changeaient rien à ce qui était échangé avec l'éditeur.
Les choix importants, après cette discussion, étaient :
Pourquoi ces choix ? Commençons par le format XML. C'est un format simple pour l'auteur, bien adapté au texte (contrairement à JSON) grâce notamment à la possibilité de mélanger élements structurés et texte, comme par exemple :
<p>L'ARJEL, l'autorité de régulation des jeux en ligne, a été, sauf erreur, la première autorité ayant ce droit de censurer, sur la base du décret <cite url="https://www.legifrance.gouv.fr/eli/decret/2011/12/30/BCRB1120950D/jo/texte">n° 2011-2122 du 30 décembre 2011 relatif aux modalités d'arrêt de l'accès à une activité d'offre de paris ou de jeux d'argent et de hasard en ligne non autorisée</cite>. [...] C'est ainsi que des sites distribuant des fichiers « torrent » <ref target="bittorrent">pour une explication</ref> comme The Pirate Bay ou T411 ont fait l'objet de décisions de justice imposant leur blocage.</p>
Et, contrairement à JSON, on peut y mettre des commentaires, ce qui aide beaucoup l'auteur au long des mois de réécriture et de modifications. La discussion avec l'éditeur a permis de s'assurer qu'InDesign pouvait importer du XML sans mal, et le choix de XML a donc été en partie guidé par l'éditeur. (Par exemple, il n'y avait pas de moyen simple d'importer du LaTeX. LaTeX repose sur un langage de programmation complet, qui est donc difficile à importer, sauf à utiliser le moteur TeX. XML, au contraire, ce ne sont que des données, sans programme.)
La mise en page étant faite par l'éditeur, il était important
que je me limite au marquage sémantique. Par exemple
<p>Le RFC 7962, <work xml:lang="en"
url="https://www.rfc-editor.org/info/rfc7962">Alternative
Network Deployments: Taxonomy, Characterization, Technologies, and
Architectures</work>, sans préjuger de comment
serait rendu le titre du document cité : on indique que c'est un
titre, on indique la langue, et la personne qui fera la mise en
page pourra suivre les bonnes pratiques de la mise en page,
indépendamment du contenu. Les éléments XML possibles et leurs
relations sont mises dans un schéma, écrit en Relax
NG. Ce schéma est conçu uniquement pour ce livre, et je
n'ai pas cherché à le faire beau ou propre ou général. Si vous
voulez le voir, il est dans le fichier livre.rnc. Je teste la conformité du texte au schéma avec
rnv :
% rnv livre.rnc livre-noent.xml
%
Un autre avantage de XML par rapport à LaTeX, dans ce contexte,
est qu'il est facile de développer des outils traitant le XML et
effectuant certaines opérations. Par exemple, j'ai fait un
programme XSLT pour n'extraire que le texte
du livre, afin de compter caractères et mots. En revanche, LaTeX
est certainement imbattable quand il faut faire une jolie sortie
PDF ou papier sans trop y passer de
temps. Et la plupart des relecteurs, à commencer par moi, ont
préféré travailler sur cette sortie que sur le source XML. Pas de
difficulté, encore un autre programme XSLT, pour convertir le XML
en LaTeX, qui était ensuite traité. Voici ce programme : tolatex.xsl, mais rappelez-vous que ce n'est pas lui qui a
été utilisé pour le rendu final du livre. (Pour faire tourner ce
programme XSLT, j'ai utilisé xsltproc, dans
la
libxslt. Au passage, certains des
outils étaient d'usage compliqué donc j'ai utilisé le classique
make pour orchestrer leur exécution.)
Notez que les techniques utilisée pour le livre étaient assez proches, voire identiques, à celles de mon blog ce qui n'est évidemment pas un hasard. Les techniques du blog sont déjà documentées.
Apparemment, la plupart des auteurs de livres utilisent plutôt un gros cliquodrome comme Word ou LibreOffice. Mais je n'aime pas ces logiciels (j'avais déjà critiqué leur approche afterword il y a plus de dix-sept ans.)
Le XML a l'avantage, comme JSON ou LaTeX, d'être un format texte, donc qui peut être traité avec tous les outils existants. C'est par exemple le cas du choix de l'éditeur (l'éditeur de textes, pas l'éditeur du livre). Pas besoin de concertation, cette fois, ce choix de l'éditeur de textes est purement local et n'affecte pas ce qui est envoyé à l'éditeur du livre. J'ai donc utilisé mon éditeur préféré, emacs. On peut écrire du XML avec le mode de base d'Emacs mais ce n'est pas très amusant (taper le début de l'élement XML, sa fin, penser à bien fermer tout ce qui a été ouvert), il vaut donc mieux utiliser un mode Emacs adapté au XML. J'ai utilisé nxml-mode. À part le fait qu'il économise du temps de frappe, et qu'il affiche le source XML proprement coloré (les noms des éléments en bleu, les commentaires en rouge, pour les distinguer du texte), le gros avantage de nxml-mode est qu'il connait Relax NG, et qu'une fois configuré pour utiliser mon schéma, il peut guider l'écriture, indiquant quels sont les éléments XML acceptables à l'endroit où se trouve le curseur, et validant le résultat au fur et à mesure. Grâce à cela, la validation XML complète, faite avec rnv, était quasiment inutile.
Le schéma XML que j'avais fait me semblait raisonnable, avec un
usage intelligent des éléments et des attributs XML (un sujet toujours
passionnel dans le monde XML). Mais lors de l'importation dans InDesign, un
problème est apparu : sauf exception, InDesign
ne permet pas de mettre du contenu dans les attributs. Il a donc fallu transformer plusieurs attributs en éléments,
avec le programme XSL toindesign.xsl.
Contrairement à mon blog, où certains articles ont été écrits d'une seule traite, ce livre a fait l'objet de retours, de révisions, de critiques et de remords. Il a donc fallu le modifier plusieurs fois, et parfois remettre en place des paragraphes que j'avais effacé quelques jours plus tôt. L'outil idéal pour cela est évidemment le VCS. Comme VCS, j'ai choisi darcs. Il est moins connu que git mais bien plus facile à utiliser. Il ne fournit pas de mécanisme de coopération pratique, mais ce n'est pas grave ici, puisque j'étais seul à travailler sur le texte. Le reproche que j'ai le plus entendu sur darcs est qu'il n'a pas le concept de branches. Cela me parait plutôt un avantage : d'abord, les branches sont très compliquées à utiliser, et ensuite un VCS décentralisé, comme git ou darcs, n'a pas vraiment besoin de branches : il suffit de faire des dépôts différents.
Comme tous les VCS, darcs permet de voir l'historique d'un travail :
patch f1c1609a11c27b0a125057f3afe0e91d537f1fdb Author: stephane@sources.org Date: Sun Dec 10 17:54:48 CET 2017 * Traduction en XML de plan, avant-propos et middleboxes, rédaction de utilisateurs patch 28b1ff5fef2d627f662d41cabda249bb585fec69 Author: stephane@sources.org Date: Sun Dec 10 12:20:17 CET 2017 * Début de la version XML patch 7e38de35163eccb6365502ec0ad189dcd3af5446 Author: stephane@sources.org Date: Wed Nov 29 10:16:05 CET 2017 * Questions à l'éditeur patch 67e7a11537ccc3d5d0b02d4bf83a3ae051bca25d Author: stephane@sources.org Date: Wed Nov 22 16:20:17 CET 2017 * Article middleboxes patch 3e71659b7b880f5cad02a441368a0e753b36de15 Author: stephane@sources.org Date: Sun Nov 5 17:13:40 CET 2017 * Début du travail sur le livre
Cela permet aussi de voir combien de commits sont faits :
% darcs changes . --count Changes to Livre: 485
(Oui, on aurait pu faire darcs changes . | grep Date | wc -l .)
Comme toutes les métriques quantitatives d'un travail humain, ce
chiffre n'a guère de signification ; il dépend de si on commite
souvent ou seulement à la fin de la journée, par exemple. C'est
juste amusant.
Un avantage important d'un VCS réparti (comme darcs ou git) est que chaque copie locale est un historique complet du travail. Tout est donc automatiquement réparti sur chaque machine (le PC fixe à la maison, le portable en déplacement, plus une ou deux machines hébergées à l'extérieur, et une clé USB…), ce qui est une forme efficace de sauvegarde. J'ai vu plus d'une fois un étudiant perdre toute sa thèse parce que les fichiers se trouvaient sur une seule machine, en panne, perdue ou volée, pour ne pas avoir envie de faire comme eux. Et l'utilisation du VCS réparti pour cela est moins pénible que la plupart des systèmes de sauvegarde.
J'ai dit plus haut que les métriques quantitatives n'avaient guère de sens ; l'avancement du travail ne se mesure pas au nombre de caractères tapés ! Si ces métriques sont assez ridicules quand des chefs de projet prétendent les utiliser pour suivre le travail de leurs subordonnés, elles sont quand même utiles à l'auteur qui :
- Sait quelle confiance limitée il faut leur accorder,
- A envie de suivre un peu ce qu'il fait.
J'ai donc écrit quelques scripts très simples pour compter quelques trucs
que je trouve utiles. Pour compter le nombre de caractères, je me
sers d'un programme XSLT, totext.xsl, qui garde
uniquement le texte avant de passer à wc (utiliser wc
sur le fichier XML compterait en trop toutes les balises XML) :
% make count xsltproc totext.xsl livre-noent.xml > livre.txt wc -c livre.txt 577930 livre.txt
Je marque les choses à faire dans le texte avec la chaîne de
caractères « TODO » (à faire). Il y a donc aussi des scripts pour
compter ces TODO. Par exemple, make count
comptait aussi les TODO :
% make count xsltproc totext.xsl livre-noent.xml > livre.txt wc -c livre.txt 432717 livre.txt Encore 59 TODO
Le source du livre était découpé en plusieurs fichiers, donc il était utile pour moi de savoir quels fichiers avaient le plus de TODO, avec grep et sort :
% make todo grep -c TODO *xml | grep -v ':0$' | sort -r -n -t: -k 2 neutralite.xml:8 censure.xml:7 technique.xml:6 gouvernance.xml:5 blockchain.xml:5 droitshumains.xml:4 securite.xml:3 plateformes.xml:3 adresse-ip-exposee.xml:3 acces.xml:3 ...
Il était également utile pour moi de compter la proportion de TODO par fichier (certains sont plus gros que d'autres) :
% ./todo-pct.sh protocoles.xml:3 gouvernance.xml:2 finances.xml:0 ...
(Oui, le script est disponible ici.)
Le livre bénéficie d'un site Web d'accompagnement,
https://cyberstructure.fr/
LogFormat "%u %t \"%r\" %>s %O \"%{Referer}i\" %v" minimum
CustomLog /var/log/apache2/access_cyberstructure.log minimum
Ce qui donne dans le journal des lignes comme :
- [19/Dec/2018:01:33:31 +0100] "GET / HTTP/1.1" 200 6420 "https://www.bortzmeyer.org/livre-publie.html" cyberstructure.fr
Je n'ai pas utilisé de correcteur orthographique. Il en existe en logiciel libre comme aspell mais je les trouve peu utiles : je fais relativement peu de fautes d'orthographe, j'ai d'excellents correcteurs humains, et il y a beaucoup de termes techniques dans le livre que le correcteur informatique ne connait pas, ce qui aurait rendu son utilisation pénible. (Il faut ajouter plein de mots à la première utilisation.)
% aspell check -l FR livre.txt
(Il faut avoir installé le paquetage
aspell-fr pour avoir les mots français.)
Je ne suis pas bon pour les dessins (disons même que je suis franchement nul). Les schémas ont donc été faits de manière sommaire avec Asymptote, puis refaits proprement par un graphiste professionnel.
D'autres articles écrits par des auteurs de livre ayant des cahiers des charges comparables :
- « Writing a Book with Pandoc, Make, and Vim ».
- Christophe Masutti sur son livre « Affaires privées ».
- L'exposé de Marina Fernández de Retana au Capitole du Libre 2019 sur ses romans et comment elle les écrit : regardez cet exposé sur YouTube.
L'article seul
RFC 8427: Representing DNS Messages in JSON
Date de publication du RFC : Juillet 2018
Auteur(s) du RFC : P. Hoffman (ICANN)
Pour information
Première rédaction de cet article le 11 décembre 2018
Le format des messages DNS circulant sur le réseau est un format binaire, pas forcément évident à analyser. Pour beaucoup d'applications, il serait sans doute préférable d'utiliser un format normalisé et plus agréable, par exemple JSON, dont ce nouveau RFC décrit l'utilisation pour le DNS.
Non seulement le format des messages DNS est du binaire (RFC 1035, section 4) et non pas du texte comme par exemple pour SMTP, XMPP ou HTTP, mais en plus il y a des pièges. Par exemple, la longueur des sections du message est indiquée dans un champ séparé de la section, et peut ne pas correspondre à la vraie longueur. La compression des noms n'arrange rien. Écrire un analyseur de messages DNS est donc difficile.
Il y a un million de formats pour des données structurées mais, aujourd'hui, le format texte le plus populaire pour ces données est certainement JSON, normalisé dans le RFC 8259. L'utilisation de JSON pour représenter les messages DNS (requêtes ou réponses) suit les principes suivants (section 1.1 du RFC) :
- Tout est optionnel, on peut donc ne représenter qu'une
partie d'un message. (Des profils ultérieurs de cette
spécification pourraient être
plus rigoureux, par exemple une base de
passive DNS peut
imposer que
QNAME, le nom de domaine demandé, soit présent, cf. section 6 du RFC.) - Si l'information est présente, on peut recréer le format binaire utilisé par le protocole DNS à partir du JSON (pas forcément bit pour bit, surtout s'il y avait de la compression).
- Tous les noms sont représentés dans le sous-ensemble ASCII d'UTF-8, obligeant les IDN à être en Punycode (alors que JSON permet l'UTF-8).
- Les données binaires peuvent être stockées, à condition d'être encodées en Base16 (RFC 4648).
- Il n'y a pas de forme canonique : le même message DNS peut être représenté par plusieurs objets JSON différents.
- Certains membres des objets JSON sont redondants et il peut donc y avoir des incohérences (par exemple entre la longueur indiquée d'une section ou d'un message, et sa longueur réelle, cf. la section 8 sur les conséquences que cela a pour la sécurité). Cela est nécessaire pour reconstituer certains messages DNS malformés. Autrement, le format serait limité aux messages corrects.
- Le format représente des messages, pas des fichiers de zone (RFC 1035, section 5).
La section 2 du RFC donne la liste des membres (au sens JSON de
« champs d'un objet ») d'un objet DNS. Voici un exemple d'un tel
objet, une requête DNS demandant l'adresse IPv4 (code 1, souvent
noté A) d'example.com :
{ "ID": 19678, "QR": 0, "Opcode": 0,
"AA": 0, "TC": 0, "RD": 0, "RA": 0, "AD": 0, "CD": 0, "RCODE": 0,
"QDCOUNT": 1, "ANCOUNT": 0, "NSCOUNT": 0, "ARCOUNT": 0,
"QNAME": "example.com", "QTYPE": 1, "QCLASS": 1
}
Les noms des membres sont ceux utilisés dans les
RFC DNS, même s'ils
ne sont pas très parlants (RCODE au lieu
ReturnCode).
On note que les différents membres qui sont dans le DNS
représentés par des entiers le sont également ici, au lieu
d'utiliser les abréviations courantes. Ainsi,
Opcode est marqué 0 et pas Q
(query), et QTYPE
(query type) est marqué 1 et pas A (adresse
IPv4). Cela permet de représenter des valeurs inconnues, qui n'ont
pas d'abréviation textuelle, même si ça rend le résultat peu
lisible si on ne connait pas les valeurs des
paramètres DNS par coeur.
Les valeurs d'un seul bit (booléens) sont représentés par 0 ou
1, pas par les false ou
true de JSON. (J'avoue ne pas bien comprendre ce choix.)
On note également que les longueurs des sections sont indiquées
explicitement, ici QDCOUNT (Query
Count, et ne me demandez pas à quoi sert le D après le
Q, le RFC 1035 ne l'explique pas). En JSON,
cela n'est pas obligatoire (la longueur d'un tableau, en JSON,
n'est pas spécifiée explicitement) mais, comme expliqué plus haut,
cela a été décidé pour permettre de représenter des messages DNS
anormaux, par exemple ayant un QDCOUNT de 0
et une question dans la section Question (cf. section 8 du RFC sur
les conséquences que cela peut avoir pour la sécurité). De tels messages
arrivent assez souvent dans le trafic DNS réel vu par les serveurs
connectés à l'Internet ; attaque délibérée ou bien logiciel écrit
avec les pieds ?
Et voici un exemple de réponse (QR = 1)
DNS en JSON. La requête a été un succès
(RCODE = 0) :
{ "ID": 32784, "QR": 1, "AA": 1, "RCODE": 0,
"QDCOUNT": 1, "ANCOUNT": 2, "NSCOUNT": 1,
ARCOUNT": 0,
"answerRRs": [ { "NAME": "example.com.",
"TYPE": 1, "CLASS": 1,
"TTL": 3600,
"RDATAHEX": "C0000201" },
{ "NAME": "example.com.",
"TYPE": 1, "CLASS": 1,
"TTL": 3600,
"RDATAHEX": "C000AA01" } ],
"authorityRRs": [ { "NAME": "ns.example.com.",
"TYPE": 1, "CLASS": 1,
"TTL": 28800,
"RDATAHEX": "CB007181" } ]
La réponse contient un ensemble d'adresses IP
(TYPE = 1 identifie une adresse IPv4),
192.0.2.1 et 192.0.170.1. Leur
valeur est encodée en hexadécimal. C'est
moins joli que si on avait mis l'adresse IP en clair mais c'est
plus général : cela permet d'inclure immédiatement de nouveaux
types de données, au détriment de la lisibilité pour les anciens
types.
Le format de ce RFC permet aussi de décrire l'association entre
une requête et une réponse (section 3 du RFC). On les met dans un
objet JSON ayant un membre queryMessage et un
responseMessage.
Si on représente une suite continue de messages DNS, faire un objet JSON avec son accolade ouvrante et la fermante correspondante peut ne pas être pratique. On utilise alors les séquences du RFC 7464, décrites dans la section 4 de notre RFC.
Notre RFC spécifie également (section 7) un type
MIME pour le DNS en JSON, application/dns+json.
Notez qu'il ne s'agit pas de la première description du DNS en
JSON. Par exemple, j'avais décrit un format pour cela dans le
brouillon draft-bortzmeyer-dns-json. Ce format
est mis en œuvre dans le DNS Looking
Glass. Mon format était plus joli, car utilisant
toujours des noms plus parlants ("Type": "AAAA"
au lieu du "QTYPE": 28). Notez toutefois que
le RFC 8427 le permet également ("QTYPEname":
"AAAA"). Le format plus joli ne peut de toute façon pas
être utilisé systématiquement car il ne permet pas de représenter
les types inconnus. Et mon format ne permet pas non plus de
représenter les messages malformés. (Par exemple, le
ANCOUNT est toujours implicite.)
Un autre exemple de représentation des données DNS est donné par les sondes RIPE Atlas. Le fichier des résultats d'une mesure est en JSON (ce qui permet le traitement par les outils JSON habituels comme jq). Voici un exemple (si vous voulez un exemple complet, téléchargez par exemple le résultat de la mesure #18061873) :
"resultset": [
{
...
"result": {
"ANCOUNT": 1,
"ARCOUNT": 0,
"ID": 38357,
"NSCOUNT": 0,
"QDCOUNT": 1,
"abuf": "ldWBgAABAAEAAAAADmN5YmVyc3RydWN0dXJlAmZyAAAcAAHADAAcAAEAAVGAABAgAUuYDcAAQQIWPv/+Jz0/",
"rt": 103.7,
"size": 63
},
},
On note que seule une petite partie des
champs de la réponse (ANCOUNT,
ID…) est exprimée en JSON, la majorité de la requête
étant dans un membre abuf qui est la
représentation binaire de la réponse.
Le service de DNS sur HTTPS de Google produit également du JSON (on le passe à jq pour qu'il soit plus joliment affiché) :
% curl -s https://dns.google.com/resolve\?name=laquadrature.net\&type=MX | jq .
{
"Status": 0,
"TC": false,
"RD": true,
"RA": true,
"AD": false,
"CD": false,
"Question": [
{
"name": "laquadrature.net.",
"type": 15
}
],
"Answer": [
{
"name": "laquadrature.net.",
"type": 15,
"TTL": 475,
"data": "5 pi.lqdn.fr."
}
]
}
en utilisant un format
spécifique à Google.
On notera que le protocole DoH, normalisé dans le RFC 8484, n'utilise pas JSON (et le
service de Google, contrairement à ce qu'on voit parfois écrit,
n'utilise pas DoH) mais le format binaire du DNS, utilisant le
type MIME application/dns-message. Le RFC 8484 prévoit
toutefois la possibilité de se servir de JSON pour le futur (section
4.2 du RFC 8484).
L'article seul
Publication de mon livre « Cyberstructure »
Première rédaction de cet article le 4 décembre 2018
Je viens d'écrire un livre nommé « Cyberstructure / Internet, un espace politique » et qui parle des relations entre l'architecture technique de l'Internet et la politique, notamment les droits humains. Il est publié chez C & F Éditions. Pour les différents moyens de l'acheter, vous pouvez regarder le site web d'accompagnement.
Vous n'y trouverez pas la Nième diatribe sur les méchants GAFA, leurs impôts et leurs pratiques de surveillance. D'abord, cela a déjà été largement décrit ailleurs, et je n'avais pas grand'chose d'original à ajouter sur ce point. Mais, surtout, j'avais envie de parler d'autre chose, des parties moins visibles de l'Internet, de son infrastructure. C'est donc forcément un peu technique mais ce livre n'est normalement pas destiné aux informaticiens. Il comporte une première moitié d'explications sur le fonctionnement de l'Internet (si vous lisez les RFC, vous connaissez probablement déjà le contenu de cette première partie). Et la seconde moitié est composée d'une série d'études de cas sur des sujets politiques que je trouve pas assez traités, perdus dans les débats sur Facebook et Google.
Pourquoi avoir écrit un livre, alors que je pouvais tout mettre sur mon blog ? Un avertissement d'abord : je ne partage pas du tout le point de vue conservateur comme quoi seuls les livres et les articles du Monde sont sérieux, le reste étant du travail d'amateur internaute. (Et les plus conservateurs des conservateurs sont encore pires, considérant que le livre n'a ses propriétés magiques que s'il est imprimé sur papier. Le contenu ne compte pas, pour eux, seule la forme papier est importante.) Il y a des tas de livres ridicules et inutiles, et plein d'articles de blog (ou de fils de discussion sur les réseaux sociaux) remarquables et qui font réfléchir. Par contre je ne pense pas non plus que tout est pareil : un livre a des propriétés différentes de celles d'une série d'articles de blog (pas supérieures ou inférieures, différentes).
Il y avait donc plusieurs raisons pour faire un livre (si vous vous intéressez au contenu du livre et pas aux états d'âme de l'auteur, vous pouvez arrêter cet article ici et aller vous procurer le livre et le lire) :
- L'argent (vous noterez que le livre n'est pas sous une licence libre, quoique elle soit assez libérale et qu'il n'y ait pas de menottes numériques pour la version EPUB chez l'éditeur). Non, je rigole : écrire un livre et le vendre rapporte certes de l'argent mais ce n'est pas rentable. L'auteur (moi, en l'occurrence) touche une avance fixe, et un pourcentage sur chaque exemplaire vendu (pourcentage qui est une minorité du prix de vente) mais cela ne compense pas le temps que cela prend. Si j'avais passé ce temps à des activités commerciales plus rentables, j'aurais gagné bien plus. (Pour mon blog, l'appel à m'envoyer des bitcoins n'a pas rapporté grand'chose.) Pour un Guillaume Musso ou un Marc Levy, qui ont des revenus conséquents, il y des milliers d'auteurs qui ne gagnent pas d'argent, en tout cas pas en proportion du temps passé et des efforts déployés. Notez au passage que cela invalide la ridicule propagande des ayant-droits « si les créateurs ne sont pas rémunérés, il n'y aura plus de création ». Il suffit de voir le nombre toujours croissant de livres publiés (malgré le méchant Internet qui soi-disant tue les artistes), dont la plupart ne seront pas des best-sellers, ni même des bonnes ventes, pour se rendre compte que la grande majorité des auteurs écrivent parce qu'ils désirent écrire, pas dans l'espoir d'un gain financier.
- Le prestige. Eh oui, chacun ses faiblesses. C'est flatteur de se voir en librairie, même si on n'est pas invité à une émission à la télévision. C'est particulièrement vrai en France, où l'objet-livre reste relativement sacré.
- La diffusion des idées. Un livre, diffusé par un éditeur, et ayant une distribution physique, permet de toucher des gens différents. Certes, grâce à l'Internet, tout le monde peut mettre par écrit ses pensées (ou sur une vidéo, pour toucher les gens qui ne savent pas lire) et le monde entier peut alors y accéder. C'est le gros avantage de l'Internet, et la raison pour laquelle les autorités en place veulent à tout prix le « civiliser », c'est-à-dire faire rentrer le torrent dans son lit. Mais le fait que le monde entier puisse y accéder ne signifie pas qu'ils vont le faire effectivement. Pour des raisons très variées, certaines mauvaises et d'autres bonnes, un livre reste encore, en 2018, un moyen plus efficace pour atteindre certains publics.
- Une nouvelle expérience. Une caractéristique importante de ce livre est que c'est un travail d'équipe. Je peux écrire des articles sur mon blog (comme celui que vous êtes en train de lire) et les publier tout seul, sans rien demander à personne. Cela a des avantages (rapidité, contrôle de tous les détails, cohérence du texte) mais aussi des inconvénients. Avoir des regards extérieurs, discuter du contenu avant publication, est très bénéfique. Un travail qui soit davantage collectif est une expérience que j'avais envie de tenter.
- La qualité. Un livre permet aussi de déléguer certaines tâches, comme la mise en page, sur lesquelles je n'ai aucune compétence. Non seulement cela donne un meilleur résultat (le livre est plus agréable à lire) mais cela force l'auteur à se concentrer sur le contenu, au lieu de passer des jours à perfectionner ses macros LaTeX.
Notez bien qu'un livre n'est pas forcément sur papier. Les réactionnaires qui déplorent la disparition du livre au profit du méchant numérique font parfois un éloge nostalgique du papier, supposé avoir des propriétés merveilleuses. En fait, les arguments que j'ai donnés plus haut en faveur du livre sont pour la plupart tout aussi vrais pour le livre numérique que pour le livre papier. La forme papier a des tas d'avantages (lecture en plein soleil, dans son bain, pas de dépendance vis-à-vis du courant électrique, probablement une meilleure conservation sur le long terme), mais un livre ce n'est pas juste une forme physique ! C'est avant tout le travail des personnes qui ont écrit, relu, corrigé, discuté, mis en page, et ce travail est ce qui fait la valeur du livre. (Pour une excellente étude sur les usages de l'objet livre, je vous recommande Le livre-échange, chez le même éditeur.)
Après ces considérations générales, comment s'est passée la réalisation de ce livre particulier ? D'abord, un conseil général aux auteurs (personne n'écoute les conseils, et à juste titre) : cela prend toujours plus de temps que prévu. Je croyais que ce serait l'affaire de deux ou trois mois, mais cela a été bien plus long :
- Plusieurs discussions préparatoires avec l'éditeur en 2017, pour essayer de cerner un peu en quoi consistera ce livre. (Je décris ici le processus de production de mon livre : d'autres ont été faits différemment, par exemple par un auteur apportant à un éditeur un livre déjà fini.)
- Novembre 2017, j'écris une section du livre (celle sur les « boitiers intermédiaires »), pour tester mon style et discuter avec l'éditeur. J'écris aussi un plan détaillé.
- Décembre 2017, le format est décidé, le plan fini, l'écriture commence.
- Les vacances de fin d'année 2017 voient une bonne partie de l'écriture être faite. Les dates des fichiers me rappellent que la section sur le chiffrement a été faite le 31 décembre et finie à 18h30, la section sur les problèmes liés à l'Internet étant commencée le 1 janvier à 12h00. Les programmeu·r·se·s ne seront pas surpris·es d'apprendre que, quand on écrit un livre, on produit parfois plein de contenu en une semaine, qu'on passe ensuite deux mois à corriger, modifier, vérifier. Le nombre de signes n'est donc pas une bonne métrique de l'avancement du travail.
- Février 2018, le travail n'avance pas assez vite (je suis salarié et je ne peux pas écrire à temps plein). Sur le conseil d'une auteure, je prends une semaine de congés pour une « retraite » d'écriture. Après avoir envisagé d'aller dans un monastère (nombreux sont ceux qui louent des chambres aux cadres surmenés cherchant un moment de concentration tranquille), je loue un petit appartement à Chivres-Val (où il n'y a pas beaucoup de distractions, surtout en hiver, ce qui aide au travail) et une grande partie du livre est alors faite. Je recommande la méthode : une semaine seul, sans sortir, et sans interruptions, c'est fou ce que ça augmente la productivité.
- Mars 2018, première relecture extérieure. Évidemment, la relectrice trouve plein de problèmes et suggère de nombreuses modifications. Ces relectures sont une des grandes différences avec mes articles sur ce blog. Sur ce blog, personne ne voit les articles avant parution. Parfois, il y a des remarques ensuite, que j'intègre dans certains cas, mais c'est très différent d'une relecture a priori, où il peut être nécessaire de changer des choses importantes, ce que j'ai psychologiquement du mal à faire. Écrire lorsqu'il y a des relecteurices nécessite d'abandonner son attitude défensive (« mais il est très bien, mon livre ») et d'accepter des remarques critiques. Au passage, je remercie mes relecteurices de leur honnêteté et de leur franchise (« ce passage est incompréhensible, il faut le refaire »).
- Mai 2018, contrat avec l'éditeur signé. Les contrats d'édition sont souvent signés une fois le livre largement rédigé.
- Juin 2018, beaucoup de relectures extérieures, et donc beaucoup de changements à faire.
- Juillet 2018, premier envoi à l'éditeur, pour un premier avis. J'ai reçu plein de remarques au stylo rouge sur un exemplaire papier (le papier est un bon support pour les relectures et corrections, surtout l'été quand on est dehors). Vacances en août où je lis les corrections, et apporte des modifications.
- Septembre 2018, deux relectures particulièrement pointues, qui trouvent de nombreux problèmes, et pas mal de fautes d'orthographe ou de grammaire que je pensais éradiquées depuis longtemps. Puis c'est l'envoi de la version « stable » (à ce stade, on ne peut pas encore dire « définitive ») à l'éditeur.
- Novembre 2018, réception du projet de couverture du livre (faite par Nicolas Taffin, de C & F Éditions), et du projet de livre mis en page.
- Même mois, après correction du projet, et réalisation de la couverture, envoi à l'imprimeur.
- 17 novembre, première mention publique au Capitole du Libre à Toulouse.
- Premier exemplaire imprimé reçu le 3 décembre 2018.
Le livre, à son arrivée : 
À plusieurs reprises, je me suis dit « là, c'est bon, c'est terminé », avant qu'un·e relect·eur·rice ne me fasse des remarques précises dont la prise en compte nécessitait un sérieux travail. Bref, écrire est un marathon, pas un sprint.
Les lect·eurs·crices de mon blog verront que certaines sections du livre ont été recopiées depuis mon blog. C'est le cas par exemple de celle sur la neutralité. De même, la section sur l'internationalisation a été reprise depuis l'ouvrage collectif Net.Lang, avec l'autorisation de l'éditeur. Mais la plus grande partie du contenu est originale.
Si vous vous intéressez à la partie technique du travail (quel logiciel j'ai utilisé, etc), voyez mon autre article.
Et le contrat avec l'éditeur ? C'est un document de sept pages, évidemment à lire soigneusement. Parmi les différent articles du contrat, j'ai noté :
- L'article 2 dit que la responsabilité juridique revient à l'auteur. Si Vincent Bolloré fait un procès car on a parlé de lui d'une manière qu'il n'approuve pas, c'est à l'auteur de se débrouiller, il ne peut pas se cacher derrière l'éditeur.
- Les droits d'auteur comprennent un à-valoir fixe, puis un pourcentage de 8 % par exemplaire. (Cf. plus haut sur la rentabilité de l'écriture d'un livre.)
- J'ai cédé les droits d'adaptation en bande dessinée 🤣 mais pas ceux d'adaptation au cinéma 🤣.
- J'ai aussi cédé les droits de traduction. Je serais d'ailleurs très heureux que ce livre soit traduit. Ce n'est pas tellement utile pour l'anglais, où il y a déjà beaucoup de textes sur la politique et Internet, mais cela serait très souhaitable dans d'autres langues. Donc, si vous connaissez traducteurs et éditeurs étrangers qui seraient intéressés, n'hésitez pas à me les signaler.
Cet article est l'occasion de remercier une nouvelle fois celles et ceux qui ont contribué à ce livre, à commencer par Hervé le Crosnier, qui s'est beaucoup démené pour que ce livre naisse. Un livre n'est pas fait que par un·e auteur·e. De même que, dans la programmation, les gens qui signalent des bogues et font des rapports de bogue détaillés sont un élément indispensable du succès, de même relecteur·e·s, éditeur·e·s, maquettistes et imprimeur·e·s méritent les chaleureux remerciements que j'envoie ici.
En conclusion ? Malgré le discours à la mode comme quoi les gens n'arrivent plus à lire quoi que ce soit de plus long qu'un tweet, malgré la tendance à ne mettre comme documentation, même technique, que des vidéos, on ne peut pas dire que le livre soit menacé de disparition : il y en a toujours autant d'écrits, et les salons consacrés aux livres ne désemplissent pas. Sont-ils lus ? Je ne sais pas, mais comme dit plus haut, l'auteur de livre n'est pas rationnel : il ou elle écrit car il ou elle veut écrire.
L'article seul
RFC 8467: Padding Policies for Extension Mechanisms for DNS (EDNS(0))
Date de publication du RFC : Octobre 2018
Auteur(s) du RFC : A. Mayrhofer (nic.at GmbH)
Expérimental
Réalisé dans le cadre du groupe de travail IETF dprive
Première rédaction de cet article le 2 décembre 2018
Chiffrer pour assurer la confidentialité, c'est bien. Pour le DNS, c'est ce que permet le RFC 7858 (DNS sur TLS). Mais un problème de TLS et de pas mal d'autres protocoles cryptographiques est qu'il ne dissimule pas les métadonnées, et notamment la taille des messages échangés sur le réseau. Dans un monde public comme celui du DNS, c'est un problème. En effet, l'attaquant peut facilement mesurer la taille des réponses chiffrées (en envoyant lui-même une requête), voir la taille des réponses, et en déduire les questions qui avaient été posées. La solution classique en cryptographie face à ce risque est le remplissage, normalisé, pour le DNS, dans le RFC 7830. Mais le RFC 7830 ne normalisait que le format, pas le mode d'emploi. Il faut remplir jusqu'à telle taille ? Comment concilier un remplissage efficace pour la confidentialité avec le désir de limiter la consommation de ressources réseaux ? Ce RFC décrit plusieurs stratégies possibles, et recommande un remplissage jusqu'à atteindre une taille qui est le multiple suivant de 468 (octets).
Ce nouveau RFC tente de répondre à ces questions, en exposant les différentes politiques possibles de remplissage, leurs avantages et leurs inconvénients. Le RFC 7830 se limitait à la syntaxe, notre nouveau RFC 8467 étudie la sémantique.
D'abord, avant de regarder les politiques possibles, voyons les choses à garder en tête (section 3 du RFC). D'abord, ne pas oublier de mettre l'option EDNS de remplissage (celle du RFC 7830) en dernier dans la liste des options (car elle a besoin de connaitre la taille du reste du message).
Ensuite, il faut être conscient des compromis à faire. Remplir va améliorer la confidentialité mais va réduire la durée de vie de la batterie des engins portables, va augmenter le débit qu'on injecte dans le réseau, voire augmenter le prix si on paie à l'octet transmis. Lors des discussions à l'IETF, certaines personnes ont d'ailleurs demandé si le gain en confidentialité en valait la peine, vu l'augmentation de taille. En tout cas, on ne remplit les messages DNS que si la communication est chiffrée : cela ne servirait à rien sur une communication en clair.
Enfin, petit truc, mais qui montre l'importance des détails quand on veut dissimuler des informations, le remplissage doit se faire sans tenir compte des deux octets qui, avec certains protocoles de transport du DNS, comme TCP, peut faire fuiter des informations. Avec certaines stratégies de remplissage, les deux octets en question peuvent faire passer de l'autre côté d'un seuil et donc laisser fuiter l'information qu'on était proche du seuil.
Ensuite, après ces préliminaires, passons aux stratégies de remplissage, le cœur de ce RFC (section 4). Commençons par celle qui est la meilleure, et recommandée officiellement par notre RFC : remplissage en blocs de taille fixe. Le client DNS remplit la requête jusqu'à atteindre un multiple de 128 octets. Le serveur DNS, si le client avait mis l'option EDNS de remplissage dans la requête, et si la communication est chiffrée, remplit la réponse de façon à ce qu'elle soit un multiple de 468 octets. Ainsi, requête et réponse ne peuvent plus faire qu'un nombre limité de longueurs, la plupart des messages DNS tenant dans le bloc le plus petit. Voici un exemple vu avec le client DNS dig, d'abord sans remplissage :
% dig +tcp +padding=0 -p 9053 @127.0.0.1 SOA foobar.example
...
;; ->>HEADER<<- opcode: QUERY, status: NOERROR, id: 29832
;; flags: qr aa rd; QUERY: 1, ANSWER: 1, AUTHORITY: 0, ADDITIONAL: 1
...
;; OPT PSEUDOSECTION:
; EDNS: version: 0, flags: do; udp: 4096
; COOKIE: dda704b2a06d65b87f0493105c03ca4d2b2c83f2d4e25680 (good)
;; QUESTION SECTION:
;foobar.example. IN SOA
;; ANSWER SECTION:
foobar.example. 600 IN SOA ns1.foobar.example. root.foobar.example. (
2015091000 ; serial
604800 ; refresh (1 week)
86400 ; retry (1 day)
2419200 ; expire (4 weeks)
86400 ; minimum (1 day)
)
...
;; MSG SIZE rcvd: 116
La réponse fait 116 octets. On demande maintenant du remplissage, jusqu'à 468 octets :
% dig +tcp +padding=468 -p 9053 @127.0.0.1 SOA foobar.example
...
;; ->>HEADER<<- opcode: QUERY, status: NOERROR, id: 2117
;; flags: qr aa rd; QUERY: 1, ANSWER: 1, AUTHORITY: 0, ADDITIONAL: 1
;; WARNING: recursion requested but not available
;; OPT PSEUDOSECTION:
; EDNS: version: 0, flags: do; udp: 4096
; COOKIE: 854d2f29745a72e5fdd6891d5c03ca4b5d5287daf716e327 (good)
; PAD (348 bytes)
;; QUESTION SECTION:
;foobar.example. IN SOA
;; ANSWER SECTION:
foobar.example. 600 IN SOA ns1.foobar.example. root.foobar.example. (
2015091000 ; serial
604800 ; refresh (1 week)
86400 ; retry (1 day)
2419200 ; expire (4 weeks)
86400 ; minimum (1 day)
)
;; MSG SIZE rcvd: 468
La réponse fait 468 octets, grâce aux 348 octets de remplissage
(notez la ligne PAD (348 bytes)).
Les avantages de cette méthode est qu'elle est facile à mettre en œuvre, assure une confidentialité plutôt bonne, et ne nécessite pas de générateur de nombres aléatoires. Son principal inconvénient est qu'elle permet de distinguer deux requêtes (ou deux réponses) si elles ont le malheur d'être remplies dans des blocs de taille différente. Mais il ne faut pas chercher une méthode idéale : rappelez-vous qu'il faudra faire des compromis. Cette méthode a un faible coût pour le défenseur, et élève les coûts sensiblement pour l'attaquant, c'est ça qui compte.
Notez que les chiffres 128 et 468 ont été obtenus empiriquement, en examinant du trafic DNS réel. Si DNSSEC continue à se répandre, les tailles des réponses moyennes augmenteront, et il faudra peut-être réviser ces chiffres.
Une autre statégie est celle du remplissage maximal. On met autant d'octets qu'on peut. Si un serveur a une taille maximale de réponse de 4 096 octets (la valeur par défaut la plus courante) et que le client accepte cette taille, on remplit la réponse jusqu'à ce qu'elle fasse 4 096 octets. L'avantage évident de cette méthode est qu'elle fournit la meilleure confidentialité : toutes les réponses ont la même taille. L'inconvénient évident est qu'elle est la méthode la plus consommatrice de ressources. En outre, ces grandes réponses vont souvent excéder la MTU, pouvant entrainer davantage de problèmes liés à la fragmentation.
Autre stratégie envisageable : remplissage aléatoire. On tire au sort le nombre d'octets à ajouter. Cela fournit une bonne distribution des tailles (par exemple, une réponse courte peut désormais être plus grande qu'une réponse longue, ce qui n'arrive jamais avec les deux stratégies précédentes). Inconvénient : comme ça ne change pas la limite de taille inférieure, un attaquant qui voit beaucoup de messages pourrait en déduire des informations. Et cela oblige à avoir un générateur de nombres aléatoires, traditionnellement un problème délicat en cryptographie.
Enfin, une dernière méthode raisonnable est de combiner le remplissage dans des blocs et le tirage au sort : on choisit au hasard une longueur de bloc et on remplit jusqu'à atteindre cette longueur. Contrairement à la précédente, elle n'a pas forcément besoin d'une source aléatoire à forte entropie. Mais c'est sans doute la technique la plus compliquée à mettre en œuvre.
La section 7 du RFC ajoute quelques points supplémentaires qui peuvent mettre en péril la confidentialité des requêtes. Par exemple, si le client DNS remplit correctement sa requête, mais que le serveur ne le fait pas, un attaquant pourra déduire la requête de la réponse (c'est d'autant plus facile, avec le DNS, que la question est répétée dans la réponse). Dans une communication de client à résolveur DNS, il faut bien choisir son résolveur.
Et le remplissage ne brouille qu'une seule des métadonnées. Il y en a d'autres comme l'heure de la question, le temps de réponse ou comme la succession des requêtes/réponses, qui restent accessibles à un éventuel attaquant. La protection contre la fuite d'informations via ces métadonnées nécessiterait d'injecter « gratuitement » du trafic de couverture (qui, lui aussi, éleverait la consommation de ressources réseau).
Et pour terminer le RFC, l'annexe A est consacrée aux mauvaises politiques de remplissage, celles qui non seulement ne sont pas recommandées mais sont activement déconseillées. (Mais on les trouve parfois dans du code réel.) Il y a l'évidente stratégie « pas de remplissage du tout ». Son principal intérêt est qu'elle fournit le point de comparaison pour toutes les autres stratégies. Avantages : triviale à implémenter, il suffit de ne rien faire, et aucune consommation de ressources supplémentaires. Inconvénient : la taille des requêtes et des réponses est exposée, et un observateur malveillant peut en déduire beaucoup de choses.
Une autre méthode inefficace pour défendre la vie privée est celle du remplissage par une longueur fixe. Elle est simple à implémenter mais ne protège rien : une simple soustraction suffit pour retrouver la vraie valeur de la longueur.
Ces différentes stratégies ont été analysées empiriquement (il n'y a pas vraiment de bon cadre pour le faire théoriquement) et le travail est décrit dans l'excellente étude de Daniel Kahn Gillmor (ACLU), « Empirical DNS Padding Policy » présentée à NDSS en 2017. Si vous aimez les chiffres et les données, c'est ce qu'il faut regarder !
Testons un peu les mises en œuvres du remplissage des messages DNS (une liste plus complète figure sur le site du projet).
Essayons avec BIND version 9.13.4. Il
fournit le client de débogage dig et son
option +padding. Avec un
+padding=256, le
datagramme va faire 264 octets, incluant
les ports source et
destination d'UDP). Vu par tshark, cela donne :
<Root>: type OPT
Name: <Root>
Type: OPT (41)
UDP payload size: 4096
Higher bits in extended RCODE: 0x00
EDNS0 version: 0
Z: 0x8000
1... .... .... .... = DO bit: Accepts DNSSEC security RRs
.000 0000 0000 0000 = Reserved: 0x0000
Data length: 213
Option: COOKIE
Option Code: COOKIE (10)
Option Length: 8
Option Data: 722ffe96cd87b40a
Client Cookie: 722ffe96cd87b40a
Server Cookie: <MISSING>
Option: PADDING
Option Code: PADDING (12)
Option Length: 197
Option Data: 000000000000000000000000000000000000000000000000...
Padding: 000000000000000000000000000000000000000000000000...
Cela, c'était la requête du client. Mais cela ne veut pas dire que le serveur va accepter de répondre avec du remplissage. D'abord, il faut qu'il soit configuré pour cela (BIND 9.13.4 ne le fait pas par défaut). Donc, côté serveur, il faut :
options {
...
response-padding {any;} block-size 468;
};
(any est pour accepter le remplissage pour
tous les clients.) Mais cela ne suffit pas, BIND ne répond avec du
remplissage que si l'adresse IP source est raisonnablement sûre
(TCP ou biscuit du RFC 7873, pour éviter les attaques par amplification). C'est pour cela qu'il y a une option
+tcp dans les appels de dig plus haut. On
verra alors dans le résultat de dig le PAD (392
bytes) indiquant qu'il y a eu remplissage. La taille
indiquée dans response-padding est une taille
de bloc : BIND enverra des réponses qui seront un multiple de cette
taille. Par exemple, avec response-padding {any;}
block-size 128;, une courte réponse est remplie à 128
octets (notez que la taille de bloc n'est pas la même chez le
serveur et chez le client) :
% dig +tcp +padding=468 -p 9053 @127.0.0.1 SOA foobar.example
...
; PAD (8 bytes)
...
;; MSG SIZE rcvd: 128
Alors qu'une réponse plus longue (notez la question
ANY au lieu de SOA) va
faire passer dans la taille de bloc au
dessus (128 octets est clairement une taille de bloc trop petite,
une bonne partie des réponses DNS, même sans
DNSSEC, peuvent la dépasser) :
% dig +tcp +padding=468 -p 9053 @127.0.0.1 ANY foobar.example
...
; PAD (76 bytes)
...
;; MSG SIZE rcvd: 256
On voit bien ici l'effet de franchissement du seuil : une taille de bloc plus grande doit être utilisée.
BIND n'est pas forcément que serveur DNS, il peut être client,
quand il est résolveur et parle aux serveurs faisant autorité. La
demande de remplissage dans ce cas se fait dans la configuration
par serveur distant, avec padding. (Je n'ai
pas testé.)
Le résolveur Knot fait également le
remplissage (option net.tls_padding) mais, contrairement à BIND, il ne le fait que lorsque
le canal de communication est chiffré (ce qui est logique).
La bibliothèque pour développer des clients DNS getdns a également le remplissage. En revanche, Unbound, dans sa version 1.8.1, ne fait pas encore de remplissage. Et, comme vous avez vu dans l'exemple tshark plus haut, Wireshark sait décoder l'option de remplissage.
L'article seul
Journée de la Sécurité Informatique en Normandie ; sécurité(s) et liberté(s)
Première rédaction de cet article le 30 novembre 2018
Dernière mise à jour le 27 décembre 2018
Des conférences sur la sécurité informatique, il y en a trois par jour en France, parfois dans la même ville. On peut passer sa vie professionnelle à aller à de telles conférences. Mais elles sont plus ou moins intéressantes. La Journée de la Sécurité Informatique en Normandie fait partie de celles qui sont intéressantes. J'y ai présenté une réflexion en cours sur le débat « sécurité et liberté » dans le contexte de la sécurité informatique.
La JSecIN s'est tenue à Rouen le 29 novembre 2018, dans les locaux banlieusards de l'Université Rouen-Normandie (et co-organisée avec l'INSA). Le public était donc très majoritairement composé d'étudiants en informatique (dont une très faible proportion de femmes), avec quelques professionnels. Les exposés étaient tous intéressants. On a commencé avec Renaud Echard (ANSSI). Il a rappelé des bases en sécurité informatique, comme le fait qu'il faut utiliser le chiffrement systématiquement. Des bases vraiment basiques, certes, mais pas encore appliquées partout. L'orateur estime d'ailleurs que « 80 % des attaques seraient évitées avec l'application de quelques mesures simples d'hygiène numérique ». (La formation est donc un point-clé.)
On a vu bien sûr la classique (mais toujours vraie et utile) photo « le triptyque de la sécurité » : une porte blindée, avec un vérin de fermeture (la technique), un mot « cette porte doit rester fermée » (l'organisation) et une canette de Coca écrasée qui la tient ouverte (l'humain). Autre remarque pertinente : « Il vaut mieux une procédure simple qu'une procédure de 40 pages que personne ne lit. » L'orateur a également insisté sur l'importance de techniques simples : si le type qui fait la promotion d'une solution de sécurité ne peut pas vous l'expliquer simplement, c'est que le système est trop compliqué pour être auditable, et est donc peu sûr.
On a eu droit aussi à un peu de bureaucratie de la sécurité comme ce bon résumé de la différence entre OIV (Opérateur d'Importance Vitale, par exemple en Normandie, celui de l'énergie qui est au bord de la mer) et OSE (Opérateur de Service Essentiel) : « Un OSE est un OIV-light ». Et à la difficulté de l'attribution des cyberattaques : « Si vous me demandez d'où vient l'attaque, je vous dirais de me poser la question en privé. Et, là, je vous répondrais que je ne peux pas le dire. » Et une anecdote pour finir : dans les aéroports et gares français, de nombreux engins portables sont volés chaque jour. L'ANSSI recommande officiellement les autocollants sur le portable (pour rendre plus difficile les substitutions discrètes.)
Puis Solenn Brunet (CNIL) a présenté le paysage de la protection des données personnelles à l'heure du RGPD. Un exposé très riche (peut-être trop) car le sujet est complexe et nécessite de nombreuses explications. L'oratrice rappelle que le RGPD reprend l'essentiel de la loi Informatique & Libertés de 1978. Les gens qui se sont angoissés de certaines obligations du RGPD (minimisation des données, par exemple) ont donc 40 ans de retard. Principaux changements du RGPD : sanctions accrues, partage des responsabilités (donneur d'ordres et sous-traitants), recours collectifs… Depuis le RGPD, 6000 plaintes ont été déposées à la CNIL dont trois plaintes collectives, par La Quadrature, NOYB et Privacy International. Conclusion : la CNIL est là pour vous aider (pas seulement pour sanctionner), allez la voir pour conseil/accompagnement/etc.
Ensuite, les gens d'Exodus Privacy (tellement privé que leurs noms de l'état civil n'ont pas été donné) ont présenté leur travail d'analyse des applications sur Android, et notamment des innombrables pisteurs dont elles sont truffées. (Voir par exemple celle de l'Obs alors que ce journal explique régulièrement que les GAFA sont méchants.) Les développeurs ne mettent pas toujours les pisteurs délibérement. Ils utilisent des bibliothèques, et beaucoup incluent les pisteurs [disons franchement : les mouchards]. Vous utilisez le SDK Facebook, il y a un pisteur Facebook dedans. Programmeu·r·se·s : attention donc à ce que vous embarquez dans votre application.
Un excellent mais terrible exemple était celui de l'application « Baby + » (application de suivi de grossesse) qui transmettait des données personnelles à Facebook : le fœtus avait un compte Facebook avant même sa naissance. (Alors que personne n'avait utilisé Facebook sur cet ordiphone.) Pour aider l'excellent travail d'analyse d'Exodus Privacy, c'est par ici.
Puis Gaetan Ferry (Synacktiv) a parlé d'obscurcissement des programmes. Il s'agit de transformer un programme en quelque chose d'illisible (pas mal de développeurs PHP y arrivent très bien sans disposer de ces outils…) Cette technique ne sert qu'au logiciel privateur et aux attaquants qui veulent faire passer un logiciel malveillant à travers les protections du réseau (ce ne sont pas forcément des malhonnêtes, cela peut être des pentesteurs). Ce n'est donc pas forcément utile, mais c'est rigolo techniquement.
Les analyses théoriques de l'obscurcissement de programmes
montrent que ça ne marche pas. Mais en pratique, ça marche
suffisamment pour les buts souhaités (rendre l'analyse plus
difficile, voire impossible en pratique). On obscurcit les noms en
remplaçant les noms des classes/variables/fonctions. Cette perte
d'informations est irrémédiable. Évidemment, ça ne suffit pas, il
faut aussi brouiller la structure du code. (Mais ça peut casser le
programme s'il fait de l'introspection.) On utilise par exemple
la « chenxification » : remplacer tout le programme par un énorme
switch. Et pour
obscurcir les données, on les remplace par des résultats de
fonctions (par exemple on remplace false par
n > n, bon évidemment, en vrai, c'est plus
compliqué). À noter que déboguer une bogue dans l'obscurcisseur
est difficile puisque le programme produit est obscur…
Enfin, Pierre Blondeau (Université de Caen) a présenté un système de boot sécurisé mais automatique d'une machine Linux dont le disque est chiffré. Le cahier des charges imposait qu'on puisse démarrer la machine même en l'absence de son utilisateur (et donc sans connaitre la phrase de passe). Donc, dans initramfs, il a ajouté un client qui s'authentifie (cryptographie asymétrique) auprès d'un serveur local qui lui donne la clé de déchiffrement du disque. Un méchant qui volerait une des machines ne pourrait pas la démarrer. Le logiciel est disponible en ligne.
Mon exposé à cette conférence portait sur « La sécurité est-elle l'amie ou l'ennemie des droits humains ? ». Les supports de l'exposé sont disponibles ici en PDF, il y a aussi une version pour l'impression sur papier, et, si vous lisez le LaTeX, le source. Une transcription de l'exposé a été faite par l'APRIL (merci à eux pour cet énorme travail, fait avec soin !) et est désormais en ligne. (Pendant cet exposé, j'ai cité Zittrain donc c'est l'occasion de dire que j'avais parlé de son livre.)
Tout (sauf l'exposé du représentant de l'ANSSI) a été filmé et
les vidéos se trouvent sur la plateforme de
l'Université. La mienne est https://webtv.univ-rouen.fr/videos/jsecin-la-securite-est-elle-lamie-ou-lennemie-de-droits-humains-stephane-bortzmeyer/
Merci à Magali Bardet, Romain Hérault, et tous les autres organisateurs (et aux spectacteurs).
L'article seul
RFC 8386: Privacy Considerations for Protocols Relying on IP Broadcast or Multicast
Date de publication du RFC : Mai 2018
Auteur(s) du RFC : R. Winter (University of Applied Sciences
Augsburg), M. Faath (Conntac
GmbH), F. Weisshaar (University of Applied Sciences
Augsburg)
Pour information
Réalisé dans le cadre du groupe de travail IETF intarea
Première rédaction de cet article le 29 novembre 2018
Plusieurs protocoles applicatifs utilisent la diffusion, par exemple pour la découverte d'un service, et envoient donc des messages qui vont toucher toutes les machines du réseau local. Cela a des conséquences pour la vie privée : un observateur, même purement passif, peut apprendre plein de choses en écoutant. Il est donc important lorsqu'on conçoit des protocoles applicatifs de veiller à ne pas être trop bavard.
La diffusion, c'est envoyer à tout le monde. Comme il n'existe pas (heureusement !) de mécanisme fiable pour envoyer à tout l'Internet, en pratique, la diffusion se limite au réseau local. Mais c'est déjà beaucoup ! Connecté dans un café ou dans un autre endroit à WiFi, les messages diffusés arrivent à un groupe inconnu : un nombre potentiellement grand de machines. (L'utilisation d'un commutateur ne protège pas, si c'est de la diffusion.) La diffusion est très importante pour certaines fonctions (auto-configuration lorsqu'on ne connait pas sa propre adresse IP, ou bien résolution locale de noms ou d'adresses). La diffusion est tellement pratique (cf. RFC 919 et RFC 3819) qu'elle est utilisée par beaucoup d'applications.
Mais la diffusion est dangereuse ; à la conférence TRAC 2016, les auteurs du RFC avaient, dans un excellent exposé, publié un premier résultat de leurs travaux sur la question (Faath, M., Weisshaar, F., et R. Winter, How Broadcast Data Reveals Your Identity and Social Graph, 7th International Workshop on TRaffic Analysis and Characterization IEEE TRAC 2016, September 2016). En une journée à écouter le trafic diffusé sur leur université, ils avaient récolté 215 Mo de données. Les protocoles les plus bavards : 1) mDNS 2) SSDP 3) LLMNR 4) NetBIOS 5) Dropbox. Le seul client Dropbox diffuse à la cantonade l'ID du client, et celui des shares où il se connecte. Il est facile de faire un graphe des utilisateurs en mettant ensemble ceux qui se connectent au même share. Les mêmes auteurs avaient mené une expérience à grande échelle en écoutant le trafic diffusé lors de la réunion IETF 93 à Prague, et cela avait suscité bien des débats, notamment juridico-légaux (a-t-on le droit d'écouter du trafic qui est diffusé à tous ?) Comme en médecine, la science ne justifie pas tout et il est nécessaire de se pencher sur les conséquences de ses expériences.
Bien sûr, du moment qu'on envoie des données sur un réseau, elles peuvent être écoutées par des indiscrets. Mais la diffusion aggrave le problème de deux façons :
- Un éventuel indiscret n'a même pas besoin de techniques particulières pour écouter, il lui suffit d'ouvrir ses oreilles,
- La solution évidente à l'écoute, le chiffrement, marche mal avec la diffusion : il n'est pas facile de chiffrer lorsqu'on ne connait pas les destinataires.
Il est donc justifié de se préoccuper de près des conséquences de la diffusion sur la confidentialité (RFC 6973).
Pour certains protocoles conçus à l'IETF, il y a déjà eu des réflexions sur les problèmes de vie privée liés à leur usage de la diffusion. C'est évidemment le cas pour DHCP, dont les RFC 7819 et RFC 7824 ont pointé la grande indiscrétion. C'est aussi le cas des mécanismes de génération des adresses IPv6, expliqué dans le RFC 7721. Mais il y a également beaucoup de protocoles non-IETF qui utilisent imprudemment la diffusion, comme celui de Dropbox, présenté à la conférence TRAC. Ces protocoles privés sont en général peu étudiés, et la préservation de la vie privée est située très bas sur l'échelle des préoccupations de leurs auteurs. Et ils sont souvent non documentés, ce qui rend difficile toute analyse.
La section 1.1 de notre RFC résume les différents types de
diffusion qui existent dans le monde
IP. IPv4 a la
diffusion générale (on écrit à
255.255.255.255, cf. section 5.3.5.1 du RFC 1812) et la diffusion dirigée (on écrit à une
adresse qui est celle du préfixe du réseau local, avec tous les
bits « machine » à 1, cf. section 5.3.5.2 du même
RFC). IPv6, officiellement, n'a pas de
diffusion mais uniquement du
multicast mais c'est
jouer avec les mots : il a les mêmes possibilités qu'IPv4 et les
mêmes problèmes de confidentialité. Si une machine IPv6 écrit à
ff02::1, cela donnera le même résultat que si
une machine IPv4 écrit à
255.255.255.255. Parmi les protocoles
IETF qui utilisent ces adresses de
diffusion, on trouve mDNS (RFC 6762), LLMNR (RFC 4795), DHCP pour IPv4 (RFC 2131),
DHCP pour IPv6 (RFC 8415), etc.
La section 2 détaille les problèmes de vie privée que l'envoi de messages en diffusion peut entrainer. D'abord, le seul envoi des messages, même sans analyser ceux-ci, permet de surveiller les activités d'un utilisateur : quand est-ce qu'il est éveillé, par exemple. Plus les messages sont fréquents, meilleure sera la résolution temporelle de la surveillance. Notre RFC conseille donc de ne pas envoyer trop souvent des messages périodiques.
Mais un problème bien plus sérieux est celui des identificateurs stables. Bien des protocoles incluent un tel identificateur dans leurs messages, par exemple un UUID. Même si la machine change de temps en temps d'adresse IP et d'adresse MAC (par exemple avec macchanger), ces identificateurs stables permettront de la suivre à la trace. Et si l'identificateur stable est lié à la machine et pas à une de ses interfaces réseau, même un changement de WiFi à Ethernet ne suffira pas à échapper à la surveillance. C'était le cas par exemple du protocole de Dropbox qui incluait dans les messages diffusés un identificateur unique, choisi à l'installation et jamais changé ensuite. D'une manière générale, les identificateurs stables sont mauvais pour la vie privée, et devraient être utilisés avec prudence, surtout quand ils sont diffusés.
Ces identificateurs stables ne sont pas forcément reliés à
l'identité étatique de la personne. Si on ne connait pas la
sécurité, et qu'on ne sait pas la différence entre
anonymat et
pseudonymat, on peut penser que diffuser
partout qu'on est
88cb0252-3c97-4bb6-9f74-c4c570809432 n'est
pas très révélateur. Mais outre que d'avoir un lien entre
différentes activités est déjà un danger, certains protocoles font
qu'en plus ce pseudonyme peut être corrélé avec des informations
du monde extérieur. Par exemple, les iPhone
diffusent fièrement à tout le réseau local « je suis l'iPhone de
Jean-Louis » (cf. RFC 8117). Beaucoup d'utilisateurs donnent à leur machine leur
nom officiel, ou leur prénom, ou une autre caractéristique
personnelle. (C'est parfois fait automatiquement à l'installation,
où un programme demande « comment vous appelez-vous ? » et nomme
ensuite la machine avec ce nom. L'utilisateur n'est alors pas
conscient d'avoir baptisé sa machine.) Et des protocoles diffusent cette information.
En outre, cette information est parfois accompagnés de détails sur le type de la machine, le système d'exploitation utilisé. Ces informations peuvent permettre de monter des attaques ciblées, par exemple si on connait une vulnérabilité visant tel système d'exploitation, on peut sélectionner facilement toutes les machines du réseau local ayant ce système. Bref, le RFC conseille de ne pas diffuser aveuglément des données souvent personnelles.
Comme souvent, il faut aussi se méfier de la corrélation. Si
une machine diffuse des messages avec un identificateur stable
mais non parlant (qui peut donc être ce
700a2a3e-4cda-46df-ad6e-2f062840d1e3 ?), un
seul message donnant une autre information (par exemple nom et
prénom) est suffisant pour faire la corrélation et savoir
désormais à qui se réfère cet identificateur stable
(700a2a3e-4cda-46df-ad6e-2f062840d1e3, c'est
Jean-Louis). Lors de l'expérience à Prague citée plus haut, il
avait été ainsi possible aux chercheurs de récolter beaucoup
d'informations personnelles, et même d'en déduire une partie du
graphe social (la machine de Jean-Louis demande souvent en
mDNS celle de Marie-Laure, il doit y avoir
un lien entre eux).
La plupart des systèmes d'exploitation n'offrent pas la possibilité de faire la différence entre un réseau supposé sûr, où les machines peuvent diffuser sans crainte car diverses mesures de sécurité font que tout le monde n'a pas accès à ce réseau, et un réseau public complètement ouvert, genre le WiFi du McDo, où tout est possible. Il serait intéressant, affirme le RFC, de généraliser ce genre de service et d'être moins bavard sur les réseaux qui n'ont pas été marqués comme sûrs.
La section 3 du RFC note que certains points d'accès WiFi permettent de ne pas passer systématiquement la diffusion d'une machine à l'autre, et de ne le faire que pour des protocoles connus et supposés indispensables. Ainsi, les requêtes DHCP, terriblement indiscrètes, pourraient ne pas être transmises à tous, puisque seul le point d'accès en a besoin. Évidemment, cela ne marche que pour des protocoles connus du point d'accès, et cela pourrait donc casser des protocoles nouveaux (si on bloque par défaut) ou laisser l'utilisateur vulnérable (si, par défaut, on laisse passer).
En résumé (section 4 du RFC), les conseils suivants sont donnés aux concepteurs de protocoles et d'applications :
- Autant que possible, utiliser des protocoles normalisés, pour lesquelles une analyse de sécurité a été faite, et des mécanismes de limitation des risques développées (comme ceux du RFC 7844 pour DHCP),
- Essayer de ne pas mettre des informations venant de l'utilisateur (comme son prénom et son nom) dans les messages diffusés,
- Tâcher de ne pas utiliser d'identificateurs stables, puisqu'ils permettent de surveiller une machine pendant de longues périodes,
- Ne pas envoyer les messages trop souvent.
L'article seul
Passage de ce blog à Let's Encrypt
Première rédaction de cet article le 25 novembre 2018
Bon, comme la Terre entière, je suis passé à Let's Encrypt. Ce blog est désormais systématiquement en HTTPS pour tout le monde.
Il y a plus de quatre ans que ce blog est accessible en HTTPS, à la fois pour assurer la confidentialité (pas des réponses, puisque le contenu est public, mais des requêtes) et protéger contre toute modification en route. J'utilisais une autorité de certification gratuite, contrôlée par ses utilisateurs, et très simple à utiliser, CAcert. J'en suis satisfait mais CAcert n'est pas intégré dans le magasin de certificats de la plupart des systèmes d'exploitation et/ou navigateurs Web. (Alors que des AC gouvernementales ayant déjà émis des faux certificats y sont, mais c'est une autre histoire.)
Cette non-présence dans les magasins d'AC obligeait les
utilisateurs à ajouter CAcert manuellement, ce qu'évidemment peu
faisaient. Résultat, je ne pouvais pas publier un URL en
https:// sans recevoir des messages « c'est
mal configuré », et je ne pouvais pas utiliser de bonnes pratiques
comme de rediriger automatiquement les visiteurs vers la version
sûre. D'où ce passage de CAcert à
Let's Encrypt. La sécurité n'y
gagne rien, mais ce sera plus pratique pour les
utilisateurs. Notez que cela a des conséquences stratégiques pour
l'Internet : la quasi-totalité des sites Web non-commerciaux (et
beaucoup de commerciaux) utilisent la même AC, dont tout le monde
est désormais dépendant.
Bon, il y a quand même un petit progrès technique, CAcert ne permettait pas de signer les certificats utilisant la cryptographie à courbes elliptiques (RFC 8422), alors que Let's Encrypt le permet. Voici ce certificat ECDSA avec la courbe elliptique P256, vu par le journal crt.sh (cf. RFC 6962), ou bien vu par GnuTLS :
% gnutls-cli www.bortzmeyer.org
- Certificate type: X.509
- Certificate[0] info:
- subject `CN=www.bortzmeyer.org', issuer `CN=Let's Encrypt Authority X3,O=Let's Encrypt,C=US', serial 0x03ae1eb1664c8652d50d7213900d5c935dbe, EC/ECDSA key 256 bits, signed using RSA-SHA256, activated `2018-11-13 19:29:41 UTC', expires `2019-02-11 19:29:41 UTC', key-ID `sha256:74d7df20684d3854233db36258d327dfce956720b836fd1f2c17f7e67ae84db9'
Public Key ID:
sha1:45600c1f3141cf85db95f5dac74ec1066bafb5b9
sha256:74d7df20684d3854233db36258d327dfce956720b836fd1f2c17f7e67ae84db9
Public key's random art:
+--[SECP256R1]----+
| .+O+.... o.|
| o.*.. * .|
| . +o + +.|
| .. o o+.|
| S .o=|
| oo+|
| . o.|
| .|
| E |
+-----------------+
- Certificate[1] info:
- subject `CN=Let's Encrypt Authority X3,O=Let's Encrypt,C=US', issuer `CN=DST Root CA X3,O=Digital Signature Trust Co.', serial 0x0a0141420000015385736a0b85eca708, RSA key 2048 bits, signed using RSA-SHA256, activated `2016-03-17 16:40:46 UTC', expires `2021-03-17 16:40:46 UTC', key-ID `sha256:60b87575447dcba2a36b7d11ac09fb24a9db406fee12d2cc90180517616e8a18'
- Status: The certificate is trusted.
Le certificat a été généré par :
% openssl ecparam -out blog.pem -name prime256v1 -genkey
% openssl req -new -key blog.pem -nodes -days 1000 -subj '/CN=www.bortzmeyer.org' -reqexts SAN -config <(cat /etc/ssl/openssl.cnf <(printf "[SAN]\nsubjectAltName=DNS:www.bortzmeyer.org")) -out blog.csr
La solution simple pour la deuxième commande (openssl
req -new -key blog.pem -nodes -days 1000 -out blog.csr)
n'était pas bonne car elle ne met pas de SAN (Subject
Alternative Name) dans le CSR, ce qui perturbe
le client Let's Encrypt dehydrated.
La plupart des utilisateurs de Let's Encryt ne s'embêtent pas avec ces commandes OpenSSL. Ils utilisent un client Let's Encrypt comme certbot qui fait ce qu'il faut pour générer la CSR et la faire signer par l'AC Let's Encrypt. Je ne l'ai pas fait car je voulais contrôler exactement le certificat. J'ai choisi le client Let's Encrypt dehydrated. Après avoir vérifié la CSR :
% openssl req -text -in blog.csr
Certificate Request:
Data:
Version: 1 (0x0)
Subject: CN = www.bortzmeyer.org
Subject Public Key Info:
Public Key Algorithm: id-ecPublicKey
Public-Key: (256 bit)
pub:
04:34:ce:8a:50:e4:d0:bb:61:12:e6:39:98:cd:24:
13:59:47:83:bb:1c:5a:ae:96:be:49:d1:0f:cf:e0:
0b:96:b7:e6:fe:51:2c:ee:0f:bf:48:d4:73:5e:e5:
e5:79:0d:8e:f7:9b:5d:8d:d3:91:dd:fd:23:96:1f:
da:c2:46:03:b0
ASN1 OID: prime256v1
NIST CURVE: P-256
Attributes:
Requested Extensions:
X509v3 Subject Alternative Name:
DNS:www.bortzmeyer.org
...
J'ai fait signer mon certificat ainsi :
% dehydrated --signcsr ./blog.csr > blog.crt
Une des raisons pour lequelles je voulais contrôler de près le certificat était que je veux publier la clé publique dans le DNS (technique DANE, RFC 6698), DANE étant une meilleure technique de sécurisation des certificats. J'ai donc un enregistrement TLSA :
% dig TLSA _443._tcp.www.bortzmeyer.org
;; ->>HEADER<<- opcode: QUERY, status: NOERROR, id: 62999
;; flags: qr rd ra ad; QUERY: 1, ANSWER: 2, AUTHORITY: 7, ADDITIONAL: 17
...
;; ANSWER SECTION:
_443._tcp.www.bortzmeyer.org. 86400 IN TLSA 1 1 1 (
74D7DF20684D3854233DB36258D327DFCE956720B836
FD1F2C17F7E67AE84DB9 )
_443._tcp.www.bortzmeyer.org. 86400 IN RRSIG TLSA 8 5 86400 (
20181206024616 20181121161507 50583 bortzmeyer.org.
w04TM3ZKesaNrFrJMs9w4B8/V+vHDnaUxfO2lWlQTHZH
...
Et évidemment je l'ai testé avant de publier cet article :
% tlsa --verify www.bortzmeyer.org
SUCCESS (Usage 1 [PKIX-EE]): Certificate offered by the server matches the one mentioned in the TLSA record and chains to a valid CA certificate (204.62.14.153)
SUCCESS (Usage 1 [PKIX-EE]): Certificate offered by the server matches the one mentioned in the TLSA record and chains to a valid CA certificate (2001:4b98:dc0:41:216:3eff:fe27:3d3f)
SUCCESS (Usage 1 [PKIX-EE]): Certificate offered by the server matches the one mentioned in the TLSA record and chains to a valid CA certificate (2605:4500:2:245b::42)
(On peut aussi tester
en ligne.) L'usage de DANE nécessite de ne pas changer la
clé publique à chaque renouvellement du certificat (ce que fait
dehydrated par défaut). J'ai donc mis dans
/etc/dehydrated/config :
PRIVATE_KEY_RENEW="no"
Let's Encrypt impose une durée de validité de trois mois pour le certificat. C'est court. Cela veut dire que le renouvellement doit être automatique. Par exemple, on met typiquement dans la configuration de cron un :
dehydrated --cron --hook /etc/dehydrated/hook.sh
Et tous les jours (dans mon cas), dehydrated va tourner, regarder
les certificats dont l'expiration est dans moins de N jours
(cf. paramètre RENEW_DAYS dans la
configuration de dehydrated), les
renouveller auprès de l'AC et exécuter les commandes situées dans /etc/dehydrated/hook.sh.
De nombreux sites Web utilisant Let's Encrypt ont eu
la mauvaise surprise de découvrir au bout de trois mois que leur
certificat était expiré parce que le renouvellement n'avait pas
marché (cron pas configuré, ou bien mal configuré). Le problème
est d'autant plus fréquent que le discours « marketing » disant
« Let's Encrypt, c'est super, tout est automatique » affaiblissait
la vigilance des administrateurs
système. Il est donc crucial, en plus de bien
configurer son cron, de superviser l'expiration de ces
certificats. Par exemple, ma configuration
Icinga contient, entre autres :
vars.http_vhosts["blog-cert"] = {
http_uri = "/"
http_vhost = "www.bortzmeyer.org"
http_ssl = true
http_ssl_force_tlsv1_1_or_higher = true
http_sni = true
http_certificate = "7,4"
}
Avec cette règle, Icinga envoie un avertissement s'il reste moins de sept jours, et une alarme critique s'il reste moins de quatre jours de vie au certificat. De même, on doit superviser DANE.
Comme certains visiteurs du site Web essaient d'abord en HTTP
(sans TLS), et comme les anciens liens en
http:// ne vont pas disparaitre du jour au
lendemain, j'ai également mis en place une redirection, utilisant
le code de retour HTTP 301
(RFC 7231, section 6.4.2). Dans la configuration
d'Apache, cela donne :
<VirtualHost *:80>
ServerName www.bortzmeyer.org
Redirect permanent / https://www.bortzmeyer.org/
</VirtualHost>
La redirection elle-même n'est pas sécurisée puisqu'on se connecte d'abord au serveur sans la protection qu'offre TLS. IL est donc prudent d'utiliser également HSTS (RFC 6797), pour dire « utilisez HTTPS systématiquement, dès le début ; je m'engage à ce qu'il reste actif ». Dans Apache, cela se fait avec :
Header set Strict-Transport-Security "max-age=7776000; includeSubDomains"
Comme tout le monde, j'ai testé la configuration TLS avec SSLlabs, CryptCheck et Internet.nl. Un peu de gamification : SSLlabs me donne un A. CryptCheck me donne également un A (et me fait remarquer j'autorise le vieux TLS 1.0). SSLlabs, comme Internet.nl, me reprochent la durée trop courte de HSTS (c'est encore un peu expérimental).
À noter que j'ai conservé CAcert pour les serveurs SMTP (pour lesquels on ne peut pas valider facilement avec Let's Encrypt, et, de toute façon, les serveurs SMTP ont en général des certificats tellement problématiques que DANE - RFC 7672 - est la seule façon de les sécuriser). Même chose pour des sites internes, non accessibles depuis l'Internet et donc non vérifiables par l'AC Let's Encrypt.
Le remplacement automatique du certificat posait un autre
problème : ce blog, www.bortzmeyer.org est
sur deux serveurs (trois
adresses IP en tout). Il fallait donc recopier le nouveau
certificat sur tous les serveurs. (Mais pas la clé privée qui,
elle, est stable.) D'abord, j'ai choisi quel serveur ferait
tourner dehydrated et donc recevrait le nouveau
certificat. Ensuite, Let's Encrypt vérifie l'identité du serveur
par un système de défi : lorsqu'il
est sollicité (via le protocole ACME, normalisé dans le RFC 8555),
Let's Encrypt génère un texte imprévisible qu'il envoie au
client. Celui-ci doit alors le déposer à un endroit où Let's
Encrypt pourra le récupérer. Donc, si une machine demande à l'AC Let's Encrypt un
certificat pour www.bortzmeyer.org, Let's
Encrypt va chercher si le texte est bien sur
https://www.bortzmeyer.org/.well-known/acme-challenge. Le
client prouve ainsi qu'il est légitime, qu'il peut recevoir les requêtes HTTP envoyées au
nom. Le problème est que Let's Encrypt risque de se connecter sur
un autre serveur que celui où le texte imprévisible a été
déposé.
Pour éviter cela, j'ai configuré les autres serveurs pour
relayer les requêtes HTTP
allant vers .well-known/acme-challenge en
direction du serveur qui fait tourner dehydrated. Avec
Apache, cela se fait avec le module mod_proxy :
ProxyRequests Off ProxyPass /.well-known/acme-challenge/ https://ACME-MACHINE.bortzmeyer.org/.well-known/acme-challenge/ ProxyPreserveHost On
Cela permet à la machine qui lance dehydrated de toujours recevoir les requêtes de vérification, et donc de récupérer le certificat.
(Notez que la vérification par Let's Encrypt de l'identité du demandeur ne se fait pas forcément en HTTP. On peut aussi utiliser le DNS, ce qui serait une piste intéressante à explorer. Il y a aussi une méthode basée sur ALPN.)
Il reste ensuite à recopier le certificat nouvellement acquis sur tous les serveurs. J'ai utilisé SSH pour cela, avec du scp vers un compte sans mot de passe. Sur les serveurs Web, on crée le compte, et les répertoires où on copiera le certificat :
% sudo adduser copykey % sudo -u copykey mkdir ~copykey/keys % sudo -u copykey chmod 700 ~copykey/keys
Sur la machine ACME (celle où il y a dehydrated), on crée une clé SSH sans mot de passe (puisque tout doit pouvoir tourner depuis cron, pas d'interactivité) :
% ssh-keygen -t ed25519 -P ""
Et sur le serveur Web, on autorise les connexions depuis le
détenteur de cette clé (root, a priori), mais
seulement avec la commande scp vers le bon répertoire. On met dans
~copykey/.ssh/authorized_keys :
command="/usr/bin/scp -t keys",restrict ssh-ed25519 AAAAC3Nza... root@acme-machine
(Notez, et c'est amusant, que l'option -t
indiquant le répertoire n'est apparemment pas
documentée.)
Il reste alors, dans le fichier
/etc/dehydrated/hook.sh, où se trouvent les
commandes à exécuter lorsque le certificat est renouvellé, à
effectuer la copie vers les serveurs Web :
function deploy_cert {
...
for server in ${WEBSERVERS}; do
scp /var/lib/dehydrated/certs/www.bortzmeyer.org/* ${REMOTEACCOUNT}@${server}:keys
done
}
Enfin, dernière étape, les fichiers (notamment le certificat) ont
été copiés sur le serveur Web mais il reste à les mettre là où le
serveur les attend et à dire au serveur HTTP
d'en tenir compte. On aurait pu copier les fichiers directement
dans le répertoire final mais il aurait fallu être
root pour cela et je n'avais pas envie de
mettre PermitRootLogin yes dans le
sshd_config, pour des raisons de sécurité. On
copie donc vers un compte ordinaire (le
copykey vu plus haut) et root sur le serveur
Web a une tâche lancée par cron qui récupère
les fichiers et relance le serveur HTTP :
% cat /etc/cron.d/copykeys
# Look for and copy TLS keys every 5 minutes
3-58/5 * * * * root /usr/local/sbin/copy-keys.sh
% cat /usr/local/sbin/copy-keys.sh
#!/bin/sh
OLDFILE=/etc/ssl/certs/www.bortzmeyer.org.fullchain.pem
NEWFILE=/home/copykey/keys/fullchain.pem
PATH=/sbin:/usr/sbin:${PATH}
OLDHASH=$(sha256sum ${OLDFILE} | cut -d' ' -f1)
if [ -z "${OLDHASH}" ]; then
echo "Cannot find ${OLDFILE}" >&2
exit 1
fi
NEWHASH=$(sha256sum ${NEWFILE} 2> /dev/null | cut -d' ' -f1 )
if [ ! -z "${NEWHASH}" ] && [ "${OLDHASH}" != "${NEWHASH}" ]; then
cp -v ${NEWFILE} ${OLDFILE}
apache2ctl graceful
fi
L'article seul
RFC 8404: Effects of Pervasive Encryption on Operators
Date de publication du RFC : Juillet 2018
Auteur(s) du RFC : K. Moriarty (Dell EMC), A. Morton
(AT&T Labs)
Pour information
Première rédaction de cet article le 23 novembre 2018
La vie privée sur l'Internet fait aujourd'hui l'objet d'innombrables attaques et l'une des techniques de défense les plus efficaces contre ces attaques est le chiffrement des données. Il protège également contre une autre menace, la modification des données en transit, comme le font certaines FAI (par exemple Orange Tunisie). Il y a de nombreuses campagnes de sensibilisation pour promouvoir le chiffrement (voir par exemple le RFC 7258), avec des bons résultats. Évidemment, ce chiffrement gène ceux qui voudraient espionner et modifier le trafic, et il fallait donc s'attendre à voir une réaction. Ce RFC est l'expression de cette réaction, du côté de certains opérateurs réseau, qui regrettent que le chiffrement empêche leurs mauvaises pratiques.
Dès le début, ce RFC était basé sur une hypocrisie : prétendre être purement descriptif (une liste de pratiques que certains opérateurs réseau utilisent, et qui sont impactées par le chiffrement), sans forcément en conclure que le chiffrement était mauvais. Mais, en réalité, le RFC porte un message souvent répété : le chiffrement gène, et il ne faudrait pas en abuser. On note par exemple que le RFC ne s'indigne pas de certaines des pratiques citées, alors que beaucoup sont scandaleuses. Le discours est « il faut trouver un équilibre entre la protection de la vie privée et la capacité des opérateurs à gérer leurs réseaux ». Une telle référence à l'équilibre m'a toujours énervé : non, il ne faut pas d'équilibre entre le bien et le mal, il faut faire ce qu'on peut pour gêner la surveillance. Certaines des pratiques citées dans le RFC sont mauvaises et tant mieux si le chiffrement les rend difficiles. Certaines autres sont plus neutres, mais devront quand même s'adapter, les révélations de Snowden ont largement montré que la surveillance de masse est un fait, et qu'elle justifie des mesures radicales de protection. (Notez que les premières versions de ce RFC étaient bien pires, et qu'il a été affadi par les discussions successives, et suite à l'opposition rencontrée.)
Hypocritement, les textes sacrés comme le RFC 1958, RFC 1984, RFC 2804, et bien sûr les RFC 7258 et RFC 7624 sont cités, hommage du vice à la vertu. Mais tout en le faisant, ce nouveau RFC 8404 déforme ces textes. Quand le RFC 7258 dit qu'évidemment, il faut que les opérateurs puissent continuer à gérer leurs réseaux, ce RFC 8404 lui fait dire qu'il faut donc limiter le chiffrement, comme si « gérer un réseau » voulait forcément dire « accéder aux communications ». De même, on trouve une référence au principe de bout en bout (RFC 2775, RFC 3724, RFC 7754), alors même que le reste de ce RFC ne fait que citer des pratiques violant ce principe.
Ce RFC 8404 se veut, on l'a dit, une description de pratiques actuelles, et prétend hypocritement « ne pas forcément soutenir toutes les pratiques présentées ici ». En effet, tous les exemples cités par la suite sont réellement utilisées mais pas forcément par tous les opérateurs. C'est une des choses les plus désagréables de ce RFC que de laisser entendre que tous les opérateurs seraient unanimes dans leur désir de lire les communications de leurs clients, voire de les modifier. (Par exemple en utilisant le terme tribal de community pour parler des opérateurs réseau, comme s'ils étaient un clan unique, d'accord sur l'essentiel.)
Il est exact qu'au début de l'Internet, rien ou presque n'était chiffré. Tout circulait en clair, en partie parce que la perte de performances semblait excessive, en partie parce que les États faisaient tout pour décourager le chiffrement et limiter son usage, en partie parce que la menace semblait lointaine (même les plus paranoïaques des experts en sécurité ne se doutaient pas que la surveillance atteignait les proportions révélées par Snowden.) Certains opérateurs ont alors pris de mauvaises habitudes, en examinant en détail les communications, à des fins plus ou moins innocentes. Les choses changent aujourd'hui, avec un déploiement plus important du chiffrement, et ces mauvaises pratiques doivent donc disparaitre, ce que les auteurs du RFC ont du mal à avaler.
Des premiers exemples de ces mauvaises pratiques sont données
en section 1.2. Par exemple, le RFC cite un rapport
de l'EFF montrant que certains opérateurs inséraient des
données dans les flux SMTP, notamment à des
fins de suivi des utilisateurs, et, pour empêcher ces flux d'être
protégés par TLS, retiraient la commande
STARTTLS de la négociation (ce qu'on nomme le
SSL stripping, cf. RFC 7525, section 3.2). Le RFC ose même dire que pour
certains, c'était « considéré comme une attaque » comme si cela
n'était pas évident que c'est une attaque ! Notant que le
chiffrement systématique empêcherait cette attaque, le RFC demande
qu'on fournisse à ces opérateurs réseau malhonnêtes une
alternative à leurs pratiques de piratage des sessions !
Un autre exemple donné est celui des réseaux d'entreprise où il y a, dit le RFC, un « accord » pour que le contenu du trafic des employés soit surveillé par le patron (dans la réalité, il n'y a pas d'accord, cette surveillance est une condition de l'embauche). Ce serait donc un cas radicalement différent de celui des réseaux publics, via le FAI, où il n'y a pas de tel « accord » et, pourtant, déplore le RFC, le chiffrement rend cette surveillance plus difficile. (Ce point particulier a fait l'objet de nombreux débats lors de la mise au point de la version 1.3 du protocole TLS, qui visait en effet à rendre la surveillance plus difficile. Cf. RFC 8446.)
À partir de la section 2, commence le gros du RFC, les études de cas. Le RFC est très détaillé et je ne vais pas tout mentionner ici. Notons que la section 2 commence par du chantage : si on ne donne pas accès aux opérateurs au contenu des communications, ils « vont déployer des méthodes regrettables du point de vue de la sécurité », et il faut donc leur donner les données, pour éviter qu'ils n'utilisent des moyens encore pires.
D'abord, ce sont les chercheurs qui effectuent des mesures sur l'Internet (par exemple CAIDA) qui sont mentionnés pour expliquer que le chiffrement va rendre ces études bien plus difficiles. (Au passage, puisque le RFC ne le dit pas, signalons que la science ne justifie pas tout et que ces études doivent se conformer à l'éthique, comme tout le monde.) Le RFC oublie de dire que beaucoup de ces études n'utilisent que l'en-tête IP, et parfois les en-têtes TCP et UDP, qui ne sont pas affectés par le chiffrement. Comme cette réthorique est souvent présente dans ce RFC, cela vaut la peine de préciser : les techniques de chiffrement les plus déployées aujourd'hui (TLS et, loin derrière, SSH) laissent intacts les en-têtes IP et TCP, que les chercheurs peuvent donc regarder comme avant. IPsec, lui, masque l'en-tête TCP (et, dans certains cas, une partie de l'information venue de l'en-tête IP), mais il est très peu utilisé dans l'Internet public (à part une partie de l'accès au VPN de l'entreprise). QUIC, s'il sera un jour déployé massivement, dissimulera également une partie de l'information de couche 4. Bref, aujourd'hui, la partie en clair du trafic donne déjà plein d'information.
Après les chercheurs, le RFC cite les opérateurs qui regardent en détail un flux réseau pour déboguer des problèmes applicatifs. Là encore, l'exemple est très malhonnête :
- Comme indiqué ci-dessus, la partie non chiffrée du paquet reste accessible. Si on veut déboguer des problèmes TCP subtils, du genre la fenêtre qui ne s'ouvre pas assez, même si TLS est utilisé, l'information TCP complète reste disponible, avec la taille de la fenêtre, les numéros de séquence et tout le toutim.
- Mais, surtout, quel opérateur réseau débogue ainsi les problèmes applicatifs de ces clients ? Vous croyez vraiment que M. Michu, client d'un FAI grand public, va pouvoir solliciter l'aide d'un expert qui va lancer Wireshark pour résoudre les problèmes WebRTC de M. Michu ? (C'est l'exemple donné par le RFC : « ma vidéo haute définition est hachée ». S'il existe un FAI dont le support accepte de traiter ce genre de problèmes, je veux bien son nom.)
- Dans des discussions privées, on m'a parfois dit qu'il ne s'agissait pas de FAI grand public, qui ne passeront en effet jamais du temps sur ces problèmes, mais d'opérateurs ayant une clientèle de grandes entreprises, pour lesquelles ils jouent un rôle de conseil et d'assistance sur les problèmes réseaux. Mais, si le client est volontaire, et veut vraiment qu'on l'aide, rien ne l'empêche de couper le chiffrement ou de demander aux applications d'afficher de l'information de débogage détaillée.
Le RFC ne mentionne pas assez que le développement du chiffrement est en bonne partie le résultat des pratiques déplorables de certains opérateurs. Si on fait tout passer sur le port 443 (celui de HTTPS), et en chiffré, c'est précisément parce que des opérateurs se permettaient, en violation du principe de neutralité, de traiter différemment les applications, se fiant au port TCP utilisé pour reconnaitre les différentes applications. Refusant de comprendre ce problème, le RFC déplore au contraire que « tout le monde étant sur le port 443, on ne peut plus détecter certains applications afin de les prioriser », et affirme que cela justifie le DPI. Pas un seul questionnement sur la légitimité de ce traitement différencié. (Notez également un truc réthorique très malhonnête : parler de prioriser certaines applications. Comme la capacité du réseau est finie, si on en priorise certaines applications, on en ralentit forcément d'autres. Mais c'est plus vendeur de dire qu'on priorise que d'admettre qu'on discrimine.) Pour éviter de dire ouvertement qu'on viole la neutralité du réseau, le RFC la redéfinit en disant qu'il n'y a pas violation de la neutralité si on différencie entre applications, seulement si on différencie entre utilisateurs.
Il n'y a évidemment pas que les opérateurs réseau qui sont responsables de la surveillance et de l'interférence avec les communications. La section 2.4 du RFC rappelle à juste titre que les opérateurs travaillent dans un certain cadre légal et que l'État les oblige souvent à espionner (ce qui s'appelle en novlangue « interception légale ») et à censurer. Par exemple, en France, les opérateurs sont censés empêcher l'accès aux sites Web présents sur la liste noire (secrète) du ministère de l'intérieur. Le chiffrement rend évidemment plus difficile ces activités (c'est bien son but !) Le RFC note par exemple que le filtrage par DNS menteur, la technique de censure la plus commune en Europe, est plus difficile si on utilise le chiffrement du RFC 7858 pour parler à un résolveur DNS externe, et traite cela comme si c'était un problème, alors que c'est au contraire le résultat attendu (s'il n'y avait pas de surveillance, et pas d'interférence avec le trafic réseau, le chiffrement serait inutile).
Mais le RFC mélange tout par la suite, en citant comme exemple de filtrage légitime le contrôle parental. Il n'y a nul besoin qu'il soit fait par le FAI, puisqu'il est souhaité par le client, il peut être fait sur les machines terminales, ou dans le routeur de la maison. C'est par exemple ce qui est fait par les bloqueurs de publicité, qui ne sont pas une violation de la neutralité du réseau puisqu'ils ne sont pas dans le réseau, mais sur la machine de l'utilisateur, contrôlée par elle ou lui.
Un autre exemple où le RFC déplore que le chiffrement empêche une pratique considérée par l'opérateur comme utile est celui du zero rating, cette pratique où l'accès à certains services fait l'objet d'une tarification réduite ou nulle. Le chiffrement, note le RFC, peut servir à dissimuler les services auxquels on accède. Là encore, on peut se demander si c'est vraiment un problème : le zero rating est également une violation de la neutralité du réseau, et ce n'est pas forcément mauvais qu'il devienne plus difficile à déployer.
Mais l'exemple suivant est bien pire, et beaucoup plus net. La section 2.3.4 du RFC décrit la pratique de modification des flux HTTP, notamment l'insertion d'en-têtes. Plusieurs vendeurs de matériel fournissent des équipements permettant d'« enrichir » les en-têtes, en ajoutant des informations personnelles, comme le numéro de téléphone, permettant un meilleur ciblage par les publicitaires. Et ils n'en ont même pas honte, annonçant cyniquement cette capacité dans leurs brochures. Et le RFC décrit cette pratique en termes neutres, sans préciser qu'elle est mauvaise, devrait être interdite, et que le chiffrement permet heureusement de la rendre plus difficile ! La soi-disant neutralité de la description mène donc à décrire des pratiques scandaleuses au même niveau que l'activité normale d'un opérateur réseaux. Le RFC cite bien le RFC 8165, qui condamne cette pratique, mais n'en tire pas les conséquences, demandant, là encore, qu'on fournisse aux opérateurs malhonnêtes un moyen de continuer ces opérations (par exemple par une insertion des données personnelles directement par le logiciel sur la machine du client, ce qui est possible dans le monde du mobile, beaucoup plus fermé et contrôlé), et ce malgré le chiffrement.
La section 3.1.2 du RFC revient sur les buts de la surveillance, lorsqu'on gère un réseau. Elle mentionne plusieurs de ces buts, par exemple :
- Détection de logiciel malveillant. À noter que lui, de toute façon, ne va pas se laisser arrêter par une interdiction du chiffrement.
- Conformité avec des règles imposant la surveillance, qui existent par exemple dans le secteur bancaire. On pourrait garder le chiffrement de bout en bout tout en respectant ces règles, si chaque application enregistrait toutes ses communications. C'est évidemment la bonne solution technique (section 3.2.1 du RFC) mais, à l'heure actuelle, beaucoup de ces applications sont fermées, n'enregistrent pas, et ne permettent pas de traçabilité. (Notons aussi que des normes comme PCI imposent la traçabilité, mais n'imposent pas d'utiliser du logiciel libre, ce qui est assez incohérent. La quadrature du cercle - sécuriser les communications contre l'écoute, tout en permettant l'audit - n'est soluble qu'avec des applications qu'on peut examiner, et qui enregistrent ce qu'elles font.)
- Opposition à la fuite de données. La « sécurité » souvent mentionnée est en fait un terme vague recouvrant beaucoup de choses. La sécurité de qui et de quoi, faut-il se demander. Ici, il est clair que le patronat et l'État voudraient rendre plus difficile le travail de lanceurs d'alerte, par exemple WikiLeaks. En France, une loi sur « le secret des affaires » fournit aux entreprises qui veulent dissimuler leurs mauvaises actions une défense juridique contre la vérité. La limitation du chiffrement vise à ajouter une défense technique, pour empêcher le ou la lanceur d'alerte d'envoyer des informations discrètement au Canard enchaîné.
La section 3.2 du RFC mentionne d'autres exemples d'usages actuels que le chiffrement massif peut gêner. Par exemple, elle cite la lutte contre le spam en notant que le chiffrement du courrier (par exemple avec PGP ou DarkMail) empêche un intermémdiaire (comme le serveur de messagerie) de lutter contre le spam. (La bonne solution est évidemment de faire l'analyse du spam sur la machine finale, par exemple avec bogofilter.)
Les révélations de Snowden ont montré que l'espionnage des liaisons internes aux organisations était une pratique courante de la NSA. Pendant longtemps, beaucoup d'administrateurs réseau ont considéré que « pas besoin d'utiliser HTTPS, c'est un site Web purement interne ». C'était une grosse erreur technique (l'attaquant est souvent interne, et les attaques contre le DNS ou le routage peuvent donner accès aux communications censées être internes) et elle a donc logiquement été exploitée. Aujourd'hui, les organisations sérieuses chiffrent systématiquement, même en interne.
Mais en même temps, beaucoup d'entreprises ont en interne des règles qui autorisent la surveillance de toutes les communications des employés. (En France, il existe des limites à cette surveillance, mais pas aux États-Unis. Le RFC rappelle juste que certaines politiques définies par le patron autorisent des accès protégés contre la surveillance, par exemple pour se connecter à sa banque. Écrit avec un point de vue très états-unien, le RFC ne mentionne que les politiques de la direction, pas les limites légales.) Techniquement, cela passe, par exemple, par des relais qui terminent la session TLS, examinent le contenu de la communication, puis démarrent une nouvelle session avec le serveur visé. Cela permet par exemple de détecter le logiciel malveillant que la machine Windows télécharge via une page Web piégée. Ou bien une attaque XSS que l'utilisateur n'a pas vue. (Notez que, par une incohérence fréquente en entreprise, la sécurité est présentée comme absolument essentielle, mais les postes de travail tournent sur Windows, certainement la cible la plus fréquente de ces logiciels malveillants.) Mais cela permet aussi de surveiller les communications des employés.
Si le but est de se protéger contre le logiciel malveillant, une solution simple est de faire l'examen des messages suspects sur la machine terminale. Cela peut être plus compliqué à déployer mais, normalement, c'est faisable à la fois juridiquement puisque cette machine appartient à l'entreprise, et techniquement puisqu'elle est a priori gérée à distance.
La section 5 du RFC détaille certaines techniques de surveillance pour des systèmes particuliers. Par exemple, les fournisseurs de messagerie examinent les messages, notamment pour déterminer s'il s'agit de spam. SMTP sur TLS ne gêne pas cette technique puisqu'il est de serveur à serveur, pas de bout en bout. Même PGP ou S/MIME n'empêchent pas l'examen des métadonnées, qui peuvent être suffisante pour détecter le spam.
De même (section 6 du RFC), TLS ne masque pas tout et permet quand même certaines activités de surveillance. Ainsi, le nom du serveur contacté, indiqué dans l'extension TLS SNI (Server Name Indication, section 3 du RFC 6066) n'est pas chiffré et peut donc être vu. (Des efforts sont en cours actuellement à l'IETF pour boucher cette faille dans la protection de la vie privée, et semblent bien avancer.)
En résumé, ce RFC, qui a commencé comme très « anti-chiffrement » a été un peu modifié lors des très vives discussions qu'il a généré à l'IETF, et essaie désormais de ménager la chèvre et le chou. La tonalité demeure quand même hostile au chiffrement sérieux, mais on y trouve suffisamment d'éléments techniques précis pour que tout le monde puisse y trouver une lecture intéressante.
L'article seul
« Logiciel libre » et « Open Source », c'est pareil ou pas ?
Première rédaction de cet article le 21 novembre 2018
Dernière mise à jour le 22 novembre 2018
On entend parfois, dans les discussions autour des licences logicielles, des affirmations du genre « tel logiciel n'est pas libre mais il est open source ». Quelle est la différence ? Y en a-t-il une, d'ailleurs ?
Commençons par les textes originaux. Le concept de logiciel libre a été popularisé par Richard Stallman et la Free Software Foundation. Le logiciel libre se définit par quatre libertés :
- Liberté de faire tourner le logiciel, c'est-à-dire de l'utiliser à des fins quelconques.
- Liberté d'étudier le programme, ce qui implique notamment l'accès à son code source.
- Liberté de distribuer des copies du logiciel,
- y compris des copies modifiées.
On notera que la gratuité n'est pas mentionnée. En anglais, le terme de free software a parfois engendré des malentendus, free pouvant vouloir dire « libre » mais aussi « gratuit ». Comme souvent en politique, ces malentendus étaient parfois de bonne foi, et malhonnêtes dans d'autres, certains faisant semblant de ne pas comprendre que la liberté n'a rien à voir avec la gratuité.
Stallman aime donc répéter que, dans free software, c'est free as in free speech, not free as in free beer. Bonne explication, mais difficile à traduire en français puisque, justement, en français, il y a deux mots différents pour « libre » et « gratuit ».
Et open source ? Notons que ce n'est pas un hasard si le terme en anglais est populaire chez les gens dont le métier est d'embrouiller le langage, les vendeurs ou les politiciens, par exemple. Utiliser un terme en anglais permet de rester dans le flou, et d'essayer de plaire à tout le monde, en n'utilisant pas de termes précis. Le terme a été popularisé par Eric Raymond et quelques autres en 1998. Ils avançaient deux arguments essentiels en faveur de ce nouveau terme : l'ambiguité entre « libre » et « gratuit » (qui, on l'a vu, n'existe pas en français, rendant tout à fait inutile l'utilisation du terme open source), et surtout le fait que la liberté faisait peur, notamment au patronat, et que, si on voulait populariser le logiciel libre auprès des gens qui ont la main sur la carte de crédit de l'entreprise, il fallait changer le nom. (Il y avait bien sûr également des raisons non avouées, comme essayer de remplacer Stallman au poste de symbole du logiciel libre.)
Le terme a clairement été un grand succès, malgré le fait qu'il soit tout aussi ambigu que l'autre (open source ou « source ouverte » désignait déjà tout à fait autre chose). Que mettaient-ils derrière ce terme ? Les promoteurs du terme open source ont produit une définition. Elle est moins percutante que les « quatre libertés », et plus longue, mais elle revient quasiment au même. Notamment, elle précise clairement qu'open source ne veut pas uniquement dire qu'on a accès au code source.
Les deux définitions sont très proches, justifiant que Stallman, paraphrasant Shakespeare, rappelle que « un logiciel libre, sous un autre nom, serait tout aussi libre ». N'est-ce donc qu'une question de terminologie, sans conséquences pratiques ?
Si on regarde la liste des licences libres reconnues par la FSF, et qu'on la compare avec celle des promoteurs du terme open source, on ne voit en effet pas de différence. On cite parfois la question de l'obligation de réciprocité (copyleft en anglais, ou « partage à l'identique » - Share Alike - dans les licences Creative Commons) comme différence entre logiciel libre et open source. Mais cette distinction n'est jamais faite par des gens qui participent au logiciel libre, elle n'arrive que dans des raccourcis médiatiques. L'obligation de réciprocité (un individu ou une entreprise peuvent distribuer le logiciel, même modifié, et même le vendre, mais on a l'obligation de reconnaitre au destinataire les mêmes libertés que celles dont ils ont bénéficié) n'est en effet pas mentionnée dans les quatre libertés qui définissent le logiciel libre. Les personnes qui ne se sont pas renseignées avant et qui disent que le logiciel libre requiert l'obligation de réciprocité sont donc plus stricts sur la définition que Richard Stallman lui-même, alors qu'il est généralement considéré comme un modèle de strictitude.
Bien qu'il existe des cas compliqués de licences qui peuvent être vues comme libres selon une définition et pas selon une autre, ces cas sont très marginaux. L'immense majorité des logiciels libres est sous une licence que les deux définitions classent comme libre. Parmi les exceptions, on note (trouvée par Exagone313) l'amusante licence Foutez ce que vous voulez, apparemment refusée par l'Open Source Initiative mais acceptée par la FSF. Mais elle est peu utilisée. (Si vous avez d'autres références précises d'une exception, d'une licence qui est dans une des listes de licences libres mais pas dans l'autre, je suis preneur. En indiquant des logiciels qui utilisent cette licence, car la plupart des licences candidates pour cet exercice sont peu ou pas utilisées.)
Cette rareté des licences acceptées sous une définition mais pas sous l'autre semble plaider pour une conclusion simple « logiciel libre ou open source, on s'en fiche, c'est pareil ».
À noter que Wikipédia reprend cette définition : « La désignation open source, ou "code source ouvert", s'applique aux logiciels (et s'étend maintenant aux œuvres de l'esprit) dont la licence respecte des critères précisément établis par l'Open Source Initiative, c'est-à-dire les possibilités de libre redistribution, d'accès au code source et de création de travaux dérivés. » Et ajoute « La différence formelle entre open source et logiciel libre (en anglais : free software) n'a quasiment pas de conséquence dans l'évaluation des licences. » (Le bandeau en haut de l'article dit « Ne doit pas être confondu avec Logiciel libre », alors même que l'article explique que c'est pareil...) Le Wiktionnaire dit également que les deux termes sont synonymes.
Mais, évidemment, en matière de langage, les arguments d'autorité et les références aux textes antiques ont leurs limites. Le langage évolue (pas toujours dans le bon sens) et ce qui est important, c'est aussi ce que veulent dire les gens. L'usage compte. Ceux et celles qui utilisent le terme open source veulent-ils dire la même chose que celles et ceux qui disent logiciel libre ? Il est difficile de répondre à cette question. En effet, si on n'utilise pas la définition « officielle », laquelle utilise-t-on ? J'ai la nette impression que les gens qui utilisent open source n'ont pas de définition précise et l'utilisent un peu au petit bonheur la chance. Quand on demande à quelqu'un qui a utilisé le terme open source ce qu'ielle entend par là, on reçoit en général une réponse vague, et souvent fausse (comme par exemple de définir open source par « accès au code source »). Les commerciaux utilisent ce terme pour dire « logiciel libre » mais en moins politique (la liberté, ça fait peur aux clients), les journalistes l'utilisent parce que dans un article sur l'informatique, il faut mettre de l'anglais, beaucoup de gens répètent simplement le terme qu'ils ont entendu dans les médias, sans réfléchir. Si on veut une définition fondée sur l'usage (et non pas sur la définition formelle de l'OSI), on pourrait arriver à quelque chose du genre « quelque chose qui va du logiciel libre [inclus] à diverses formes de logiciels privateurs manifestant un peu d'ouverture ».
En conclusion et résumé :
- « Logiciel libre » et « Open Source » désignent quasiment exactement les mêmes licences et donc les mêmes logiciels. Il n'y a donc pas de différence pratique.
- Mais dans l'usage, la plupart des emplois de « Open Source » désignent quelque chose de vague et de pas bien défini.
- Et les mots sont importants : utiliser « Open Source » n'est pas neutre et veut dire en général qu'on n'est pas spécialement attaché à la liberté.
L'article seul
Capitole du Libre 2018 (et mon exposé sur « Internet et les droits humains »)
Première rédaction de cet article le 19 novembre 2018
Dernière mise à jour le 26 novembre 2018
Les 17 et 18 novembre 2018, c'était Capitole du Libre, grand rassemblement annuel de centaines de libristes à Toulouse, dans les locaux de l'ENSEEIHT. À cette occasion, j'y ai fait un exposé sur le thème « Internet et les droits humains, il y a vraiment un rapport ? ».
Si vous voulez lire les supports de cet exposé, il y a une version PDF pour lire sur écran, et une version PDF pour imprimer. Le tout est évidemment sous une licence libre (celle de ce blog, la GFDL) et vous pouvez diffuser et/ou modifier le tout. Si vous voulez le modifier, le source est en LaTeX/Beamer et cette version est disponible également.
Une excellente transcription de mon intervention a été réalisée par l'APRIL, et est disponible sur leur site.
L'exposé a été filmé et la vidéo est disponible via PeerTube, sur l'instance de Jacques ou sur l'instance Vidéos du Libre. (Également sur YouTube, avec les autres vidéos de Capitole du Libre, si vous préferez donner vos données personnelles à Google.)
Ah, et c'était la première annonce publique de mon livre « Cyberstructure ».
Il y avait plein d'autres exposés à Capitole du Libre, dont beaucoup étaient passionnants. Mon préféré était celui de Vincent Privat, sur « André Cros, import Wikimedia d'un fonds d'archive exceptionnel de Toulouse ». André Cros était photographe à Sud Ouest pendant de nombreuses années et a transmis ses photos, avec les droits, à la Mairie de Toulouse, qui est partenaire de Wikimedia. Cela permettait juridiquement de tout mettre sur Wikimedia Commons, avec une licence libre. Les photos étaient déjà numérisées. Il a fallu développer un petit script pour envoyer les photos sur Wikimedia Commons et, surtout, étiqueter et classer chaque photo. On y trouve, entre autre, le premier vol du Concorde, un passage de Sylvie Vartan à Toulouse, la terrible opération de sécurité routière « Une ville rayée de la carte » à Mazamet, les inondations de la Garonne, etc.
_-_53Fi1931_-_cropped.jpg){kind=link}
_-_53Fi3120_(cropped).jpg){kind=link}
_-_53Fi1015.jpg){kind=link}
Parmi les autres exposés:
- Genma a parlé de la la représentation de l'informatique au cinéma (ah, le ridicule « Traque sur Internet »),
- Marc Rees a fait un remarquable exposé sur la redevance copie privée, un des grands scandales du système des ayant-droits, système qui en comprend pourtant beaucoup. Mais cela rapporte : 270 millions d'euros l'année dernière, dont une bonne partie sert à financer des actions de lobbying.
- Maïtané Lenoir a parlé de la collaboration entre projets de logiciel libre et les « designers ».
Capitole du Libre est remarquablement organisé, avec un gros investissement de la part des bénévoles, donc merci mille fois, c'était extra.
L'article seul
Un service d'hébergement de zones DNS accessible au·à la non-geek ?
Première rédaction de cet article le 3 novembre 2018
Dernière mise à jour le 17 mai 2021
Dans cet article, je ne vais pas décrire un logiciel ou service existant, ni résumer un RFC. Je voudrais au contraire pointer du doigt un manque dans l'offre existante, à la fois l'offre de services non-commerciaux accessibles au·à la non-geek, et l'offre de logiciel libre. Pourquoi n'y a-t-il pas de système simple pour héberger une zone DNS ? Et, si un·e militant·e de la liberté sur Internet passe par là, ne serait-ce pas une bonne idée d'en créer un ? J'espère que cet article donnera des idées.
Un peu de contexte d'abord. Le DNS est à la base de quasiment toutes les transactions sur l'Internet. Si on se soucie de la liberté et de l'indépendance de l'utilisateur qui veut publier quelque chose, et pas être un·e simple consommat·eur·rice, avoir un nom de domaine à soi est crucial. Acheter/louer un tel nom est simple et peu coûteux (encore qu'il semble qu'il n'existe que très peu, voire pas du tout, de bureaux d'enregistrement non-commerciaux). L'héberger est une autre histoire. L'hébergeur DNS (qui n'est pas forcément le bureau d'enregistrement) joue un rôle crucial. S'il est en panne, plus rien ne marche. S'il enregistre les données, la vie privée est menacée (sur ce risque, voir le RFC 7626). Il faut donc le choisir avec soin.
Or, beaucoup de titulaires de nom de domaine choisissent une entreprise (par exemple Cloudflare) un peu au hasard, sans avoir étudié ses pratiques. Il serait évidemment préférable de faire héberger ses serveurs de noms dans un endroit plus sûr.
Un solution geek existe pour cela,
l'auto-hébergement des serveurs de noms. Ce n'est pas très
compliqué (un logiciel libre comme nsd fait
cela très bien) et cela ne demande que peu de ressources (un
serveur DNS ne représente que peu de trafic, un
Raspberry Pi connecté en
ADSL suffit largement pour la plupart des
zones, d'autant plus que le vrai serveur primaire n'a pas
forcément besoin d'être accessible de tout l'Internet, il peut
être caché, visible uniquement des secondaires). Si on veut
améliorer les choses, on peut demander à des cop·ain·ine·s
d'héberger un serveur secondaire de sa zone. C'est ainsi qu'est
hébergée la zone DNS de ce blog, bortzmeyer.org.
Mais, évidemment, c'est uniquement une solution pour geek. On ne peut pas demander à toute personne qui publie sur Internet de configurer nsd ou Knot même si, je le répète, c'est relativement simple. Et il faudrait en plus éditer son fichier de zone DNS avec un éditeur de texte, ce qui n'enchante pas le non-geek. Or, la liberté d'expression ne doit pas être réservée aux informaticiens !
Il faudrait donc une solution pour ces utilisateurices. Il y a deux moyens de fournir cette solution, via un service ou via un logiciel. Concentrons-nous d'abord sur les services car, même s'il existait un logiciel tout fait, libre et tout, il resterait à gérer l'administration quotidienne du serveur, et un serveur DNS fait parfois face à des problèmes (voir plus loin dans cet article le problème des dDoS). Des services pour M. ou Mme Toutlemonde, libres, éthiques, non-commerciaux et le reste, existent, ce sont par exemple les CHATONS, dont le plus connu est Framasoft. Mais, à l'heure actuelle, à ma connaissance, aucun CHATON ne propose d'hébergement DNS.
Esquissons brièvement le cahier des charges d'un tel service :
- Utilisable indépendamment d'autres services (comme l'hébergement Web),
- Permet aux internautes de s'inscrire, puis de donner une liste de domaines qu'ils souhaitent voir gérés par le service,
- Permet de gérer le contenu de la zone DNS, en indiquant différents enregistrements, de tous les types possibles, avec leurs valeurs. L'interface proposée doit être simple d'usage, sans limiter les possibilités. Tous les hébergeurs DNS ont aujourd'hui une telle interface, typiquement via le Web et parfois via une API en prime.
- Raisonnablement sécurisé, car il ne faut pas qu'un utilisateur puisse modifier le domaine d'un autre !
- Ne réinventant pas la roue, donc reposant sur un logiciel de serveur DNS faisant autorité qui soit stable et sérieux comme nsd ou Knot.
- D'un point de vue de l'utilisateur, il serait bon d'avoir un mode simple, où on donne juste l'adresse IP du serveur Web, avec des modes plus avancés pour les utilisateurs qui ne se contentent pas d'un site Web.
- D'un point de vue politique, certains peuvent aussi souhaiter pouvoir maîtriser où sont situés les serveurs faisant autorité (on peut vouloir éviter tel ou tel pays, et migrer facilement),
- D'un point de vue plus technique, il faudrait DNSSEC (passage des enregistrements DS mais, surtout, gestion des clés et signatures par l'hébergeur), les mises à jour dynamiques du RFC 2136 (mais une bonne API peut les remplacer).
Un tel service, à ma connaissance, n'existe pas aujourd'hui dans le monde associatif. Il faut dire qu'il existe quelques risques :
- Le service pourrait être confronté à des menaces juridiques (la liberté d'expression ne plait pas à tout le monde), venant par exemple d'ayant-trop-de-droits si on héberge une zone DNS comme celle de Sci-Hub, ou bien venant d'adversaires politiques (cf. le cas d'IndyMedia),
- Tout le monde ne croit pas à l'état de droit et donc les menaces pourraient être suivies, voire précédées d'attaques par déni de service. L'exemple de Dyn ou bien celui du domaine national turc invitent à être prudent. Un hébergement DNS sympa fait par deux-trois potes pourrait ne pas résister à une dDoS un peu sérieuse.
- L'attaque par déni de service n'est pas la seule menace. Il existe aussi le risque de détournement du nom, comme c'était arrivé à Wikileaks et à beaucoup d'autres. Bien sûr, si le détournement avait exploité une faute de l'utilisateur, le logiciel n'y peut pas grand'chose. Mais certains détournements étaient dus à une faille de sécurité du logiciel.
On peut citer quelques services possibles qui se rapprochent de ce but :
- Le plus connu est Xname, dont la documentation est très complète, mais il est apparement abandonné (aucune nouvelle depuis 2013). Je teste et Error: bad zone name example.com. Donc, cela ne semble pas marcher. Le service semble vraiment mort, d'autant plus que leur propre zone est pleine d'erreurs.
- J'ai essayé de tester NetLibre. Il ne fournit pas
d'hébergement sec, il faut utiliser NetLibre pour acquérir son
nom (pour lequel on n'a donc pas un choix complet, on est limité
aux domaines de NetLibre). C'est donc plutôt l'équivalent de
eu.org, avec hébergement en plus. De toute façon, le service semble peu maintenu : Oh ! Une erreur est survenue. scp failed: unable to fork ssh master: Cannot allocate memory at /home/ppittoli/dnsmanager/bin/../lib/copycat.pm line 35 (et la seule adresse de contact est sur IRC). - Le service Free DNS est franchement trop compliqué pour moi. Je n'ai tout simplement pas compris ce qu'on pouvait faire avec, et comment s'en servir (mon domaine est marqué comme BROKEN et la FAQ est incompréhensible, et fausse quand elle prétend The central authority for all domains on the Internet is ICANN).
- On m'a cité
nohost.me, mais, si j'ai bien compris, c'est utilisable uniquement depuis YunoHost.
Cela, c'était pour un service en ligne. Et un logiciel ? Je vois deux cas d'usage :
- Pour ce·ux·elles qui ne font confiance à personne, et/ou ne veulent dépendre de personne. Le logiciel n'a alors pas besoin d'avoir la notion de comptes ou d'utilisateur, puisqu'il n'existe qu'un·e utilisat·eur·rice.
- Pour ce·ux·elles qui veulent faire essaimer le service. (Dans ce cas, le logiciel pourrait être utilisé par l'éventuel service public, puis par ses spin-offs.)
Ce doit être bien sûr un logiciel libre, qui doit pouvoir être installé relativement facilement, et fournir le service décrit ci-dessus. Pour le premier cas d'usage, le cas individuel, il serait peut-être encore mieux qu'il soit intégré à une plate-forme comme Cozy. Là encore, à ma connaissance, un tel logiciel n'existe pas (il existe plusieurs trucs plus ou moins bricolés, pas évidents à installer sur sa machine, et encore moins à maintenir).
Les logiciels existants qui pourraient servir d'inspiration :
- DNS
zones manager, le logiciel derrière NetLib.re. Je n'ai
pas réussi à l'installer (
perlbrew install perl-5.18.0donne « ERROR: Failed to download http://www.cpan.org/authors/id/R/RJ/RJBS/perl-5.18.0.tar.bz2 », il faut manifestement des compétences Perl plus pointues que les miennes.) - Il existe des logiciels bien plus génériques que des seuls gestionnaires de zones DNS, qui pourraient servir de point de départ. C'est le cas de ISPConfig ou Webmin, par exemple.
Mais notez bien que le logiciel ne résout qu'une partie du problème : il faut encore les serveurs. C'est pour cela que je pense que la solution « service hébergé » est plus adaptée aux non-geeks.
Notons enfin qu'un service limité, qui ne fournisse que le serveur secondaire, charge à l'utilisateur d'avoir son propre primaire, serait déjà très utile. Là encore, il me semble qu'il n'existe rien de tel. Peut-être :
- Puck. L'interface
est vraiment rude (elle n'indique même pas quelle est l'adresse IP
à autoriser, il faut regarder son
journal !)
mais ça marche bien. (Pensez à mettre ensuite
puck.nether.netdans l'ensemble des enregistrements NS.) - Au Danemark, il y a GratisDNS, depuis 1999 (documentation uniquement en danois.)
- EntryDNS faisait un service gratuit, mais il est désormais arrêté et remplacé par un service payant (mais très bon marché).
Je serai ravi d'apprendre que j'ai mal cherché et qu'un tel service ou un tel logiciel existent. N'hésitez pas à me le faire savoir. Et, si je ne me suis pas trompé, si un·e courageu·x·se pouvait le réaliser…
La partie « interface de gestion du contenu » est traitée par le très prometteur projet happyDNS (mais pas encore la partie « hébergement »). Il existe aussi le service d'hébergement deSEC, qui semble très bien, il fait l'hébergement et l'avitaillement (avec interface de gestion du contenu), mais pas la gestion d'un serveur secondaire, il faut complètement leur déléguer sa zone. (La question est discutée.)
L'article seul
RFC 8484: DNS Queries over HTTPS (DoH)
Date de publication du RFC : Octobre 2018
Auteur(s) du RFC : P. Hoffman (ICANN), P. McManus
(Mozilla)
Chemin des normes
Réalisé dans le cadre du groupe de travail IETF doh
Première rédaction de cet article le 22 octobre 2018
Voici un nouveau moyen d'envoyer des requêtes DNS, DoH (DNS over HTTPS). Requêtes et réponses, au lieu de voyager directement sur UDP ou TCP sont encapsulées dans HTTP, plus exactement HTTPS. Le but ? Il s'agit essentiellement de contourner la censure, en fournissant un canal sécurisé avec un serveur supposé digne de confiance. Et le chiffrement sert également à préserver la vie privée du client. Toutes ces fonctions pourraient être assurées en mettant le DNS sur TLS (RFC 7858) mais DoH augmente les chances de succès puisque le trafic HTTPS est rarement bloqué par les pare-feux, alors que le port 853 utilisé par DNS-sur-TLS peut être inaccessible, vu le nombre de violations de la neutralité du réseau. DoH marque donc une nouvelle étape dans la transition vers un Internet « port 443 seulement ».
La section 1 du RFC détaille les buts de DoH. Deux buts principaux sont décrits :
- Le premier, et le plus important, est celui indiqué au paragraphe précédent : échapper aux middleboxes qui bloquent le trafic DNS, ou bien le modifient. De telles violations de la neutralité du réseau sont fréquentes, imposées par les États ou les entreprises à des fins de censure, ou bien décidées par les FAI pour des raisons commerciales. Dans la lutte sans fin entre l'épée et la cuirasse, le DNS est souvent le maillon faible : infrastructure indispensable, il offre une cible tentante aux attaquants. Et il est utilisable pour la surveillance (cf. RFC 7626). DNS-sur-TLS, normalisé dans le RFC 7858, était une première tentative de protéger l'intégrité et la confidentialité du trafic DNS par la cryptographie. Mais il utilise un port dédié, le port 853, qui peut être bloqué par un intermédiaire peu soucieux de neutralité du réseau. Dans de nombreux réseaux, hélas, le seul protocole qui soit à peu près sûr de passer partout est HTTPS sur le port 443. D'où la tendance actuelle à tout mettre sur HTTP.
- Il y a une deuxième motivation à DoH, moins importante, la possibilité de faire des requêtes DNS complètes (pas seulement des demandes d'adresses IP) depuis des applications JavaScript tournant dans le navigateur, et tout en respectant CORS.
L'annexe A de notre RFC raconte le cahier des charges du protocole DoH de manière plus détaillée :
- Sémantique habituelle de HTTP (on ne change pas HTTP),
- Possibilité d'exprimer la totalité des requêtes et réponses DNS actuelles, d'où le choix de l'encodage binaire du DNS et pas d'un nouvel encodage, par exemple en JSON, plus simple mais limité à un sous-ensemble du DNS,
- Et aussi des « non-considérations » : DoH n'avait pas à traiter le cas des réponses synthétisées, comme DNS64, ni celui des réponses à la tête du client, ni le HTTP tout nu sans TLS.
Passons maintenant à la technique. DoH est un protocole très simple. Au hackathon de l'IETF en mars 2018 à Londres, les sept ou huit personnes travaillant sur DoH avaient très vite réussi à créer clients et serveurs, et à les faire interopérer (même moi, j'y étais arrivé). Vous pouvez lire le compte-rendu du hackathon, et la présentation quelques jours après au groupe de travail DoH.)
DoH peut s'utiliser de plusieurs façons : c'est une technique,
pas une politique. Néanmoins, son principal usage sera entre un
résolveur simple, situé sur la machine de l'utilisateur ou quelque
part dans son réseau local, et un résolveur complet situé plus
loin dans le réseau (section 1 du RFC). Ce résolveur simple peut
être un démon comme stubby ou systemd, ou
bien l'application elle-même (ce qui me semble personnellement une
mauvaise idée, car cela empêche de partager configuration et
cache). À l'heure actuelle, les
serveurs faisant autorité ne parlent pas DoH et il n'est pas prévu
qu'ils s'y mettent à brève échéance. Le schéma suivant montre
l'utilisation typique de DoH : l'application (le client final)
parle à un résolveur simple, en utilisant le protocole DNS (ce qui
évite de mettre du DoH dans toutes les applications), le résolveur
simple parlera en DoH avec un résolveur de confiance situé quelque
part dans l'Internet, et ce résolveur de confiance utilisera le
DNS pour parler aux serveurs faisant autorité (soit il sera
lui-même un résolveur complet, soit il parlera à un résolveur
classique proche de lui, et le serveur DoH sera alors un
proxy comme décrit dans le RFC 5625) : 
Les requêtes et réponses DNS (RFC 1034 et RFC 1035) ont leur encodage habituel (le DNS est un protocole binaire, donc je ne peux pas faire de copier/coller pour montrer cet encodage), la requête est mise dans le chemin dans l'URL ou dans le corps d'une requête HTTP (RFC 9113), la réponse se trouvera dans le corps de la réponse HTTP. Toute la sécurité (intégrité et confidentialité) est assurée par TLS (RFC 8446), via HTTPS (RFC 2818). Un principe essentiel de DoH est d'utiliser HTTP tel quel, avec ses avantages et ses inconvénients. Cela permet de récupérer des services HTTP comme la négociation de contenu, la mise en cache, l'authentification, les redirections, etc.
La requête HTTP elle-même se fait avec les méthodes GET ou POST
(section 4 du RFC), les deux devant être acceptées (ce qui fut le
sujet d'une assez longue discussion à l'IETF.) Quand la méthode
utilisée est GET, la variable nommée dns est
le contenu de la requête DNS, suivant l'encodage habituel du DNS,
surencodée en Base64, plus exactement la
variante base64url normalisée dans le RFC 4648. Et, avec GET, le corps de la requête est vide
(RFC 7231, section 4.3.1). Quand on utilise POST, la
requête DNS est dans le corps de la requête HTTP et n'a pas ce
surencodage. Ainsi, la requête avec POST sera sans doute plus
petite, mais par contre GET est certainement plus apprécié par les
caches.
On l'a dit, DoH utilise le HTTP habituel. L'utilisation de HTTP/2, la version 2 de HTTP (celle du RFC 9113) est très recommandée, et clients et serveurs DoH peuvent utiliser la compression et le remplissage que fournit HTTP/2 (le remplissage étant très souhaitable pour la vie privée). HTTP/2 a également l'avantage de multiplexer plusieurs ruisseaux (streams) sur la même connexion HTTP, ce qui évite aux requêtes DoH rapides de devoir attendre le résultat d'une requête lente qui aurait été émise avant. (HTTP 1, lui, impose le respect de l'ordre des requêtes.) HTTP/2 n'est pas formellement imposé, car on ne peut pas forcément être sûr du comportement des bibliothèques utilisées, ni de celui des différents relais sur le trajet.
Requêtes et réponses ont actuellement le type
MIME application/dns-message,
mais d'autres types pourront apparaitre dans le futur (par exemple
fondés sur JSON et non plus sur l'encodage
binaire du DNS, qui n'est pas amusant à
analyser en
JavaScript). Le client DoH doit donc
inclure un en-tête HTTP Accept: pour indiquer
quels types MIME il accepte. En utilisant HTTP, DoH bénéfice également de la négociation de
contenu HTTP (RFC 7231, section 3.4).
Petit détail DNS : le champ ID (identification de la requête) doit être mis à zéro. Avec UDP, il sert à faire correspondre une requête et sa réponse mais c'est inutile avec HTTP, et cela risquerait d'empêcher la mise en cache de deux réponses identiques mais avec des ID différents.
En suivant la présentation des requêtes HTTP du RFC 9113 (rappelez-vous que HTTP/2, contrairement à la première version de HTTP, a un encodage binaire), cela donnerait, par exemple :
:method = GET
:scheme = https
:authority = dns.example.net
:path = /?dns=AAABAAABAAAAAAAAA3d3dwdleGFtcGxlA2NvbQAAAQAB
accept = application/dns-message
(Si vous vous le demandez,
AAABAAABAAAAAAAAA3d3dwdleGFtcGxlA2NvbQAAAQAB
est une requête DNS pour l'adresse IPv4 de www.example.com.)
Et la réponse HTTP ? Aujourd'hui, elle est forcément de type
MIME application/dns-message, mais d'autres
types pourront apparaitre. En attendant, le corps de la réponse
HTTP est une réponse DNS avec son encodage binaire habituel
normalisé dans le RFC 1035, section 4.1 (tel
qu'utilisé pour UDP ; notez que HTTP
permettant d'indiquer la longueur du message, les deux octets de
longueur utilisés par le DNS au-dessus de
TCP ne sont pas nécessaires et sont donc absents).
Le serveur DoH doit mettre un code de retour HTTP (RFC 7231). 200 signifie que la requête HTTP a bien été traitée. Mais cela ne veut pas dire que la requête DNS, elle, ait connu un succès. Si elle a obtenu une erreur DNS NXDOMAIN (nom non trouvé) ou SERVFAIL (échec de la requête), le code de retour HTTP sera quand même 200, indiquant qu'il y a une réponse DNS, même négative. Le client DoH, en recevant ce 200, devra donc analyser le message DNS et y trouver le code de retour DNS (NOERROR, NXDOMAIN, REFUSED, etc). Le serveur DoH ne mettra un code d'erreur HTTP que s'il n'a pas du tout de réponse DNS à renvoyer. Il mettra 403 s'il refuse de servir ce client DoH, 429 si le client fait trop de requêtes (RFC 6585), 500 si le serveur DoH a une grosse bogue, 415 si le type MIME utilisé n'est pas connu du serveur, et bien sûr 404 si le serveur HTTP ne trouve rien à l'URL indiqué par exemple parce que le service a été retiré. Dans tous ces cas, il n'y a pas de réponse DNS incluse. La sémantique de ces codes de retour, et le comportement attendu du client, suit les règles habituelles de HTTP, sans spécificité DoH. (C'est un point important et général de DoH : c'est du DNS normal sur du HTTP normal). Par exemple, lorsque le code de retour commence par un 4, le client n'est pas censé réessayer la même requête sur le même serveur : elle donnera forcément le même résultat.
Voici un exemple de réponse DoH :
:status = 200
content-type = application/dns-message
content-length = 61
cache-control = max-age=3709
[Les 61 octets, ici représentés en hexadécimal pour la lisibilité]
00 00 81 80 00 01 00 01 00 00 00 00 03 77 77 77
07 65 78 61 6d 70 6c 65 03 63 6f 6d 00 00 1c 00
01 c0 0c 00 1c 00 01 00 00 0e 7d 00 10 20 01 0d
b8 ab cd 00 12 00 01 00 02 00 03 00 04
La réponse DNS signifie « l'adresse de
www.example.com est
2001:db8:abcd:12:1:2:3:4 et le
TTL est de 3709 secondes [notez comme il
est repris dans le Cache-control: HTTP] ».
Comment un client DoH trouve-t-il le serveur ? La section 3 du
RFC répond à cette question. En gros, c'est manuel. DoH ne fournit
pas de mécanisme de sélection automatique. Concevoir un tel
mécanisme et qu'il soit sécurisé est une question non triviale, et
importante : changer le résolveur DNS utilisé par une machine
revient quasiment à pirater complètement cette machine. Cela avait
fait une très longue discussion au sein du groupe de travail DoH à
l'IETF, entre ceux qui pensaient qu'un
mécanisme automatique de découverte du gabarit faciliterait
nettement la vie de l'utilisateur, et ceux qui estimaient qu'un
tel mécanisme serait trop facile à subvertir. Donc, pour
l'instant, le client DoH reçoit manuellement un gabarit d'URI
(RFC 6570) qui indique le serveur DoH à
utiliser. Par
exemple, un client recevra le gabarit
https://dns.example.net/{?dns}, et il fera
alors des requêtes HTTPS à dns.example.net,
en passant ?dns=[valeur de la requête].
Notez que l'URL dans le gabarit peut comporter un nom de domaine, qui devra lui-même être résolu via le DNS, créant ainsi un amusant problème d'œuf et de poule (cf. section 10 de notre RFC). Une solution possible est de ne mettre que des adresses IP dans l'URL, mais cela peut poser des problèmes pour l'authentification du serveur DoH, toutes les autorités de certification n'acceptant pas de mettre des adresses IP dans le certificat (cf. RFC 6125, section 1.7.2, et annexe B.2).
La section 5 du RFC détaille quelques points liés à
l'intégration avec HTTP. D'abord, les
caches. DNS et HTTP ont chacun son
système. Et entre le client et le serveur aux extrémités, il peut
y avoir plusieurs caches DNS et plusieurs caches HTTP, et ces
derniers ne connaissent pas forcément DoH. Que se passe-t-il si on
réinjecte dans le DNS des données venues d'un cache HTTP ? En général, les réponses aux requêtes POST ne sont pas mises
en cache (elles le peuvent, en théorie) mais les requêtes GET le
sont, et les implémenteurs de DoH doivent donc prêter attention à
ces caches. La méthode recommandée est de mettre une durée de
validité explicite dans la réponse HTTP (comme dans l'exemple plus
haut avec Cache-control:), en suivant le RFC 9111, notamment sa section 4.2. La durée de
validité doit être inférieure ou égale au plus petit
TTL de la section principale de la réponse
DNS. Par exemple, si un serveur DoH renvoie cette réponse DNS :
ns1.bortzmeyer.org. 27288 IN AAAA 2605:4500:2:245b::42
ns2.bortzmeyer.org. 26752 IN AAAA 2400:8902::f03c:91ff:fe69:60d3
ns4.bortzmeyer.org. 26569 IN AAAA 2001:4b98:dc0:41:216:3eff:fe27:3d3f
alors, la réponse HTTP aura un Cache-Control:
max-age=26569, le plus petit des TTL.
Si la réponse DNS varie selon le client, le serveur DoH doit en
tenir compte pour construire la réponse HTTP. Le but est d'éviter
que cette réponse adaptée à un client spécifique soit
réutilisée. Cela peut se faire avec Cache-Control:
max-age=0 ou bien avec un en-tête
Vary: (RFC 7231,
section 7.1.4 et RFC 9111, section 4.1) qui va ajouter une
condition supplémentaire à la réutilisation des données mises en
cache.
S'il y a un en-tête Age: dans la réponse
HTTP (qui indique depuis combien de temps cette information était
dans un cache Web, RFC 9111, section 5.1), le client DoH
doit en tenir compte pour calculer le vrai TTL. Si le TTL DNS dans
la réponse est de 600 secondes, mais que Age:
indiquait que cette réponse avait séjourné 250 secondes dans le
cache Web, le client DoH doit considérer que cette réponse n'a
plus que 350 secondes de validité. Évidemment, un client qui veut
des données ultra-récentes peut toujours utiliser le
Cache-control: no-cache dans sa requête HTTP,
forçant un rafraichissement. (Il est à noter que le DNS n'a aucun
mécanisme équivalent, et qu'un serveur DoH ne saura donc pas
toujours rafraichir son cache DNS.)
La définition formelle du type MIME
application/dns-message figure en section 6
de notre RFC, et ce type est désormais enregistré
à l'IANA.
La section 8 du RFC est consacrée aux questions de vie privée. C'est à la fois un des principaux buts de DoH (empêcher l'écoute par un tiers) et un point qui a fait l'objet de certaines polémiques, puisque DoH peut être utilisé pour envoyer toutes les requêtes à un gros résolveur public auquel on ne fait pas forcément confiance. Le RFC 7626 traite séparément deux problèmes : l'écoute sur le réseau, et l'écoute effectuée par le serveur. Sur le réseau, DoH protège : tout est chiffré, via un protocole bien établi, TLS. Du fait que le serveur est authentifié, l'écoute par un homme du milieu est également empêchée. DNS sur TLS (RFC 7858) a exactement les mêmes propriétés, mais pour principal inconvénient d'utiliser un port dédié, le 853, trop facile à bloquer. Au contraire, le trafic DoH, passant au milieu d'autres échanges HTTP sur le port 443, est bien plus difficile à restreindre.
Mais et sur le serveur de destination ? Une requête DNS normale
contient peu d'informations sur le client (sauf si on utilise la
très dangereuse technique du RFC 7871). Au
contraire, une requête HTTP est bien trop bavarde :
cookies (RFC 6265), en-têtes User-Agent: et
Accept-Language:, ordre des en-têtes sont
trop révélateurs de l'identité du client. L'utilisation de HTTP
présente donc des risques pour la vie privée du client, risques
connus depuis longtemps dans le monde HTTP mais qui sont nouveaux
pour le DNS. Il avait été envisagé, pendant la discussion à
l'IETF, de définir un sous-ensemble de HTTP ne présentant pas ces
problèmes, mais cela serait rentré en contradiction avec les buts
de DoH (qui étaient notamment de permettre l'utilisation du code
HTTP existant). Pour l'instant, c'est donc au client DoH de
faire attention. Si la bibliothèque HTTP qu'il utilise le permet,
il doit veiller à ne pas envoyer de cookies, à
envoyer moins d'en-têtes, etc.
Notez que la question de savoir si les requêtes DoH doivent voyager sur la même connexion que le trafic HTTPS normal (ce que permet HTTP/2, avec son multiplexage) reste ouverte. D'un côté, cela peut aider à les dissimuler. De l'autre, les requêtes HTTP typiques contiennent des informations qui peuvent servir à reconnaitre le client, alors qu'une connexion servant uniquement à DoH serait moins reconnaissable, le DNS étant nettement moins sensible au fingerprinting.
Comme TLS ne dissimule pas la taille des messages, et qu'un observateur passif du trafic, et qui peut en plus envoyer des requêtes au serveur DNS, peut en déduire les réponses reçues, le RFC recommande aux clients DoH de remplir les requêtes DNS selon le RFC 7830.
Le choix de Mozilla d'utiliser DoH pour son navigateur Firefox (voir un compte-rendu de la première expérience) et le fait que, dans certaines configurations, le serveur DoH de Cloudflare était systématiquement utilisé a été très discuté (cf. cette discussion sur le forum des développeurs et cet article du Register). Mais cela n'a rien à voir avec DoH : c'est le choix d'utiliser un résolveur public géré par un GAFA qui est un problème, pas la technique utilisée pour accéder à ce résolveur public. DNS-sur-TLS aurait posé exactement le même problème. Si Mozilla a aggravé les choses avec leur discours corporate habituel (« nous avons travaillé très dur pour trouver une entreprise de confiance »), il faut rappeler que le problème de la surveillance et de la manipulation des requête et réponses DNS par les FAI est un problème réel (essayez de demander à votre FAI s'il s'engage à ne jamais le faire). On a vu plus haut que DoH ne prévoit pas de système de découverte du serveur. Il faut donc que cela soit configuré en dur (un travail supplémentaire pour les utilisateurs, s'il n'y a pas de résolveur par défaut). En tout cas, le point important est que DoH (ou DNS-sur-TLS) ne protège la vie privée que si le serveur DoH est honnête. C'est une limitation classique de TLS : « TLS permet de s'assurer qu'on communique bien avec Satan, et qu'un tiers ne peut pas écouter ». Mais DoH n'impose pas d'utiliser un serveur public, et impose encore moins qu'il s'agisse d'un serveur d'un GAFA.
La section 9 de notre RFC traite des autres problèmes de sécurité. D'abord, sur la relation entre DoH et DNSSEC. C'est simple, il n'y en a pas. DNSSEC protège les données, DoH protège le canal (une distinction que les promoteurs de DNSCurve n'ont jamais comprise). DNSSEC protège contre les modifications illégitimes des données, DoH (ou bien DNS-sur-TLS) protège contre l'écoute illégitime. Ils résolvent des problèmes différents, et sont donc tous les deux nécessaires.
Quant à la section 10 du RFC, elle expose diverses considérations pratiques liées à l'utilisation de DoH. Par exemple, si un serveur faisant autorité sert des réponses différentes selon l'adresse IP source du client (RFC 6950, section 4), utiliser un résolveur public, qu'on y accède via DoH ou par tout autre moyen, ne donnera pas le résultat attendu, puisque l'adresse IP vue par le serveur faisant autorité sera celle du résolveur public, probablement très distincte de celle du « vrai » client. Un exemple similaire figure dans le RFC : une technique comme DNS64 (RFC 6147) risque fort de ne pas marcher avec un résolveur DNS extérieur au réseau local.
Quelles sont les mises en œuvre de DoH ? Le protocole est assez récent donc votre système favori n'a pas forcément DoH, ou alors c'est seulement dans les toutes dernières versions. Mais DoH est très simple à mettre en œuvre (c'est juste la combinaison de trois protocoles bien maitrisés, et pour lesquels il existe de nombreuses bibliothèques, DNS, HTTP et TLS) et le déploiement ne devrait donc pas poser de problème.
Voyons maintenant ce qui existe, question logiciels et
serveurs. On a vu que Cloudflare a un serveur public, le fameux
1.1.1.1 étant
accessible en DoH (et également en DNS-sur-TLS). Je ne
parlerai pas ici de la question de la confiance qu'on peut
accorder à ce serveur (je vous laisse lire sa politique
de vie privée et l'évaluer vous-même), qui avait été
contestée lors de la polémique Mozilla citée plus haut. Cloudflare
fournit également une bonne
documentation sur DoH, avec une explication
de l'encodage. Enfin, Cloudflare fournit un résolveur
simple (comme stubby ou systemd cités plus haut) qui est un client
DoH, cloudflared.
Un autre serveur DoH public, cette fois issu du monde du
logiciel libre, est celui de l'équipe
PowerDNS, https://doh.powerdns.org/
(cf. leur
annonce). Il utilise leur logiciel dnsdist.
Vous trouverez une liste de serveurs DoH publics chez DefaultRoutes ou
bien chez
curl ou encore sur
le portail dnsprivacy.org. Testons ces serveurs DoH
publics avec le programme doh-nghttp.c, qui avait
été écrit au hackathon IETF 101,
on lui donne l'URL du serveur DoH, et le nom à résoudre, et il
cherche l'adresse IPv4 correspondant à ce nom :
% ./doh-nghttp https://doh.powerdns.org/ www.bortzmeyer.org
The address is 204.62.14.153
% ./doh-nghttp https://1.1.1.1/dns-query www.bortzmeyer.org
The address is 204.62.14.153
% ./doh-nghttp https://doh.defaultroutes.de/dns-query www.bortzmeyer.org
The address is 204.62.14.153
% ./doh-nghttp https://mozilla.cloudflare-dns.com/dns-query www.bortzmeyer.org
The address is 204.62.14.153
Parfait, tout a bien marché. Un autre serveur DoH a la particularité d'être un résolveur menteur (regardez son nom) :
% ./doh-nghttp https://doh.cleanbrowsing.org/doh/family-filter/ www.bortzmeyer.org
The address is 204.62.14.153
% ./doh-nghttp https://doh.cleanbrowsing.org/doh/family-filter/ pornhub.com
The search had no results, and a return value of 8. Exiting.
% ./doh-nghttp https://doh.powerdns.org/ pornhub.com
The address is 216.18.168.16
Bon, et si je veux faire mon propre serveur DoH, on a quelles solutions ? Voyons d'abord le doh-proxy de Facebook. On lui indique le résolveur qu'il va utiliser (il n'est pas inclus dans le code, il a besoin d'un résolveur complet, a priori sur la même machine ou le même réseau local) :
% doh-proxy --port=9443 --upstream-resolver=192.168.2.254 --certfile=server.crt --keyfile=server.key --uri=/
2018-09-27 10:04:21,997: INFO: Serving on <Server sockets=[<socket.socket fd=6, family=AddressFamily.AF_INET6, type=2049, proto=6, laddr=('::1', 9443, 0, 0)>]>
Et posons-lui des questions avec le même client doh-nghttp :
% ./doh-nghttp https://ip6-localhost:9443/ www.bortzmeyer.org The address is 204.62.14.153
C'est parfait, il a marché et affiche les visites :
2018-09-27 10:04:24,264: INFO: [HTTPS] ::1 www.bortzmeyer.org. A IN 0 RD 2018-09-27 10:04:24,264: INFO: [DNS] ::1 www.bortzmeyer.org. A IN 56952 RD 2018-09-27 10:04:24,639: INFO: [DNS] ::1 www.bortzmeyer.org. A IN 56952 QR/RD/RA 1/0/0 -1/0/0 NOERROR 374ms 2018-09-27 10:04:24,640: INFO: [HTTPS] ::1 www.bortzmeyer.org. A IN 0 QR/RD/RA 1/0/0 -1/0/0 NOERROR 375ms
Au même endroit, il y a aussi un client DoH :
% doh-client --domain 1.1.1.1 --uri /dns-query --qname www.bortzmeyer.org
2018-09-27 10:14:12,191: DEBUG: Opening connection to 1.1.1.1
2018-09-27 10:14:12,210: DEBUG: Query parameters: {'dns': 'AAABAAABAAAAAAAAA3d3dwpib3J0em1leWVyA29yZwAAHAAB'}
2018-09-27 10:14:12,211: DEBUG: Stream ID: 1 / Total streams: 0
2018-09-27 10:14:12,219: DEBUG: Response headers: [(':status', '200'), ('date', 'Thu, 27 Sep 2018 08:14:12 GMT'), ('content-type', 'application/dns-message'), ('content-length', '103'), ('access-control-allow-origin', '*'), ('cache-control', 'max-age=5125'), ('expect-ct', 'max-age=604800, report-uri="https://report-uri.cloudflare.com/cdn-cgi/beacon/expect-ct"'), ('server', 'cloudflare-nginx'), ('cf-ray', '460c83ee69f73c53-CDG')]
id 0
opcode QUERY
rcode NOERROR
flags QR RD RA AD
edns 0
payload 1452
;QUESTION
www.bortzmeyer.org. IN AAAA
;ANSWER
www.bortzmeyer.org. 5125 IN AAAA 2001:4b98:dc0:41:216:3eff:fe27:3d3f
www.bortzmeyer.org. 5125 IN AAAA 2605:4500:2:245b::42
;AUTHORITY
;ADDITIONAL
2018-09-27 10:14:12,224: DEBUG: Response trailers: {}
Ainsi qu'un résolveur simple (serveur DNS et client DoH).
Il ne faut pas confondre ce doh-proxy écrit en Python avec un logiciel du même nom écrit en Rust (je n'ai pas réussi à le compiler, celui-là, des compétences Rust plus avancées que les miennes sont nécessaires).
Et les clients, maintenant ? Commençons par le bien connu curl, qui a DoH est depuis la version 7.62.0 (pas encore publiée à l'heure où j'écris, le développement est documenté ici.) curl (comme Mozilla Firefox) fait la résolution DNS lui-même, ce qui est contestable (il me semble préférable que cette fonction soit dans un logiciel partagé par toutes les applications). Voici un exemple :
% ./src/.libs/curl -v --doh-url https://doh.powerdns.org/ www.bortzmeyer.org ... [Se connecter au serveur DoH] * Connected to doh.powerdns.org (2a01:7c8:d002:1ef:5054:ff:fe40:3703) port 443 (#2) * ALPN, offering h2 ... * SSL connection using TLSv1.2 / ECDHE-RSA-AES256-GCM-SHA384 * Server certificate: * subject: CN=doh.powerdns.org ... [Envoyer la requête DoH] * Using Stream ID: 1 (easy handle 0x5631606cbd50) > POST / HTTP/2 > Host: doh.powerdns.org > Accept: */* > Content-Type: application/dns-message > Content-Length: 36 ... < HTTP/2 200 < server: h2o/2.2.5 < date: Thu, 27 Sep 2018 07:39:14 GMT < content-type: application/dns-message < content-length: 92 ... [On a trouvé la réponse DoH] * DOH Host name: www.bortzmeyer.org * TTL: 86392 seconds * DOH A: 204.62.14.153 * DOH AAAA: 2001:4b98:0dc0:0041:0216:3eff:fe27:3d3f * DOH AAAA: 2605:4500:0002:245b:0000:0000:0000:0042 ... [On peut maintenant se connecter au serveur HTTP - le but principal de curl - maintenant qu'on a son adresse IP] * Connected to www.bortzmeyer.org (204.62.14.153) port 80 (#0) > GET / HTTP/1.1 > Host: www.bortzmeyer.org > User-Agent: curl/7.62.0-20180927 > Accept: */* >
Pour les programmeurs Go, l'excellente bibliothèque godns n'a hélas pas DoH (pour des raisons internes). Du code expérimental avait été écrit dans une branche mais a été abandonné. Les amateurs de Go peuvent essayer à la place cette mise en œuvre (on notera que ce client sait parler DoH mais aussi le protocole spécifique et non-standard du résolveur public Google Public DNS).
Pour les programmeurs C, la référence
est la bibliothèque getdns (notez que c'est elle
qui a été utilisée pour le client doh-nghttp
cité plus haut). Le code DoH est, à la parution du RFC, toujours
en cours de développement et pas encore dans un dépôt public. Une
fois que cela sera fait, stubby, qui utilise getdns, pourra parler
DoH.
Voilà, si vous n'êtes pas épuisé·e·s, il y a encore des choses à lire :
- Plein d'informations sur Doh et ses mises en œuvre chez DefaultRoutes, dont un bon exposé sur DoH,
- Le dépôt git qui avait été utilisé par le groupe de travail DoH,
- Un bon article amusant sur les débuts de DoH.
- Un article de Mozilla sur DoH (l'explication du DNS est assez médiocre mais il y a des dessins, donc cela peut être utile pour présenter DoH à l'école élémentaire). Attention, contient de la propagande corporate.
- L'analyse de Sara Dickinson sur les conséquences de DoH.
- Un intéressant article de fond sur DoH.
- Mon exposé sur DoH aux JDLL de 2019.
L'article seul
Les générateurs de site Web statiques, et mon choix de Pelican
Première rédaction de cet article le 19 octobre 2018
J'ai récemment dû faire deux sites Web et leur cahier des charges permettait de faire des sites Web statiques, ce qui a de nombreux avantages. Parmi les dizaines de logiciels qui permettent de faire un site Web statique, j'ai choisi Pelican.
Un de ces deux sites (l'autre est privé) est celui de mon livre.
Pourquoi un site Web statique, et non pas généré à la demande via un CMS ? Cela présente plusieurs avantages :
- Le principal est de performance et de résistance à la charge : un site Web dépendant d'un CMS doit exécuter des milliers de lignes de PHP ou de Java à chaque requête. Cela le rend lent et, surtout, une attaque par déni de service, même modérée (par exemple avec un outil primitif comme LOIC) suffit à le rendre inutilisable. Même pas besoin d'attaque, d'ailleurs, parfois, une simple utilisation un peu intense (une mention sur Mastodon, par exemple) peut le rendre inaccessible. Un site Web dynamique doit donc être hébergé sur de grosses machines coûteuses, alors qu'un site statique peut tenir une charge bien plus élevée. Tous les serveurs HTTP savent servir des fichiers statiques très rapidement.
- Un deuxième avantage est de dépendance. Le site statique ne dépend que du serveur HTTP. Au contraire, un site dynamique dépend de plusieurs logiciels supplémentaires (comme par exemple MariaDB) dont la panne peut le rendre inutilisable, souvent avec des messages d'erreur incompréhensibles.
- Enfin, le site statique présente un gros avantage de sécurité : au contraire du site dynamique, qui peut souvent être piraté, par exemple par injection SQL, le site statique n'exécutant pas de code et étant composé de simples fichiers de données, n'a pas de failles de sécurité, autres que celles du serveur HTTP et de la machine sous-jacente.
Bref, pas question d'utiliser WordPress ou Drupal. Mais, alors, comment faire ? Une solution évidente est de tout faire à la main, éditant le HTML du site avec un éditeur texte ordinaire. Cette solution n'est pas forcément agréable. Éditer du HTML n'est pas très amusant (même si, au début du Web, tout le monde faisait comme cela car il n'y avait pas le choix), et surtout, cela rend très difficile le maintien d'une apparence cohérente entre toutes les pages du site. Bien sûr, l'utilisation d'un fichier CSS identique pour toutes les pages fera que des questions esthétiques comme la couleur du fond ou comme la police utilisée seront traitées de manière identique pour toutes les pages. Mais cela ne règle pas le cas d'éléments qu'on veut voir partout, et que CSS ne sait pas gérer, ou en tout cas pas facilement avec les navigateurs actuels. Par exemple, si on veut un pied de page identique partout, avec une adresse du webmestre et un menu, faire les pages à la main nécessiterait du copier/coller pénible et, surtout, rendrait difficile toute modification ultérieure de ce pied de page.
Une solution possible serait d'utiliser un CMS pour créer du contenu, ce qui permettrait aux utilisateurs attachés à ces outils de rédiger du contenu, puis de transformer le site Web dynamique en statique, avec un outil comme httrack, et de faire servir ensuite le contenu statique. Mais, ici, comme j'étais le seul à ajouter du contenu, le problème d'utilisation d'un éditeur ne se posait pas, je suis plus à l'aise avec un éditeur de texte qu'avec les éditeurs des CMS.
Les générateurs de site Web statiques utilisent tous le concept de gabarit. On écrit un gabarit que doivent respecter les pages, puis on écrit les pages et le générateur de site Web statique réalise l'incarnation de ces pages en fichiers HTML qui suivent le gabarit. De tels outils sont presque aussi anciens que le Web. Le premier que j'ai utilisé était wml, puis Blosxom a été le plus à la mode, puis Jekyll. Et il en existe aujourd'hui une quantité étonnante, beaucoup de programmeurs ayant apparemment eu envie d'écrire le leur. Pour en choisir un, mon cahier des charges était logiciel libre, et disponible sous forme d'un paquetage dans la version stable de Debian (car je souhaitais réaliser des sites Web, pas passer du temps à de l'administration système et de l'installation de logiciels).
Voyons maintenant les différents générateurs de sites Web statiques que j'ai testé, en commençant par celui que j'ai finalement choisi, Pelican. Pelican est écrit en Python (cela peut avoir son importance si vous souhaitez en étendre les fonctions, et même le fichier de configuration d'un site est en Python). Il est surtout prévu pour des blogs, avec une notion de chronologie, alors que mon utilisation est différente, juste un ensemble de pages. La plupart de ces générateurs de sites statiques sont, comme Pelican, plutôt orientés vers le blog.
Une fois installé (paquetage Debian pelican),
on crée un répertoire pour les fichiers de son site, on se rend
dans ce répertoire, et on lance la commande
pelican-quickstart qui va interactivement
vous guider et générer les fichiers nécessaires. Comme toutes les
commandes interactives, c'est pénible à utiliser mais cela peut
être utile aux débutants. La plupart des questions sont simples et
la valeur par défaut est raisonnable, sauf pour les dernières, où
pelican-quickstart vous demande comment
installer les pages produites sur votre site Web. Il propose
FTP, SSH, et des
commandes spécifiques pour des environnements fermés chez des GAFA
comme Dropbox ou
S3. Personnellement, je n'aime pas que la
réponse à la question « Do you want to specify a URL
prefix? » soit Oui par défaut. Dans ce cas, Pelican
définit une variable SITEURL dans la
configuration et tous les liens sont préfixés par cet
URL, ce qui empêche de tester le site en
local, un comble pour un générateur de sites statiques. Je réponds
donc Non à cette question (ou bien je mets
RELATIVE_URLS à True
dans publishconf.py).
Ensuite, nous pouvons rédiger le premier article. Pelican
accepte des articles faits en Markdown et
reST. Ici,
j'utilise Markdown. J'édite un premier article
content/bidon.md, et j'y mets :
Title: C'est trop tôt
Date: 2018-10-11
Test *bidon*, vraiment.
Les deux premières lignes sont des
métadonnées spécifiques à Pelican. Il faut
indiquer le titre de l'article et la date (rappelez-vous que
Pelican est optimisé pour des blogs, où les articles sont classés
par ordre rétro-chronologique). Si, comme moi, vous faites un site
Web qui n'est pas un blog, la date n'est pas nécessaire (les
détails suivent). Ensuite, pelican-quickstart
ayant créé le Makefile qui va
bien, un simple make publish suffit à
fabriquer les fichiers HTML, dans le répertoire
./output. On peut alors pointer son
navigateur Web favori vers
output/index.html. (pelican
content donne le même résultat que make
publish. Tapez make sans argument
pour voir la liste des possibilités.) Pour copier les fichiers
vers la destination, si vous avez configuré un des mécanismes de
téléversement, vous pouvez faire make
XXX_upload, où XXX est votre méthode de
téléversement. Par exemple, si vous avez configuré
SSH, ce sera make
ssh_upload (mais vous pouvez évidemment éditer le
Makefile pour donner un autre nom).
Si vous voulez changer la configuration du site après, les
fichiers de configuration sont eux-même écrits en
Python, donc il est utile de connaitre un
peu ce langage pour éditer pelicanconf.py et
publishconf.py. Par exemple, si vous voulez
que les dates soient affichées en français, avoir répondu
fr aux questions de
pelican-quickstart ne suffit pas, il faut
ajouter LOCALE = ('fr_FR', 'fr') à
pelicanconf.py.
En mode blog, Pelican met chaque article dans une catégorie, indiquée dans les métadonnées (si vous ne mettez rien, comme dans l'exemple de fichier Markdown plus haut, c'est mis dans la catégorie « misc »).
Je l'avais dit, les deux sites Web où j'utilise Pelican ne sont
pas de type blog, mais plutôt des sites classiques, avec un
ensemble de pages, sans notion d'ordre chronologique. Pour cela,
il faut mettre ces pages (Pelican appelle les fichiers d'un blog chronologique
« articles » et les autres fichiers, par exemple les mentions
légales, des « pages ») dans un répertoire
content/pages, et dire à Pelican sous quel
nom enregistrer l'HTML produit, sinon, ses choix peuvent être
différents de ce qu'on aurait choisi (mais on n'a plus à mettre la
date) :
% mkdir content/pages
% emacs content/pages/mentions-legales.md
% make publish
Done: Processed 3 articles, 0 drafts, 1 page and 0 hidden pages in 0.12 seconds.
Vous voyez que vous avez maintenant « 1 page », en plus des articles. Ces pages apparaitront en haut de la page d'accueil (tout ceci peut évidemment se changer, voyez plus loin quand on parlera des thèmes).
Pour avoir les pages enregistrées sous un nom de fichier de son
choix, on utilise save_as :
% cat content/pages/mentions-legales.md
Title: Mentions légales
save_as: legal.html
Faites ce que vous voulez avec ce site.
(Voir la bonne
FAQ sur ce sujet.) Évidemment, dans ce cas, le menu
automatique ne marchera plus et il faudra, dans le thème qu'on
développe, mettre son menu à soi. Mais je n'ai pas encore expliqué
les thèmes. Avant cela, notons qu'on peut redéfinir la page
d'accueil de
la même façon, avec save_as:
index.html.
Alors, les thèmes, c'est quoi ? C'est un ensemble
de gabarits HTML, de
fichiers CSS et d'images qui, ensemble,
vont assurer la cohérence du site Web, ses menus, son apparence
graphique. Si vous avez fait votre propre site en suivant les
instructions ci-dessus, vous avez utilisé le thème par défaut, qui
se nomme « simple » et qui est livré avec
Pelican. C'est lui qui définit par exemple le pied de page
« Proudly powered by Pelican, which takes great advantage
of Python ». S'il ne vous plait pas, vous pouvez avoir
votre propre thème, soit en l'écrivant en partant de zéro (c'est
bien
documenté) soit en utilisant un thème existant (on en
trouve en ligne, par exemple en http://pelicanthemes.com/). Et, bien sûr, vous pouvez
aussi prendre un thème existant et le modifier. Comme exemple, je
vais faire un thème ultra-simple en partant de zéro.
Appelons-le « red » :
% mkdir -p themes/red
% mkdir -p themes/red/static/css
% mkdir -p themes/red/templates
% emacs themes/red/templates/base.html
% emacs themes/red/templates/page.html
% emacs themes/red/templates/article.html
Le code de base.html est disponible dans ce fichier, celui de
page.html dans celui-ci et enfin celui
de article.html à cet
endroit. base.html définit les
éléments communs aux articles et aux pages. Ainsi, il contient
<footer>Mon joli
site.</footer>, qui spécifie le pied qu'on
trouvera dans tous les fichiers HTML.
Pelican permet également d'utiliser des variables et des tests,
avec le moteur de gabarit Jinja. C'est ainsi qu'on spécifie le titre
d'un article : {{ SITENAME }} - {{ article.title
}} indique que le titre comprend d'abord le nom du site
Web, puis un tiret, puis la variable
article.titre, obtenue via la métadonnée
Title: mise plus haut dans le source
Markdown.
Une fois le thème créé, on peut l'utiliser en le spécifiant sur la ligne de commande :
% pelican -t themes/red content
Ou bien si on veut utiliser make publish
comme avant, on ajoute juste dans
pelicanconf.py :
THEME = 'themes/red'
Notez qu'on n'est pas obligé de mettre le thème dans un
sous-dossier de themes. Si on ne compte pas
changer de thème de temps en temps, on peut aussi placer
static et templates
dans le dossier themes, voire directement à
la racine du répertoire de développement.
On a rarement un thème qui marche du premier coup, il y a
plusieurs essais, donc un truc utile est la commande
make regenerate, qui tourne en permanence,
surveille les fichiers, et regénère automatiquement et
immédiatement les fichiers HTML en cas de changement. Une autre
commande utile est make serve qui lance un
serveur Web servant le contenu créé, le site étant désormais
accessible en http://localhost:8000/
(personnellement, x-www-browser
output/index.html me suffit).
Si les fonctions de base ne suffisent pas, Pelican peut ensuite être étendu de plusieurs façons différentes. Notez d'abord que Jinja fournit beaucoup de possibilités (cf. sa documentation). Ensuite, imaginons par exemple qu'on veuille inclure des données CSV dans ses articles ou pages. On peut écrire un plugin (c'est bien documenté) mais il existe aussi plein de plugins tout faits, n'hésitez pas à chercher d'abord si l'un d'eux vous convient (ici, peut-être Load CSV). Mais on peut aussi envisager un programme dans le langage de son choix, qui lise le CSV et produise le Markdown. Ou bien, puisque les fichiers de configuration sont du Python, on peut y mettre du code Python, produisant des variables qu'on utilisera ensuite dans son thème (notez qu'on peut définir ses propres métadonnées).
Dernière solution, étendre Markdown avec une extension au paquetage
Python markdown, qu'utilise Pelican. Ces
extensions sont bien
documentées, et il existe un tutoriel. On
peut alors programmer dans l'extension tout ce qu'on veut, et
produire le HTML résultant, avec Element
Tree. C'est personnellement ce que j'utilise le plus
souvent.
Pour terminer avec Pelican, quelques bonnes lectures :
- Je rappelle que la documentation officielle est très bien faite (quoique manquant d'exemples),
- Un bon récit d'une utilisation de Pelican (avec création de thème),
- Un autre récit, avec une bonne liste d'avantages des sites statiques,
- Et un dernier retour d'expérience,
- Un exemple amusant d'une extension Markdown,
- Une liste de sites utilisant Pelican, et les sources de ces sites.
Voici pour Pelican. Et les autres générateurs de sites statiques, du moins les quelques-uns que j'ai testés, parmi la grande variété disponible ? Actuellement, Hugo semble le plus à la mode. Il est programmé en Go. Comme Pelican, il est très nettement orienté vers la réalisation de blogs chronologiques. Le paquetage Debian est très ancien par rapport à la syntaxe toujours changeante, et je n'ai pas réussi à traiter un seul des thèmes existants, n'obtenant que des messages incompréhensibles. Je ne suis pas allé plus loin, je ne sais notamment pas si Hugo peut être utilisé pour des sites qui sont des ensembles de pages plutôt que des blogs.
Au contraire d'Hugo, tout beau et tout neuf, Jekyll est stable et fait du
bon travail. Un coup de jekyll build et on a
son site dans le répertoire _site. On peut
aussi faire un site
non-blog. Jekyll
est lui, écrit en Ruby. Par contre, je
n'ai pas bien compris comment on créait son thème, et c'est une
des raisons pour lesquelles j'ai choisi Pelican.
Au contraire de Jekyll, Gutenberg est récent, et développé dans un langage récent, Rust. Trop nouveau pour moi, il nécessite le gestionnaire de paquetages Cargo qui n'existe apparemment pas sur Debian stable.
Écrit dans un langage bien moins commun, Hakyll est en Haskell, et même le fichier de configuration est un programme Haskell. Mais il est inutilisable sur Debian stable, en raison d'une bogue qui affiche un message très clair :
AesonException "Error in $.packages.cassava.constraints.flags: failed to parse field packages: failed to parse field constraints: failed to parse field flags: Invalid flag name: \"bytestring--lt-0_10_4\""
Enfin, j'ai regardé du côté de PyBlosxom mais j'ai renoncé, trouvant la documentation peu claire pour moi.
Les solutions les plus simples étant souvent les meilleures, il
faut se rappeler qu'on peut tout simplement faire un site statique
avec pandoc. pandoc prend des fichiers
Markdown (et bien d'autres formats) et un
coup de pandoc --standalone --to html5 -o index.html
index.md (qu'on peut automatiser avec
make) produit de l'HTML. Si on veut donner une
apparence cohérente à ses pages Web, pandoc a égakement un système
de gabarits
(mais, la plupart du temps, il n'est même pas nécessaire, utiliser
le gabarit par défaut et définir
quelques variables sur la ligne de commande de pandoc peut suffire).
Comme je l'ai dit au début, il y a vraiment beaucoup de générateurs de sites statiques et je suis très loin de les avoir tous testés. Rien que dans les paquetages Debian, il y a encore staticsite et blogofile.
Vu le grand nombre de générateurs de sites Web statiques, on ne s'étonne pas qu'il existe plusieurs articles de comparaison :
- « Comparisons with other static site generators » est une comparaison de Gutenberg avec d'autres générateurs,
- « StaticGen » est très détaillé, avec beaucoup d'informations factuelles,
- « HTML and Static site generators » est plus synthétique, et plus adapté à celui ou celle qui a un projet concret, le précédent article étant plutôt pour celle ou celui qui veut tout apprendre.
Et, évidemment, il existe toujours la solution bien geek consistant à développer son propre outil, comme je l'avais fait pour ce blog.
L'article seul
Fiche de lecture : Click here to kill everybody
Auteur(s) du livre : Bruce Schneier
Éditeur : Norton
978-0393-60888-5
Publié en 2018
Première rédaction de cet article le 6 octobre 2018
D'accord, le titre est vraiment putaclic mais il résume bien le livre. Bruce Schneier se pose la question de la sécurité de l'Internet des Objets, faisant notamment remarquer que le conséquences d'une panne ou d'une attaque changent. Contrairement à la sécurité informatique classique, avec l'Internet des Objets, il peut y avoir des conséquences dans le monde physique, y compris des conséquences mortelles.
Schneier est l'auteur de nombreux livres sur la sécurité (pas forcément uniquement la sécurité informatique). Il explique toujours bien et synthétise avec talent les questions de sécurité. C'est d'autant plus méritoire que la sécurité est un sujet hautement politisé, où il est difficile de parler sérieusement. Pensons par exemple aux mesures adoptées pour lutter contre l'ennemi djihadiste. Dès qu'on fait entendre un point de vue critique, ou simplement nuancé, on se fait accuser d'être « trop mou face au terrorisme » voire « complice des terroristes ». Schneier appelle au contraire à envisager la sécurité comme un sujet sérieux, et donc à s'abstenir de ce genre d'accusations tranchantes. Dans ses livres (comme « Beyond Fear ») et sur son blog, il remet sans cesse en cause les certitudes, critique le « show sécuritaire », demande qu'on évalue les mesures de sécurité, leur efficacité et leur coût, au lieu de simplement dire « il faut faire quelque chose, peu importe quoi ».
Le sujet de ce livre (plutôt un essai relativement court) est l'Internet des Objets. C'est un terme marketing, flou et mal défini. Schneier lui préfère celui d'« Internet+ », dont il reconnait qu'il n'est pas meilleur mais qu'il a l'avantage de forcer à reconsidérer de quoi on parle. En gros, il y a aujourd'hui énormément d'« objets » connectés à l'Internet. Ils ont en commun d'être des ordinateurs, mais de ne pas être perçus comme tels. Ce sont des ordinateurs, car ils en ont le matériel et surtout le logiciel, avec ses bogues et ses failles de sécurité. (Pour paraphraser l'auteur, « Un grille-pain moderne est un ordinateur avec des résistances chauffantes en plus ».) Mais ils ne sont pas perçus comme tels, donc le logiciel ne fait l'objet d'aucune analyse de sécurité, le problème de la mise à jour n'est pas envisagé, et les sociétés qui produisent ces objets n'ont aucune culture de sécurité, et refont en 2018 les erreurs que l'industrie informatique faisait il y a 20 ans (mots de passe par défaut, menaces judiciaires contre ceux qui signalent des failles de sécurité, tentative d'empêcher la rétro-ingénierie, affirmations grotesques du genre « notre système est parfaitement sécurisé »). La sécurité des objets connectés, de l'« Internet+ » est donc abyssalement basse. À chaque conférence de sécurité, on a de nombreux exposés montrant la facilité avec laquelle ces objets peuvent être piratés. Schneier cite une classe de politique du monde numérique où, au cours d'un travail pratique, la moitié des étudiants ont réussi à pirater une poupée connectée, alors même qu'ils et elles sont des juristes ou des étudiants en sciences politiques, pas des pentesteurs.
Tant que l'object connecté est une brosse à dents, et que le piratage a pour seule conséquence d'empêcher cette brosse de fonctionner, ce n'est pas trop grave. Mais beaucoup d'objets ont des capacités bien plus étendues, et qui touchent le monde physique (d'où le titre sensationnaliste du livre). Si l'objet est une voiture, ou un dispositif de sécurité d'une usine, ou un appareil électrique potentiellement dangereux, les conséquences peuvent être bien plus graves. On est loin des problèmes de sécurité de WordPress, où la seule conséquence en cas de piratage est l'affichage d'un message moqueur sur la page d'accueil du site Web !
(Je rajoute, à titre personnel - ce n'est pas dans le livre, qu'il est scandaleux que, pour beaucoup d'objets, l'acheteur n'ait plus le choix. Aujourd'hui, acheter une télévision ou une voiture qui ne soit pas connectée, est devenu difficile, et demain, ce sera impossible. Un changement aussi crucial dans nos vies a été décidé sans que le citoyen ait eu son mot à dire.)
Schneier explique en détail les raisons techniques, pratiques et financières derrière l'insécurité informatique mais il note que cette insécurité ne déplait pas à tout le monde. Des services étatiques comme la NSA (dont la mission est justement de pirater des systèmes informatiques) aux entreprises qui gagnent de l'argent en exploitant des données personnelles, des tas d'organisations profitent de cette insécurité, ce qui est une des raisons pour laquelle elle ne se réduit guère. (Pour la NSA, Schneier préconise de la séparer en deux organisations radicalement distinctes, une chargée de l'attaque et une de la défense. Actuellement, la NSA est censée faire les deux, et, en pratique, l'attaque est toujours jugée plus importante. Cela amène la NSA, par exemple, à ne pas transmettre aux auteurs de logiciels les failles de sécurité détectées, de façon à pouvoir les exploiter. Le système français a aussi ses défauts mais, au moins, l'attaque - armée et DGSE - et la défense - ANSSI - sont clairement séparées, et la défense ne dépend pas de l'armée ou de la police, qui sont intéressées à conserver l'insécurité informatique.)
Notez que le livre est clairement écrit d'un point de vue états-unien et parle surtout de la situation dans ce pays.
Et les solutions ? Parce que ce n'est pas tout de faire peur aux gens, avec des scénarios qui semblent sortis tout droit des séries télé « Black Mirror » ou « Mr Robot ». Il faut chercher des solutions. L'auteur expose successivement le quoi, le comment et le qui. Le quoi, c'est le paysage que nous voudrions voir émerger, celui d'un « Internet+ » dont la sécurité ne soit pas risible, comme elle l'est actuellement. Les solutions ne vont pas de soi, car elles auront forcément un coût, et pas uniquement en argent, mais aussi en facilité d'usage et en générativité (pour reprendre le terme de Jonathan Zittrain, qui désigne ainsi la capacité d'une technique à faire des choses non prévues par ses concepteurs). Un exemple d'un choix difficile : le logiciel de l'objet doit-il être mis à jour automatiquement et à distance ? Du point de vue de la sécurité, c'est clairement oui, mais cela ouvre des tas de problèmes, comme la possibilité pour le vendeur de garder un contrôle sur l'objet vendu (cf. RFC 8240 pour les détails). Autre point qui sera difficile à avaler (et l'auteur n'en parle d'ailleurs que très peu) : il ne faudra pas tout connecter. Connecter des frigos et des télés à l'Internet est peut-être pratique et sexy mais c'est dangereusement irresponsable.
Le comment, ce sont les moyens d'y arriver. Et le qui, c'est la question brûlante de savoir quelle organisation va devoir agir.
Schneier ne croit pas au marché, qui a largement démontré son incapacité à résoudre les problèmes de sécurité. Cela semble une évidence mais il ne faut pas oublier que Schneier écrit pour un public états-unien, pour qui le marché est sacré, et toute suggestion comme quoi le marché n'est pas parfait est vite assimilée au communisme. Bruce Schneier suggère donc un rôle essentiel pour l'État, une position courageuse quand on écrit aux États-Unis. Il ne se fait pas d'illusions sur l'État (il décrit plusieurs cas où l'État, ses lois, ses règles et ses pratiques ont contribué à aggraver le problème, comme par exemple la loi DMCA) mais il ne voit pas d'autre option réaliste, en tout cas certainement pas l'« auto-régulation » (autrement dit le laisser-faire) chère à la Silicon Valley.
Bruce Schneier est bien conscient qu'il n'y a pas de solution idéale, et que la sécurisation de l'Internet+ sera douloureuse. Si vous lisez ce livre, ce que je vous recommande fortement, vous ne serez certainement pas d'accord avec tout, comme moi. (Par exemple, la proposition de faire du FAI le responsable de la sécurité des réseaux des utilisateurs à la maison m'inquiète. Et sa suggestion d'ajouter encore des règles et des processus, alors qu'au contraire cela sert en général à encourager l'irresponsabilité n'est pas idéale non plus.) Mais ne nous faisons pas d'illusion : on n'aura pas de solution parfaite. Et, si nous ne faisons rien, nous aurons peut-être des « solutions » catastrophiques, par exemple des règles ultra-liberticides imposées en mode panique par des politiciens affolés, après une grosse crise due à un objet connecté.
Vous serez peut-être également intéressé·e par cet exposé de l'auteur au sujet de ce livre.
L'article seul
Conférence « Web et vie privée » au Centre Social des Abeilles
Première rédaction de cet article le 30 septembre 2018
Le 28 septembre, au Centre Social des Abeilles à Quimper, j'ai participé à un apéro/discussion sur le thème « Web et vie privée ». Je faisais l'introduction à la discussion
Voici les supports de cette introduction :
- Version adaptée à l'écran,
- Version adaptée à l'impression sur des arbres morts,
- Source en LaTeX/Beamer.
La vidéo est en ligne. La longue discussion qui a suivi ne l'est pas, pour respecter la vie privée des participants. (Une autre copie de la vidéo est sur le site original.)
Merci à Brigitte pour l'idée et l'organisation, à Salim pour l'accueil, à René pour la vidéo et à tou·te·s les participant·e·s, nombreu·x·ses et acti·f·ve·s. Un compte-rendu de cet apéro-discussion, avec plans pour le futur a été écrit par Brigitte. (Il y a aussi mon interview à France Bleu mais le titre choisi par la rédaction est trompeur.)
L'article seul
[DNS] CNAME à l'apex d'une zone, pourquoi et comment ?
Première rédaction de cet article le 23 septembre 2018
Un problème courant que rencontrent les techniciens débutant en DNS est « je voudrais mettre un enregistrement CNAME - un alias - à l'apex de ma zone DNS mais l'ordinateur ne veut pas ». Pourquoi est-ce refusé ? Comment l'autoriser sans casser tout l'Internet ? La discussion dure depuis de nombreuses années et, je vous révèle tout de suite la conclusion de cet article, n'est pas près de se terminer.
Commençons par une description concrète du problème. Alice,
technicienne DNS, a été informée par le
webmestre de sa boîte (nommée Michu SA et ayant le nom
de domaine michu.example) que le serveur Web de ladite boîte est
désormais hébergé par un CDN nommé Example
et qu'il est accessible par le nom
michu-sa.example-cdn.net. Et le webmestre
voudrait que les visiteurs puissent juste taper
https://michu.example/. Alice connait assez
le DNS pour savoir qu'il y a des alias (un type d'enregistrement
nommé CNAME) et elle met donc dans le fichier de zone :
michu.example. IN CNAME michu-sa.example-cdn.net.
Ça devrait contenter tout le monde, pense-t-elle. Mais, si elle connait assez le DNS pour savoir que le type d'enregistrement CNAME existe, elle ne le connait pas assez pour avoir lu le RFC 1034, section 3.6.2 : If a CNAME RR is present at a node [a node in the domain name tree, so a domain name], no other data should be present. Et c'est le drame, au chargement de la zone, NSD dit error: /etc/nsd/michu.example:19: CNAME and other data at the same name. Si Alice avait utilisé BIND, elle aurait eu une erreur similaire : dns_master_load: michu.example:19: michu.example: CNAME and other data. L'enregistrement CNAME rentre en conflit avec les enregistrements qu'on trouve à l'apex d'une zone, comme le SOA et les NS. La solution simple ne marche donc pas.
www.michu.example. IN CNAME michu-sa.example-cdn.net.
aurait marché mais le service communication voudrait un
URL sans www devant.
Au passage, pourquoi est-ce que c'est interdit de mettre un alias et d'autres données au même nom ? La principale raison est qu'un enregistrement CNAME est censé créer un alias, un synonyme. Si on pouvait écrire :
michu.example. IN AAAA 2001:db8::ff
michu.example. IN CNAME michu-sa.example-cdn.net.
Et qu'un client DNS demande l'enregistrement de type AAAA pour
michu.example, que faudrait-il lui répondre ?
2001:db8::ff, ou bien l'adresse IPv6 de
michu-sa.example-cdn.net ? Avec
l'interdiction de coexistence du CNAME et d'autres données, le
problème est réglé.
Bon, se dit Alice, ça ne marche pas, mais on peut essayer
autrement : cherchons l'adresse IP correspondant au nom
michu-sa.example-cdn.net et mettons-là dans
le fichier de zone :
% dig +short AAAA michu-sa.example-cdn.net
2001:db8:1000:21::21:4
michu.example. IN AAAA 2001:db8:1000:21::21:4
Cette fois, ça marche, mais il y a plusieurs inconvénients :
- Le principal est que le CDN peut changer l'adresse IP à tout moment, sans prévenir. Au minimum, il faudra donc retester l'adresse, et changer la zone. À la main, aucune chance que ce soit fait assez souvent (il faut respecter le TTL du CDN). Il faudra donc l'automatiser.
- Des CDN renvoient une adresse IP différente selon l'adresse IP source du client DNS, afin de diriger vers un serveur « proche ». L'astuce d'Alice casse ce service.
Bref, que faire ? Plusieurs sociétés ont développé une solution non-standard ne marchant que chez eux. L'IETF, dont c'est le rôle de développer des solutions standards, s'est penchée à de nombreuses reprises sur la question, et d'innombrables brouillons ont été produits, sans qu'un consensus ne se dégage. Déjà, il n'y a pas d'accord clair sur le cahier des charges. (Le scénario d'usage présenté plus haut n'est qu'un des scénarios possibles.) Je ne vais pas présenter tous ces brouillons, juste dégager les pistes de solution. Mais, comme vous le verrez, aucune n'est parfaite. Une des contraintes fortes est qu'on sait bien que, quelle que soit la décision prise par l'IETF, le nouveau logiciel, mettant en œuvre la décision, ne sera pas déployé immédiatement : il faudra des années, voire davantage, pour qu'une part significative des clients et serveurs DNS soient à jour. Il faudra donc, non seulement modifier les règles du DNS, mais également spécifier ce qu'il faudra faire pendant la très longue période de transition. (Et, s'il vous plait, pas de yakafokon du genre « les gens n'ont qu'à mettre à jour leur logiciel plus souvent ». Cela n'arrivera pas.)
Voici maintenant les diverses pistes envisagées. Avant de dire « ah, celle-ci a l'air cool », prudence. Rappelez-vous qu'il existe de nombreux cas (minimisation de la requête - RFC 9156 - ou pas, résolveur chaud - ayant déjà des informations dans sa mémoire - ou pas), et que la période de transition va être très longue, période pendant laquelle il faut que cela marche pour les anciens et pour les modernes.
Première idée, décider qu'il n'y a pas de problème. On laisse le DNS comme il est et le problème doit être entièrement traité côté avitaillement (le type qui édite le fichier de zone, ou bien le logiciel qui le produit). C'est l'idée de base du hack utilisé par Alice plus haut. Cela peut se faire avec un script shell du genre :
#!/bin/sh
zonefile=$1
while :
do
target=$(awk '/ALIAS/ {print $3}' $zonefile)
ttl=$(dig A $target | awk "/^$target.*IN\s+A/ {print \$2}" | head -n 1)
ip=$(dig A $target | awk "/^$target.*IN\s+A/ {print \$5}" | head -n 1)
sed "s/IN.*ALIAS.*/ IN $ttl A $ip/" $zonefile > ${zonefile}-patched
echo "Patched with IP address $ip"
sleep $ttl
done
(En production, on voudra probablement quelque chose de plus propre, notamment en gestion d'erreurs, et de traitement des réponses multiples.)
Comme indiqué plus haut, cela marche, mais cela ne permet pas de tirer profit des caractéristiques du CDN, par exemple de la réponse différente selon le client. On peut voir cette variation de la réponse, en demandant à cent sondes RIPE Atlas :
% blaeu-resolve --requested 100 --type A www.elysee.fr [208.178.167.254 4.26.226.126 4.27.28.126 8.27.4.254] : 1 occurrences [8.254.28.126 8.254.45.254 8.27.151.253 8.27.226.126] : 1 occurrences [205.128.73.126 206.33.35.125 209.84.20.126 8.27.243.253] : 1 occurrences [207.123.56.252 4.26.228.254 4.27.28.126 8.26.223.254] : 1 occurrences [205.128.90.126 209.84.9.126 8.254.214.254 8.254.94.254] : 1 occurrences [8.254.164.126 8.254.209.126 8.254.210.126 8.27.9.254] : 1 occurrences [4.23.62.126 4.26.227.126 8.254.173.254 8.254.95.126] : 1 occurrences [207.123.39.254 8.254.196.126 8.254.219.254 8.27.5.254] : 2 occurrences [120.28.42.254 36.66.10.126] : 1 occurrences ...
Deuxième idée, relâcher la contrainte donnée dans le RFC 1034 et autoriser le CNAME à l'apex (note au passage : beaucoup de gens sont nuls en arbrologie et appellent incorrectement l'apex la racine, ce qui a un tout autre sens dans le DNS). L'expérience a été tentée par Ondřej Surý au hackathon de l'IETF à Montréal en juillet 2018 (les résultats complets de l'équipe DNS sont dans cette présentation). Une fois le serveur faisant autorité modifié pour autoriser le CNAME à l'apex, on l'interroge via un résolveur. En gros, dans la plupart des cas, le CNAME masque les autres enregistrements (ce qui est logique puisqu'il est censé être seul). Ainsi, si on a :
michu.example. IN CNAME foobar.example.com.
IN MX 10 gimmedata.gafa.example.
Un client DNS qui demande le MX de
michu.example pour lui envoyer du courrier
récupérera le MX de foobar.example.com, le
vrai MX étant masqué.
Plus ennuyeux est le fait que cela dépend : dans certains cas, un autre enregistrement que celui du CNAME est récupéré. On ne peut rien reprocher aux logiciels qui font cela : ils sont conformes aux RFC actuels. Cette variabilité rend difficile de simplement autoriser le CNAME à l'apex.
Troisième possibilité : on peut aussi décider que le résolveur fera l'essentiel du boulot. On crée un nouveau type d'enregistrement, mettons SEEALSO, qui peut coexister avec les types existants :
michu.example. IN SEEALSO michu-sa.example-cdn.net. michu.example. IN MX 10 gimmedata.gafa.example.
Le serveur faisant autorité n'aurait rien de particulier à faire, il renvoie juste le SEEALSO au résolveur (en terminologie DNS, on dit « il n'y a pas de traitement additionnel »). Le résolveur va alors, recevant le SEEALSO, le suivre. Le principal problème de cette approche est qu'initialement, peu de résolveurs auront le nouveau code, ce qui ne motivera pas les gens qui gèrent les zones à ajouter ce SEEALSO.
Quatrième idée, toujours avec un nouveau type d'enregistrement (et donc avec les problèmes de déploiement que cela pose dans un Internet non centralisé), généralement appelé ANAME ou ALIAS. L'idée est qu'on mettra dans la zone :
michu.example. IN ANAME michu-sa.example-cdn.net. michu.example. IN MX 10 gimmedata.gafa.example.
Le ANAME, contrairement au CNAME, a le droit de coexister avec
d'autres enregistrements, ici un MX. L'idée est que le serveur
faisant autorité, chargeant la zone, va résoudre la cible (la
partie droite du ANAME) et répondre avec l'adresse IP de la cible
lorsqu'on l'interrogera. Le résolveur ne voit donc pas le CDN, si
l'adresse au CDN est 2001:db8::ff, le résolveur
recevra :
michu.example. 3600 IN AAAA 2001:db8::ff
Le serveur faisant autorité, ayant chargé la zone, sera responsable de changer cette valeur lorsque le TTL expirera.
On voit que cette solution nécessite que le serveur faisant autorité soit également résolveur. C'est considéré comme une mauvaise pratique, car cela complique sérieusement le débogage : on ne sait plus d'où viennent les données, et celles du résolveur peuvent potentiellement masquer celles qui font autorité. D'ailleurs, les meilleurs logiciels serveur faisant autorité, comme NSD, n'ont pas du tout de code pour faire de la résolution (cette simplicité améliore grandement la sécurité).
D'autre part, introduire un nouveau type de données DNS n'est jamais évident, cela nécessite de modifier les serveurs faisant autorité (les résolveurs, eux, n'ont pas besoin d'être modifiés, pour ce ANAME), mais également les logiciels d'avitaillement (interfaces web chez l'hébergeur DNS permettant de gérer sa zone).
Cette idée de ANAME pose également des problèmes à DNSSEC. Comme le serveur faisant autorité va devoir modifier le contenu de la zone fréquemment (les TTL des CDN sont souvent courts), il faudra qu'il signe les enregistrements créés, ce qui obligera à avoir la clé privée disponible (on préfère parfois la garder hors-ligne, pour des raisons de sécurité, ce qui est opérationnellement faisable si on ne modifie pas la zone trop souvent). Et cela nécessitera un serveur qui peut signer dynamiquement, ou bien des bricolages particuliers.
On peut avoir des tas de variantes sur cette idée. C'est d'ailleurs une des raisons pour laquelle le débat est compliqué. Chaque idée a des sous-idées. Par exemple, puisque dans ce cas, le serveur faisant autorité est également résolveur, on pourrait renvoyer le ANAME au client DNS, avec l'adresse IP du CDN, pour gagner du temps. La réponse serait :
;; ANSWER SECTION: michu.example. 3600 IN ANAME michu-sa.example-cdn.net. ;; ADDITIONAL SECTION: michu-sa.example-cdn.net. 600 IN AAAA 2001:db8::ff
Plus de problèmes avec DNSSEC cette fois, puisqu'on n'importerait
plus de données extérieures dans la zone
michu.example. Le principal problème de cette
variante est que l'optimisation serait probablement inutile : un
résolveur DNS raisonnablement paranoïaque, craignant une attaque
par empoisonnement, ignorerait la section additionnelle, puisque le
serveur interrogé ne fait autorité que pour
michu.example, pas pour
example-cdn.net. On serait donc ramené à la
troisième idée (le résolveur fait tout).
Le projet ANAME avait fait l'objet d'un Internet
Draft, draft-ietf-dnsop-aname, mais
qui n'a finalement mené nulle part.
Cinquième idée, résoudre le problème côté client, comme dans la troisième, mais en modifiant les applications et non plus les résolveurs. Après tout, le principal scénario d'usage est pour HTTP. Ce sont les gens du Web qui se plaignent de ne pas pouvoir mettre des CNAME à l'apex. Les gens de SMTP ou de XMPP ne se plaignent pas, car ils ont un système d'indirection. On indique dans le DNS le nom du serveur pour un domaine donné (enregistrement MX pour SMTP et les plus généraux enregistrements SRV pour XMPP). HTTP est hélas le seul protocole normalisé qui a « oublié » de faire une indirection entre domaine et serveur. C'est une de ses plus graves fautes de conception. (Un protocole comme SSH est un cas à part puisque son but est de se connecter à une machine spécifique.) Donc, la meilleure solution, du point de vue de l'architecture de l'Internet, est de modifier HTTP pour que les clients HTTP utilisent SRV. La zone serait alors :
michu.example. IN SRV 0 1 80 michu-sa.example-cdn.net. ; Autres types michu.example. IN MX 10 gimmedata.gafa.example.
SRV, normalisé dans le RFC 2782, a plein d'autres possibilités très pratiques, comme d'indiquer plusieurs serveurs, avec des poids différents (fournissant ainsi un système non centralisé de répartition de charge) et des priorités différentes (les serveurs de faible priorité n'étant sollicité qu'en cas de panne des autres).
Tout cela pose évidemment un réel problème de déploiement puisqu'il
faudrait modifier tous les clients HTTP (rappelez-vous qu'il n'y a
pas que les navigateurs !) Tant qu'il n'y
aura pas de déploiement significatif, les titulaires de noms de
domaine devront avoir le SRV et les
enregistrements classiques. D'autre part, HTTP ayant évolué sans
les enregistrements SRV, il y a quelques points d'accrochage. Par
exemple, SRV permet d'indiquer le port et
cela peut rentrer en conflit avec le concept d'origine du Web, qui
est essentiel pour sa sécurité (http://example.com/ et
http://example.com:3000/ sont des origines
différentes, cf. RFC 6454). Il y a aussi
quelques pièges liés au SRV (voir mes notes à ce
sujet et, cette
discussion au sujet des SRV dans Mastodon.)
Et je n'ai pas cité toutes les idées, comme la possibilité d'utiliser Alt-Svc (RFC 7838).
Conclusion ? Le problème est bien sûr réel et se pose à beaucoup d'acteurs de l'Internet. Mais il n'y a pas de solution idéale. Il faudra, soit continuer comme actuellement si l'IETF n'arrive pas à un accord, soit adopter une solution qui, de toute façon, créera ses propres problèmes. Personnellement, je pense que la solution la plus propre serait de modifier HTTP, pour utiliser une indirection, comme tous les autres protocoles. Si cela n'est pas possible, il vaut encore mieux ne rien faire : le dromadaire est assez chargé comme cela.
L'article seul
Fiche de lecture : Le livre-échange
Auteur(s) du livre : Mariannig Le Béchec, Dominique
Boullier, Maxime Crépel
Éditeur : C & F Éditions
978-2-915825-76-3
Publié en 2018
Première rédaction de cet article le 30 août 2018
Le livre, sous ses deux formes, papier ou numérique, est un objet de passion depuis longtemps. Ce ne sont pas juste des lettres qu'on lit. Les lecteurices ont des usages, des pratiques, ils et elles se prêtent les livres, les annotent, les commentent, les échangent, en parlent sur leur blog…
Ce livre est une étude de ces pratiques. Que font les lecteurs de leur livre ? Pour chaque pratique, des lecteurices sont interrogé·e·s, des experts commentent parfois. On ne parle pas du texte, uniquement des usages que les lecteurices font du livre.
Les usages du livre sur papier forment l'essentiel de cet ouvrage, qui note que le livre numérique fait apparemment peu l'objet de ces diverses formes d'échange. On le lit, mais c'est tout.
Les usages du livre papier sont très variés (sans compter, dirait le cynique, celui de caler les meubles). Et les avis des lecteurices sont également divers. L'annotation, par exemple, est sans doute le chapitre où les avis sont les plus tranchés, entre celles et ceux qui considèrent le livre comme « sacré », et qui ne se permettraient pas d'y ajouter la moindre marque, et ceux et celles qui griffonnent, corrigent, et ajoutent des commentaires au stylo rouge. Le livre n'est clairement pas un objet comme les autres. À propos de l'achat de livres d'occasion, une lectrice explique qu'elle n'y recourt pas, car elle lit au lit et qu'elle ne veut pas faire rentrer dans son lit, espace intime, des livres déjà manipulés par un inconnu…
En résumé, un bel hommage à l'abondance de pratiques sociales autour du livre.
Déclaration de conflit d'intérêt : j'ai reçu un exemplaire de ce livre gratuitement.
Sur ce livre, on peut aussi lire :
- « Pourquoi Internet n'a pas tué le papier », par les auteurs.
L'article seul
RFC 8446: The Transport Layer Security (TLS) Protocol Version 1.3
Date de publication du RFC : Août 2018
Auteur(s) du RFC : E. Rescorla (RTFM)
Chemin des normes
Réalisé dans le cadre du groupe de travail IETF tls
Première rédaction de cet article le 11 août 2018
Après un très long processus, et d'innombrables polémiques, la nouvelle version du protocole de cryptographie TLS, la 1.3, est enfin publiée. Les changements sont nombreux et, à bien des égards, il s'agit d'un nouveau protocole (l'ancien était décrit dans le RFC 5246, que notre nouveau RFC remplace).
Vous pouvez voir l'histoire de ce RFC sur la Datatracker de l'IETF. Le premier brouillon a été publié en avril 2014, plus de trois années avant le RFC. C'est en partie pour des raisons techniques (TLS 1.3 est très différent de ses prédécesseurs) et en partie pour des raisons politiques. C'est que c'est important, la sécurité ! Cinq ans après les révélations de Snowden, on sait désormais que des acteurs puissants et sans scrupules, par exemple les États, espionnent massivement le trafic Internet. Il est donc crucial de protéger ce trafic, entre autres par la cryptographie. Mais dire « cryptographie » ne suffit pas ! Il existe des tas d'attaques contre les protocoles de cryptographie, et beaucoup ont réussi contre les prédécesseurs de TLS 1.3. Il était donc nécessaire de durcir le protocole TLS, pour le rendre moins vulnérable. Et c'est là que les ennuis ont commencé. Car tout le monde ne veut pas de la sécurité. Les États veulent continuer à espionner (le GCHQ britannique s'était clairement opposé à TLS 1.3 sur ce point). Les entreprises veulent espionner leurs employés (et ont pratiqué un lobbying intense contre TLS 1.3). Bref, derrière le désir de « sécurité », partagé par tout le monde, il y avait un désaccord de fond sur la surveillance. À chaque réunion de l'IETF, une proposition d'affaiblir TLS pour faciliter la surveillance apparaissait, à chaque fois, elle était rejetée et, tel le zombie des films d'horreur, elle réapparaissait, sous un nom et une forme différente, à la réunion suivante. Par exemple, à la réunion IETF de Prague en juillet 2017, l'affrontement a été particulièrement vif, alors que le groupe de travail TLS espérait avoir presque fini la version 1.3. Des gens se présentant comme enterprise networks ont critiqué les choix de TLS 1.3, notant qu'il rendait la surveillance plus difficile (c'était un peu le but…) gênant notamment leur débogage. Ils réclamaient un retour aux algorithmes n'ayant pas de sécurité persistante. Le début a suivi le schéma classique à l'IETF : « vous réclamez un affaiblissement de la sécurité » vs. « mais si on ne le fait pas à l'IETF, d'autres le feront en moins bien », mais, au final, l'IETF est restée ferme et n'a pas accepté de compromissions sur la sécurité de TLS. (Un résumé du débat est dans « TLS 1.3 in enterprise networks ».)
Pour comprendre les détails de ces propositions et de ces rejets, il faut regarder un peu en détail le protocole TLS 1.3.
Revenons d'abord sur les fondamentaux : TLS est un mécanisme permettant aux applications client/serveur de communiquer au travers d'un réseau non sûr (par exemple l'Internet) tout en empêchant l'écoute et la modification des messages. TLS suppose un mécanisme sous-jacent pour acheminer les bits dans l'ordre, et sans perte. En général, ce mécanisme est TCP. Avec ce mécanisme de transport, et les techniques cryptographiques mises en œuvre par dessus, TLS garantit :
- L'authentification du serveur (celle du client est facultative), authentification qui permet d'empêcher l'attaque de l'intermédiaire, et qui se fait en général via la cryptographie asymétrique,
- La confidentialité des données (mais attention, TLS ne masque pas la taille des données, permettant certaines analyses de trafic),
- L'intégrité des données (qui est inséparable de l'authentification : il ne servirait pas à grand'chose d'être sûr de l'identité de son correspondant, si les données pouvaient être modifiées en route).
Ces propriétés sont vraies même si l'attaquant contrôle complètement le réseau entre le client et le serveur (le modèle de menace est détaillé dans la section 3 - surtout la 3.3 - du RFC 3552, et dans l'annexe E de notre RFC).
TLS est un protocole gros et compliqué (ce qui n'est pas forcément optimum pour la sécurité). Le RFC fait 147 pages. Pour dompter cette complexité, TLS est séparé en deux composants :
- Le protocole de salutation (handshake protocol), chargé d'organiser les échanges du début, qui permettent de choisir les paramètres de la session (c'est un des points délicats de TLS, et plusieurs failles de sécurité ont déjà été trouvées dans ce protocole pour les anciennes versions de TLS),
- Et le protocole des enregistrements (record protocol), au plus bas niveau, chargé d'acheminer les données chiffrées.
Pour comprendre le rôle de ces deux protocoles, imaginons un protocole fictif simple, qui n'aurait qu'un seul algorithme de cryptographie symétrique, et qu'une seule clé, connue des deux parties (par exemple dans leur fichier de configuration). Avec un tel protocole, on pourrait se passer du protocole de salutation, et n'avoir qu'un protocole des enregistrements, indiquant comment encoder les données chiffrées. Le client et le serveur pourraient se mettre à communiquer immédiatement, sans salutation, poignée de mains et négociation, réduisant ainsi la latence. Un tel protocole serait très simple, donc sa sécurité serait bien plus facile à analyser, ce qui est une bonne chose. Mais il n'est pas du tout réaliste : changer la clé utilisée serait complexe (il faudrait synchroniser exactement les deux parties), remplacer l'algorithme si la cryptanalyse en venait à bout (comme c'est arrivé à RC4, cf. RFC 7465) créerait un nouveau protocole incompatible avec l'ancien, communiquer avec un serveur qu'on n'a jamais vu serait impossible (puisque on ne partagerait pas de clé commune), etc. D'où la nécessité du protocole de salutation, où les partenaires :
- S'authentifient avec leur clé publique (ou, si on veut faire comme dans le protocole fictif simple, avec une clé secrète partagée),
- Sélectionnent l'algorithme de cryptographie symétrique qui va chiffrer la session, ainsi que ses paramètres divers,
- Choisir la clé de la session TLS (et c'est là que se sont produites les plus grandes bagarres lors de la conception de TLS 1.3).
Notez que TLS n'est en général pas utilisé tel quel mais via un protocole de haut niveau, comme HTTPS pour sécuriser HTTP. TLS ne suppose pas un usage particulier : on peut s'en servir pour HTTP, pour SMTP (RFC 7672), pour le DNS (RFC 7858), etc. Cette intégration dans un protocole de plus haut niveau pose parfois elle-même des surprises en matière de sécurité, par exemple si l'application utilisatrice ne fait pas attention à la sécurité (Voir mon exposé à Devoxx, et ses transparents.)
TLS 1.3 est plutôt un nouveau protocole qu'une nouvelle version, et il n'est pas directement compatible avec son prédécesseur, TLS 1.2 (une application qui ne connait que 1.3 ne peut pas parler avec une application qui ne connait que 1.2.) En pratique, les bibliothèques qui mettent en œuvre TLS incluent en général les différentes versions, et un mécanisme de négociation de la version utilisée permet normalement de découvrir la version maximum que les deux parties acceptent (historiquement, plusieurs failles sont venues de ce point, avec des pare-feux stupidement configurés qui interféraient avec la négociation).
La section 1.3 de notre RFC liste les différences importantes entre TLS 1.2 (qui était normalisé dans le RFC 5246) et 1.3 :
- La liste des algorithmes de cryptographie symétrique acceptés a été violemment réduite. Beaucoup trop longue en TLS 1.2, offrant trop de choix, comprenant plusieurs algorithmes faibles, elle ouvrait la voie à des attaques par repli. Les « survivants » de ce nettoyage sont tous des algorithmes à chiffrement intègre.
- Un nouveau service apparait, 0-RTT (zero round-trip time, la possibilité d'établir une session TLS avec un seul paquet, en envoyant les données tout de suite), qui réduit la latence du début de l'échange. Attention, rien n'est gratuit en ce monde, et 0-RTT présente des nouveaux dangers, et ce nouveau service a été un des plus controversés lors de la mise au point de TLS 1.3, entrainant de nombreux débats à l'IETF.
- Désormais, la sécurité future est systématique, la compromission d'une clé secrète ne permet plus de déchiffrer les anciennes communications. Plus de clés publiques statiques, tout se fera par clés éphémères. C'était le point qui a suscité le plus de débats à l'IETF, car cela complique sérieusement la surveillance (ce qui est bien le but) et le débogage. L'ETSI, représentante du patronat, a même normalisé son propre TLS délibérement affaibli, eTLS.
- Plusieurs messages de négociation qui étaient auparavant
en clair sont désormais chiffrés. Par contre, l'indication du
nom du serveur (SNI, section 3 du RFC 6066) reste en clair et c'est l'une des principales
limites de TLS en ce qui concerne la protection de la vie
privée. Le problème est important, mais très difficile à
résoudre (voir par exemple la proposition ESNI,
https://datatracker.ietf.org/doc/draft-ietf-tls-esni/et son cahier des charges dans le RFC 8744.) - Les fonctions de dérivation de clé ont été refaites.
- La machine à états utilisée pour l'établissement de la connexion également (elle est détaillée dans l'annexe A du RFC).
- Les algorithmes asymétriques à courbes elliptiques font maintenant partie de la définition de base de TLS (cf. RFC 7748), et on voit arriver des nouveaux comme ed25519 (cf. RFC 8422).
- Par contre, DSA a été retiré.
- Le mécanisme de négociation du numéro de version (permettant à deux machines n'ayant pas le même jeu de versions TLS de se parler) a changé. L'ancien était très bien mais, mal implémenté, il a suscité beaucoup de problèmes d'interopérabilité. Le nouveau est censé mieux gérer les innombrables systèmes bogués qu'on trouve sur l'Internet (la bogue ne provenant pas tant de la bibliothèque TLS utilisée que des pare-feux mal programmés et mal configurés qui sont souvent mis devant). J'en profite pour vous recommander l'article « HTTPS : de SSL à TLS 1.3 », sur ce sujet de la négociation de version.
- La reprise d'une session TLS précédente fait l'objet désormais d'un seul mécanisme, qui est le même que celui pour l'usage de clés pré-partagées. La négociation TLS peut en effet être longue, en terme de latence, et ce mécanisme permet d'éviter de tout recommencer à chaque connexion. Deux machines qui se parlent régulièrement peuvent ainsi gagner du temps.
Un bon résumé de ce nouveau protocole est dans l'article de Mark Nottingham.
Ce RFC concerne TLS 1.3 mais il contient aussi quelques changements pour la version 1.2 (section 1.4 du RFC), comme un mécanisme pour limiter les attaques par repli portant sur le numéro de version, et des mécanismes de la 1.3 « portés » vers la 1.2 sous forme d'extensions TLS.
La section 2 du RFC est un survol général de TLS 1.3 (le RFC fait 147 pages, et peu de gens le liront intégralement). Au début d'une session TLS, les deux parties, avec le protocole de salutation, négocient les paramètres (version de TLS, algorithmes cryptographiques) et définissent les clés qui seront utilisées pour le chiffrement de la session. En simplifiant, il y a trois phases dans l'établissement d'une session TLS :
- Définition des clés de session, et des paramètres
cryptographiques, le client envoie un
ClientHello, le serveur répond avec unServerHello, - Définition des autres paramètres (par exemple
l'application utilisée au-dessus de TLS, ou bien la demande
CertificateRequestd'un certificat client), cette partie est chiffrée, contrairement à la précédente, - Authentification du serveur, avec le message
Certificate(qui ne contient pas forcément un certificat, cela peut être une clé brute - RFC 7250 ou une clé d'une session précédente - RFC 7924).
Un message Finished termine cette ouverture
de session.
(Si vous êtes fana de futurisme, notez que seule la première étape
pourrait être remplacée par la distribution quantique
de clés, les autres resteraient
indispensables. Contrairement à ce que promettent ses promoteurs,
la QKD ne dispense pas d'utiliser les protocoles existants.)
Comment les deux parties se mettent-elles d'accord sur les clés ? Trois méthodes :
- Diffie-Hellman sur courbes elliptiques qui sera sans doute la plus fréquente,
- Clé pré-partagée,
- Clé pré-partagée avec Diffie-Hellman,
- Et la méthode RSA, elle, disparait de la norme (mais RSA peut toujours être utilisé pour l'authentification, autrement, cela ferait beaucoup de certificats à jeter…)
Si vous connaissez la cryptographie, vous savez que les PSK, les clés partagées, sont difficiles à gérer, puisque devant être transmises de manière sûre avant l'établissement de la connexion. Mais, dans TLS, une autre possibilité existe : si une session a été ouverte sans PSK, en n'utilisant que de la cryptographie asymétrique, elle peut être enregistrée, et resservir, afin d'ouvrir les futures discussions plus rapidement. TLS 1.3 utilise le même mécanisme pour des « vraies » PSK, et pour celles issues de cette reprise de sessions précédentes (contrairement aux précédentes versions de TLS, qui utilisaient un mécanisme séparé, celui du RFC 5077, désormais abandonné).
Si on a une PSK (gérée manuellement, ou bien via la reprise de session), on peut même avoir un dialogue TLS dit « 0-RTT ». Le premier paquet du client peut contenir des données, qui seront acceptées et traitées par le serveur. Cela permet une importante diminution de la latence, dont il faut rappeler qu'elle est souvent le facteur limitant des performances. Par contre, comme rien n'est idéal dans cette vallée de larmes, cela se fait au détriment de la sécurité :
- Plus de confidentialité persistante, si la PSK est compromise plus tard, la session pourra être déchiffrée,
- Le rejeu devient possible, et l'application doit donc savoir gérer ce problème.
La section 8 du RFC et l'annexe E.5 détaillent ces limites, et les mesures qui peuvent être prises.
Le protocole TLS est décrit avec un langage spécifique, décrit de manière relativement informelle dans la section 3 du RFC. Ce langage manipule des types de données classiques :
- Scalaires
(
uint8,uint16), - Tableaux, de taille fixe -
Datum[3]ou variable, avec indication de la longueur au début -uint16 longer<0..800>, - Énumérations (
enum { red(3), blue(5), white(7) } Color;), - Enregistrements structurés, y compris avec variantes (la présence de certains champs dépendant de la valeur d'un champ).
Par exemple, tirés de la section 4 (l'annexe B fournit la liste complète), voici, dans ce langage, la liste des types de messages pendant les salutations, une énumération :
enum {
client_hello(1),
server_hello(2),
new_session_ticket(4),
end_of_early_data(5),
encrypted_extensions(8),
certificate(11),
certificate_request(13),
certificate_verify(15),
finished(20),
key_update(24),
message_hash(254),
(255)
} HandshakeType;
Et le format de base d'un message du protocole de salutation :
struct {
HandshakeType msg_type; /* handshake type */
uint24 length; /* bytes in message */
select (Handshake.msg_type) {
case client_hello: ClientHello;
case server_hello: ServerHello;
case end_of_early_data: EndOfEarlyData;
case encrypted_extensions: EncryptedExtensions;
case certificate_request: CertificateRequest;
case certificate: Certificate;
case certificate_verify: CertificateVerify;
case finished: Finished;
case new_session_ticket: NewSessionTicket;
case key_update: KeyUpdate;
};
} Handshake;
La section 4 fournit tous les détails sur le protocole de
salutation, notamment sur la délicate négociation des paramètres
cryptographiques. Notez que la renégociation en cours de session a
disparu, donc un ClientHello ne peut
désormais plus être envoyé qu'au début.
Un problème auquel a toujours dû faire face TLS est celui de la
négociation de version, en présence de mises en œuvre boguées, et,
surtout, en présence de boitiers
intermédiaires encore plus bogués
(pare-feux ignorants, par exemple, que des
DSI ignorantes placent un peu partout). Le
modèle original de TLS pour un client était d'annoncer dans le
ClientHello le plus grand numéro de version
qu'on gère, et de voir dans ServerHello le
maximum imposé par le serveur. Ainsi, un client TLS 1.2 parlant à
un serveur qui ne gère que 1.1 envoyait
ClientHello(client_version=1.2) et, en
recevant ServerHello(server_version=1.1), se
repliait sur TLS 1.1, la version la plus élevée que les deux
parties gèraient. En pratique, cela ne marche pas aussi bien. On
voyait par exemple des serveurs (ou, plus vraisemblablement, des
pare-feux bogués) qui raccrochaient brutalement en
présence d'un numéro de version plus élevé, au lieu de suggérer un
repli. Le client n'avait alors que le choix de renoncer, ou bien
de se lancer dans une série d'essais/erreurs (qui peut être
longue, si le serveur ou le pare-feu bogué ne répond pas).
TLS 1.3 change donc complètement le mécanisme de
négociation. Le client annonce toujours la version 1.2 (en fait
0x303, pour des raisons historiques), et la vraie version est mise
dans une extension, supported_versions
(section 4.2.1), dont
on espère qu'elle sera ignorée par les serveurs mal
gérés. (L'annexe D du RFC détaille ce problème de la négociation
de version.) Dans la réponse ServerHello, un
serveur 1.3 doit inclure cette extension, autrement, il faut se
rabattre sur TLS 1.2.
En parlant d'extensions, concept qui avait été introduit
originellement dans le RFC 4366, notre RFC
reprend des extensions déjà normalisées, comme le SNI
(Server Name Indication) du RFC 6066, le battement de cœur du RFC 6520, le remplissage du ClientHello
du RFC 7685,
et en ajoute dix, dont
supported_versions. Certaines de ces
extensions doivent être présentes dans les messages
Hello, car la sélection des paramètres
cryptographiques en dépend, d'autres peuvent être uniquement dans
les messages EncryptedExtensions, une
nouveauté de TLS 1.3, pour les extensions qu'on n'enverra qu'une
fois le chiffrement commencé. Le RFC en profite pour rappeler que
les messages Hello ne sont pas protégés
cryptographiquement, et peuvent donc être modifiés (le message
Finished résume les décisions prises et peut
donc protéger contre ce genre d'attaques).
Autrement, parmi les autres nouvelles extensions :
- Le petit gâteau (cookie), pour tester la joignabilité,
- Les données précoces (early data), extension qui permet d'envoyer des données dès le premier message (« O-RTT »), réduisant ainsi la latence, un peu comme le fait le TCP Fast Open du RFC 7413,
- Liste des AC (certificate authorities), qui, en indiquant la liste des AC connues du client, peut aider le serveur à choisir un certificat qui sera validé (par exemple en n'envoyant le certificat CAcert que si le client connait cette AC).
La section 5 décrit le protocole des enregistrements (record protocol). C'est ce sous-protocole qui va prendre un flux d'octets, le découper en enregistrements, les protéger par le chiffrement puis, à l'autre bout, déchiffrer et reconstituer le flux… Notez que « protégé » signifie à la fois confidentialité et intégrité puisque TLS 1.3, contrairement à ses prédécesseurs, impose AEAD (RFC 5116).
Les enregistrements sont typés et marqués handshake (la salutation, vue dans la section précédente), change cipher spec, alert (pour signaler un problème) et application data (les données elle-mêmes) :
enum {
invalid(0),
change_cipher_spec(20),
alert(21),
handshake(22),
application_data(23),
(255)
} ContentType;
Le contenu des données est évidemment incompréhensible, en raison du chiffrement (voici un enregistrement de type 23, données, vu par tshark) :
TLSv1.3 Record Layer: Application Data Protocol: http-over-tls
Opaque Type: Application Data (23)
Version: TLS 1.2 (0x0303)
Length: 6316
Encrypted Application Data: eb0e21f124f82eee0b7a37a1d6d866b075d0476e6f00cae7...
Et décrite par la norme dans son langage formel :
struct {
ContentType opaque_type = application_data; /* 23 */
ProtocolVersion legacy_record_version = 0x0303; /* TLS v1.2 */
uint16 length;
opaque encrypted_record[TLSCiphertext.length];
} TLSCiphertext;
(Oui, le numéro de version reste à TLS 1.2 pour éviter d'énerver les stupides middleboxes.) Notez que des extensions à TLS peuvent introduire d'autres types d'enregistrements.
Une faiblesse classique de TLS est que la taille des données chiffrées n'est pas dissimulée. Si on veut savoir à quelle page d'un site Web un client HTTP a accédé, on peut parfois le déduire de l'observation de cette taille. D'où la possibilité de faire du remplissage pour dissimuler cette taille (section 5.4 du RFC). Notez que le RFC ne suggère pas de politique de remplissage spécifique (ajouter un nombre aléatoire ? Tout remplir jusqu'à la taille maximale ?), c'est un choix compliqué. Il note aussi que certaines applications font leur propre remplissage, et qu'il n'est alors pas nécessaire que TLS le fasse.
La section 6 du RFC est dédiée au cas des alertes. C'est un des types d'enregistrements possibles, et, comme les autres, il est chiffré, et les alertes sont donc confidentielles. Une alerte a un niveau et une description :
struct {
AlertLevel level;
AlertDescription description;
} Alert;
Le niveau indiquait si l'alerte est fatale mais n'est plus utilisé en TLS 1.2, où il faut se fier uniquement à la description, une énumération des problèmes possibles (message de type inconnu, mauvais certificat, enregistrement non décodable - rappelez-vous que TLS 1.3 n'utilise que du chiffrement intègre, problème interne au client ou au serveur, extension non acceptée, etc). La section 6.2 donne une liste des erreurs fatales, qui doivent mener à terminer immédiatement la session TLS.
La section 8 du RFC est entièrement consacrée à une nouveauté délicate, le « 0-RTT ». Ce terme désigne la possibilité d'envoyer des données dès le premier paquet, sans les nombreux échanges de paquets qui sont normalement nécessaires pour établir une session TLS. C'est très bien du point de vue des performances, mais pas forcément du point de vue de la sécurité puisque, sans échanges, on ne peut plus vérifier à qui on parle. Un attaquant peut réaliser une attaque par rejeu en envoyant à nouveau un paquet qu'il a intercepté. Un serveur doit donc se défendre en se souvenant des données déjà envoyées et en ne les acceptant pas deux fois. (Ce qui peut être plus facile à dire qu'à faire ; le RFC contient une bonne discussion très détaillée des techniques possibles, et de leurs limites. Il y en a des subtiles, comme d'utiliser des systèmes de mémorisation ayant des faux positifs, comme les filtres de Bloom, parce qu'ils ne produiraient pas d'erreurs, ils rejetteraient juste certains essais 0-RTT légitimes, cela ne serait donc qu'une légère perte de performance.)
La section 9 de notre RFC se penche sur un problème difficile,
la conformité des mises en œuvres de TLS. D'abord, les algorithmes
obligatoires. Afin de permettre l'interopérabilité,
toute mise en œuvre de TLS doit avoir la
suite de chiffrement TLS_AES_128_GCM_SHA256
(AES en
mode GCM
avec SHA-256). D'autres suites sont
recommandées (cf. annexe B.4). Pour l'authentification,
RSA avec SHA-256 et
ECDSA sont obligatoires. Ainsi, deux
programmes différents sont sûrs de pouvoir trouver des algorithmes
communs. La possibilité
d'authentification par certificats PGP du RFC 6091 a été retirée.
De plus, certaines extensions à TLS sont obligatoires, un pair TLS 1.3 ne peut pas les refuser :
supported_versions, nécessaire pour annoncer TLS 1.3,cookie,signature_algorithms,signature_algorithms_cert,supported_groupsetkey_share,server_name, c'est à dire SNI (Server Name Indication), souvent nécessaire pour pouvoir choisir le bon certificat (cf. section 3 du RFC 6066).
La section 9 précise aussi le comportement attendu des équipements intermédiaires. Ces dispositifs (pare-feux, par exemple, mais pas uniquement) ont toujours été une plaie pour TLS. Alors que TLS vise à fournir une communication sûre, à l'abri des équipements intermédiaires, ceux-ci passent leur temps à essayer de s'insérer dans la communication, et souvent la cassent. Normalement, TLS 1.3 est conçu pour que ces interférences ne puissent pas mener à un repli (le repli est l'utilisation de paramètres moins sûrs que ce que les deux machines auraient choisi en l'absence d'interférence).
Il y a deux grandes catégories d'intermédiaires, ceux qui tripotent la session TLS sans être le client ou le serveur, et ceux qui terminent la session TLS de leur côté. Attention, dans ce contexte, « terminer » ne veut pas dire « y mettre fin », mais « la sécurité TLS se termine ici, de manière à ce que l'intermédiaire puisse accéder au contenu de la communication ». Typiquement, une middlebox qui « termine » une session TLS va être serveur TLS pour le client et client TLS pour le serveur, s'insérant complètement dans la conversation. Normalement, l'authentification vise à empêcher ce genre de pratiques, et l'intermédiaire ne sera donc accepté que s'il a un certificat valable. C'est pour cela qu'en entreprise, les machines officielles sont souvent installées avec une AC contrôlée par le vendeur du boitier intermédiaire, de manière à permettre l'interception.
Le RFC ne se penche pas sur la légitimité de ces pratiques, uniquement sur leurs caractéristiques techniques. (Les boitiers intermédiaires sont souvent programmés avec les pieds, et ouvrent de nombreuses failles.) Le RFC rappelle notamment que l'intermédiaire qui termine une session doit suivre le RFC à la lettre (ce qui devrait aller sans dire…)
Depuis le RFC 4346, il existe plusieurs registres IANA pour TLS, décrits en section 11, avec leurs nouveautés. En effet, plusieurs choix pour TLS ne sont pas « câblés en dur » dans le RFC mais peuvent évoluer indépendamment. Par exemple, le registre de suites cryptographiques a une politique d'enregistrement « spécification nécessaire » (cf. RFC 8126, sur les politiques d'enregistrement). La cryptographie fait régulièrement des progrès, et il faut donc pouvoir modifier la liste des suites acceptées (par exemple lorsqu'il faudra y ajouter les algorithmes post-quantiques) sans avoir à toucher au RFC (l'annexe B.4 donne la liste actuelle). Le registre des types de contenu, lui, a une politique d'enregistrement bien plus stricte, « action de normalisation ». On crée moins souvent des types que des suites cryptographiques. Même chose pour le registre des alertes ou pour celui des salutations.
L'annexe C du RFC plaira aux programmeurs, elle donne plusieurs conseils pour une mise en œuvre correcte de TLS 1.3 (ce n'est pas tout d'avoir un protocole correct, il faut encore qu'il soit programmé correctement). Pour aider les développeurs à déterminer s'ils ont correctement fait le travail, un futur RFC fournira des vecteurs de test.
Un des conseils les plus importants est évidemment de faire
attention au générateur de nombres
aléatoires, source de tant de failles de sécurité en
cryptographie. TLS utilise des nombres qui doivent être
imprévisibles à un attaquant pour générer des clés de session. Si
ces nombres sont prévisibles, toute la cryptographie s'effondre. Le RFC conseille fortement d'utiliser un générateur
existant (comme /dev/urandom sur les systèmes
Unix) plutôt que d'écrire le sien, ce qui
est bien plus difficile qu'il ne semble. (Si on tient quand même à
le faire, le RFC 4086 est une lecture
indispensable.)
Le RFC conseille également de vérifier le certificat du partenaire par défaut (quitte à fournir un moyen de débrayer cette vérification). Si ce n'est pas le cas, beaucoup d'utilisateurs du programme ou de la bibliothèque oublieront de le faire. Il suggère aussi de ne pas accepter certains certificats trop faibles (clé RSA de seulement 1 024 bits, par exemple).
Il existe plusieurs moyens avec TLS de ne pas avoir d'authentification du serveur : les clés brutes du RFC 7250 (à la place des certificats), ou bien les certificats auto-signés. Dans ces conditions, une attaque de l'homme du milieu est parfaitement possibe, et il faut donc prendre des précautions supplémentaires (par exemple DANE, normalisé dans le RFC 6698, que le RFC oublie malheureusement de citer).
Autre bon conseil de cryptographie, se méfier des attaques fondées sur la mesure du temps de calcul, et prendre des mesures appropriées (par exemple en vérifiant que le temps de calcul est le même pour des données correctes et incorrectes).
Il n'y a aucune bonne raison d'utiliser certains algorithmes faibles (comme RC4, abandonné depuis le RFC 7465), et le RFC demande que le code pour ces algorithmes ne soit pas présent, afin d'éviter une attaque par repli (annexes C.3 et D.5 du RFC). De la même façon, il demande de ne jamais accepter SSL v3 (RFC 7568).
L'expérience a prouvé que beaucoup de mises en œuvre de TLS ne réagissaient pas correctement à des options inattendues, et le RFC rappelle donc qu'il faut ignorer les suites cryptographiques inconnues (autrement, on ne pourrait jamais introduire une nouvelle suite, puisqu'elle casserait les programmes), et ignorer les extensions inconnues (pour la même raison).
L'annexe D, elle, est consacrée au problème de la communication
avec un vieux partenaire, qui ne connait pas TLS 1.3. Le mécanisme
de négociation de la version du protocole à utiliser a
complètement changé en 1.3. Dans la 1.3, le champ
version du ClientHello
contient 1.2, la vraie version étant dans l'extension
supported_versions. Si un client 1.3 parle
avec un serveur <= 1.2, le serveur ne connaitra pas cette
extension et répondra sans l'extension, avertissant ainsi le
client qu'il faudra parler en 1.2 (ou plus vieux). Ça, c'est si le
serveur est correct. S'il ne l'est pas ou, plus vraisemblablement,
s'il est derrière une
middlebox boguée, on
verra des problèmes comme par exemple le refus de répondre aux
clients utilisant des extensions inconnues (ce qui sera le cas
pour supported_versions), soit en rejettant
ouvertement la demande soit, encore pire, en l'ignorant. Arriver à gérer des
serveurs/middleboxes incorrects est un problème
complexe. Le client peut être tenté de re-essayer avec d'autres
options (par exemple tenter du 1.2, sans l'extension
supported_versions). Cette méthode n'est pas
conseillée. Non seulement elle peut prendre du temps (attendre
l'expiration du délai de garde, re-essayer…) mais surtout, elle
ouvre la voie à des attaques par repli :
l'attaquant bloque les ClientHello 1.3 et le
client, croyant bien faire, se replie sur une version plus
ancienne et sans doute moins sûre de TLS.
En parlant de compatibilité, le « 0-RTT » n'est évidemment pas
compatible avec les vieilles versions. Le client qui envoie du
« 0-RTT » (des données dans le ClientHello)
doit donc savoir que, si la réponse est d'un serveur <= 1.2,
la session ne pourra pas être établie, et il faudra donc réessayer
sans 0-RTT.
Naturellement, les plus gros problèmes ne surviennent pas avec
les clients et les serveurs mais avec les
middleboxes. Plusieurs études ont montré leur
caractère néfaste (cf. présentation
à l'IETF 100, mesures
avec Chrome (qui indique également que certains serveurs
TLS sont gravement en tort, comme celui installé dans les
imprimantes Canon), mesures
avec Firefox, et encore
d'autres mesures). Le RFC suggère qu'on limite les risques
en essayant d'imiter le plus possible une salutation de TLS 1.2,
par exemple en envoyant des messages
change_cipher_spec, qui ne sont plus utilisés
en TLS 1.3, mais qui peuvent rassurer la
middlebox (annexe D.4).
Enfin, le RFC se termine par l'annexe E, qui énumère les propriétés de sécurité de TLS 1.3 : même face à un attaquant actif (RFC 3552), le protocole de salutation de TLS garantit des clés de session communes et secrètes, une authentification du serveur (et du client si on veut), et une sécurité persistante, même en cas de compromission ultérieure des clés (sauf en cas de 0-RTT, un autre des inconvénients sérieux de ce service, avec le risque de rejeu). De nombreuses analyses détaillées de la sécurité de TLS sont listées dans l'annexe E.1.6. À lire si vous voulez travailler ce sujet.
Quant au protocole des enregistrements, celui de TLS 1.3 garantit confidentialité et intégrité (RFC 5116).
TLS 1.3 a fait l'objet de nombreuses analyses de sécurité par des chercheurs, avant même sa normalisation, ce qui est une bonne chose (et qui explique en partie les retards). Notre annexe E pointe également les limites restantes de TLS :
- Il est vulnérable à l'analyse de trafic. TLS n'essaie pas de cacher la taille des paquets, ni l'intervalle de temps entre eux. Ainsi, si un client accède en HTTPS à un site Web servant quelques dizaines de pages aux tailles bien différentes, il est facile de savoir quelle page a été demandée, juste en observant les tailles. (Voir « I Know Why You Went to the Clinic: Risks and Realization of HTTPS Traffic Analysis », de Miller, B., Huang, L., Joseph, A., et J. Tygar et « HTTPS traffic analysis and client identification using passive SSL/TLS fingerprinting », de Husak, M., Čermak, M., Jirsik, T., et P. Čeleda). TLS fournit un mécanisme de remplissage avec des données bidon, permettant aux applications de brouiller les pistes. Certaines applications utilisant TLS ont également leur propre remplissage (par exemple, pour le DNS, c'est le RFC 7858). De même, une mise en œuvre de TLS peut retarder les paquets pour rendre l'analyse des intervalles plus difficile. On voit que dans les deux cas, taille des paquets et intervalle entre eux, résoudre le problème fait perdre en performance (c'est pour cela que ce n'est pas intégré par défaut).
- TLS peut être également vulnérable à des attaques par canal auxiliaire. Par exemple, la durée des opérations cryptographiques peut être observée, ce qui peut donner des informations sur les clés. TLS fournit quand même quelques défenses : l'AEAD facilite la mise en œuvre de calculs en temps constant, et format uniforme pour toutes les erreurs, empêchant un attaquant de trouver quelle erreur a été déclenchée.
Le 0-RTT introduit un nouveau risque, celui de rejeu. (Et 0-RTT a sérieusement contribué aux délais qu'à connu le projet TLS 1.3, plusieurs participants à l'IETF protestant contre cette introduction risquée.) Si l'application est idempotente, ce n'est pas très grave. Si, par contre, les effets d'une requête précédentes peuvent être rejoués, c'est plus embêtant (imaginez un transfert d'argent répété…) TLS ne promet rien en ce domaine, c'est à chaque serveur de se défendre contre le rejeu (la section 8 donne des idées à ce sujet). Voilà pourquoi le RFC demande que les requêtes 0-RTT ne soient pas activées par défaut, mais uniquement quand l'application au-dessus de TLS le demande. (Cloudflare, par exemple, n'active pas le 0-RTT par défaut.)
Voilà, vous avez maintenant fait un tour complet du RFC, mais vous savez que la cryptographie est une chose difficile, et pas seulement dans les algorithmes cryptographiques (TLS n'en invente aucun, il réutilise des algorithmes existants comme AES ou ECDSA), mais aussi dans les protocoles cryptographiques, un art complexe. N'hésitez donc pas à lire le RFC en détail, et à vous méfier des résumés forcément toujours sommaires, comme cet article.
À part le 0-RTT, le plus gros débat lors de la création de TLS
1.3 avait été autour du concept que ses partisans nomment
« visibilité » et ses adversaires « surveillance ». C'est l'idée
qu'il serait bien pratique si on (on : le patron, la police, le
FAI…) pouvait accéder au contenu des
communications TLS. « Le chiffrement, c'est bien, à condition que
je puisse lire les données quand même » est l'avis des partisans
de la visibilité. Cela avait été proposé dans les
Internet-Drafts draft-green-tls-static-dh-in-tls13
et draft-rhrd-tls-tls13-visibility. Je
ne vais pas ici pouvoir capturer la totalité
du débat, juste noter quelques points qui sont parfois oubliés
dans la discussion. Côté partisans de la visibilité :
- Dans une entreprise capitaliste, il n'y pas de citoyens, juste un patron et des employés. Les ordinateurs appartiennent au patron, et les employés n'ont pas leur mot à dire. Le patron peut donc décider d'accéder au contenu des communications chiffrées.
- Il existe des règles (par exemple PCI-DSS dans le secteur financier ou HIPAA dans celui de la santé) qui requièrent de certaines entreprises qu'elles sachent en détail tout ce qui circule sur le réseau. Le moyen le plus simple de le faire est de surveiller le contenu des communications, même chiffrées. (Je ne dis pas que ces règles sont intelligentes, juste qu'elles existent. Notons par exemple que les mêmes règles imposent d'utiliser du chiffrement fort, sans faille connue, ce qui est contradictoire.)
- Enregistrer le trafic depuis les terminaux est compliqué en pratique : applications qui n'ont pas de mécanisme de journalisation du trafic, systèmes d'exploitation fermés, boîtes noires…
- TLS 1.3 risque de ne pas être déployé dans les entreprises qui tiennent à surveiller le trafic, et pourrait même être interdit dans certains pays, où la surveillance passe avant les droits humains.
Et du côté des adversaires de la surveillance :
- La cryptographie, c'est compliqué et risqué. TLS 1.3 est déjà assez compliqué comme cela. Lui ajouter des fonctions (surtout des fonctions délibérement conçues pour affaiblir ses propriétés de sécurité) risque fort d'ajouter des failles de sécurité. D'autant plus que TLS 1.3 a fait l'objet de nombreuses analyses de sécurité avant son déploiement, et qu'il faudrait tout recommencer.
- Contrairement à ce que semblent croire les partisans de la « visibilité », il n'y a pas que HTTPS qui utilise TLS. Ils ne décrivent jamais comment leur proposition marcherait avec des protocoles autres que HTTPS.
- Pour HTTPS, et pour certains autres protocoles, une solution simple, si on tient absolument à intercepter tout le trafic, est d'avoir un relais explicite, configuré dans les applications, et combiné avec un blocage dans le pare-feu des connexions TLS directes. Les partisans de la visibilté ne sont en général pas enthousiastes pour cette solution car ils voudraient faire de la surveillance furtive, sans qu'elle se voit dans les applications utilisées par les employés ou les citoyens.
- Les partisans de la « visibilité » disent en général que l'interception TLS serait uniquement à l'intérieur de l'entreprise, pas pour l'Internet public. Mais, dans ce cas, tous les terminaux sont propriété de l'entreprise et contrôlés par elle, donc elle peut les configurer pour copier tous les messages échangés. Et, si certains de ces terminaux sont des boîtes noires, non configurables et dont on ne sait pas bien ce qu'ils font, eh bien, dans ce cas, on se demande pourquoi des gens qui insistent sur leurs obligations de surveillance mettent sur leur réseau des machines aussi incontrôlables.
- Dans ce dernier cas (surveillance uniquement au sein d'une entreprise), le problème est interne à l'entreprise, et ce n'est donc pas à l'IETF, organisme qui fait des normes pour l'Internet, de le résoudre. Après tout, rien n'empêche ces entreprises de garder TLS 1.2.
Revenons maintenant aux choses sérieuses, avec les mises en
œuvre de TLS 1.3. Il y en existe au moins une dizaine à l'heure
actuelle mais, en général, pas dans les versions officiellement
publiées des logiciels. Notons quand même que
Firefox 61 sait faire du TLS 1.3. Les autres
mises en œuvre sont prêtes, même si pas forcément publiées. Prenons
l'exemple de la bibliothèque
GnuTLS. Elle dispose de TLS 1.3 depuis la
version 3.6.3. Pour l'instant, il faut compiler cette version avec
l'option ./configure --enable-tls13-support,
qui n'est pas encore activée par défaut. Un bon
article du mainteneur de GnuTLS explique bien les nouveautés
de TLS 1.3.
Une fois GnuTLS correctement compilé, on peut utiliser le
programme en ligne de commande gnutls-cli avec
un serveur qui accepte TLS 1.3 :
% gnutls-cli gmail.com ... - Description: (TLS1.3)-(ECDHE-X25519)-(RSA-PSS-RSAE-SHA256)-(AES-256-GCM) - Ephemeral EC Diffie-Hellman parameters - Using curve: X25519 - Curve size: 256 bits - Version: TLS1.3 - Key Exchange: ECDHE-RSA - Server Signature: RSA-PSS-RSAE-SHA256 - Cipher: AES-256-GCM - MAC: AEAD ...
Et ça marche, on fait du TLS 1.3. Si vous préférez écrire le programme
vous-même, regardez ce petit
programme. Si
GnuTLS est en /local, il se compilera avec
cc -I/local/include -Wall -Wextra -o test-tls13 test-tls13.c
-L/local/lib -lgnutls et s'utilisera avec :
% ./test-tls13 www.ietf.org TLS connection using "TLS1.3 AES-256-GCM" % ./test-tls13 gmail.com TLS connection using "TLS1.3 AES-256-GCM" % ./test-tls13 mastodon.gougere.fr TLS connection using "TLS1.2 AES-256-GCM" % ./test-tls13 www.bortzmeyer.org TLS connection using "TLS1.2 AES-256-GCM" % ./test-tls13 blog.cloudflare.com TLS connection using "TLS1.3 AES-256-GCM"
Cela vous donne une petite idée des serveurs qui acceptent TLS 1.3.
Un pcap d'une session TLS 1.3 est disponible
en tls13.pcap. Notez que le numéro de version n'est pas encore
celui du RFC (0x304). Ici, 0x7f1c désigne
l'Internet-Draft numéro 28. Voici la session
vue par tshark :
1 0.000000 2001:67c:370:1998:9819:4f92:d0c0:e94d → 2400:cb00:2048:1::6814:55 TCP 94 36866 → https(443) [SYN] Seq=0 Win=28800 Len=0 MSS=1440 SACK_PERM=1 TSval=3528788861 TSecr=0 WS=128
2 0.003052 2400:cb00:2048:1::6814:55 → 2001:67c:370:1998:9819:4f92:d0c0:e94d TCP 86 https(443) → 36866 [SYN, ACK] Seq=0 Ack=1 Win=24400 Len=0 MSS=1220 SACK_PERM=1 WS=1024
3 0.003070 2001:67c:370:1998:9819:4f92:d0c0:e94d → 2400:cb00:2048:1::6814:55 TCP 74 36866 → https(443) [ACK] Seq=1 Ack=1 Win=28800 Len=0
4 0.003354 2001:67c:370:1998:9819:4f92:d0c0:e94d → 2400:cb00:2048:1::6814:55 TLSv1 403 Client Hello
5 0.006777 2400:cb00:2048:1::6814:55 → 2001:67c:370:1998:9819:4f92:d0c0:e94d TCP 74 https(443) → 36866 [ACK] Seq=1 Ack=330 Win=25600 Len=0
6 0.011393 2400:cb00:2048:1::6814:55 → 2001:67c:370:1998:9819:4f92:d0c0:e94d TLSv1.3 6496 Server Hello, Change Cipher Spec, Application Data
7 0.011413 2001:67c:370:1998:9819:4f92:d0c0:e94d → 2400:cb00:2048:1::6814:55 TCP 74 36866 → https(443) [ACK] Seq=330 Ack=6423 Win=41728 Len=0
8 0.011650 2001:67c:370:1998:9819:4f92:d0c0:e94d → 2400:cb00:2048:1::6814:55 TLSv1.3 80 Change Cipher Spec
9 0.012685 2001:67c:370:1998:9819:4f92:d0c0:e94d → 2400:cb00:2048:1::6814:55 TLSv1.3 148 Application Data
10 0.015693 2400:cb00:2048:1::6814:55 → 2001:67c:370:1998:9819:4f92:d0c0:e94d TCP 74 https(443) → 36866 [ACK] Seq=6423 Ack=411 Win=25600 Len=0
11 0.015742 2400:cb00:2048:1::6814:55 → 2001:67c:370:1998:9819:4f92:d0c0:e94d TLSv1.3 524 Application Data
12 0.015770 2001:67c:370:1998:9819:4f92:d0c0:e94d → 2400:cb00:2048:1::6814:55 TCP 74 36866 → https(443) [RST] Seq=411 Win=0 Len=0
13 0.015788 2400:cb00:2048:1::6814:55 → 2001:67c:370:1998:9819:4f92:d0c0:e94d TCP 74 https(443) → 36866 [FIN, ACK] Seq=6873 Ack=411 Win=25600 Len=0
14 0.015793 2001:67c:370:1998:9819:4f92:d0c0:e94d → 2400:cb00:2048:1::6814:55 TCP 74 36866 → https(443) [RST] Seq=411 Win=0 Len=0
Et, complètement décodée par tshark :
Secure Sockets Layer [sic]
TLSv1 Record Layer: Handshake Protocol: Client Hello
Content Type: Handshake (22)
Version: TLS 1.0 (0x0301)
Handshake Protocol: Client Hello
Handshake Type: Client Hello (1)
Version: TLS 1.2 (0x0303)
...
Extension: supported_versions (len=9)
Type: supported_versions (43)
Length: 9
Supported Versions length: 8
Supported Version: Unknown (0x7f1c)
Supported Version: TLS 1.2 (0x0303)
Supported Version: TLS 1.1 (0x0302)
Supported Version: TLS 1.0 (0x0301)
Le texte complet est en tls13.txt. Notez bien que la négociation est
en clair. D'autres exemples de traces TLS 1.3 figurent dans le RFC 8448.
Quelques autres articles à lire :
- L'annonce officielle de l'IETF,
- Le bon résumé de Cloudflare sur la version 1.3,
- Discussion Ycombinator sur la visibilité,
- Liste complète des réponses aux partisans de la visbilité,
- Bon article historique très détaillé sur l'histoire de TLS, jusqu'à la version 1.3,
- Un exemple d'un des ateliers où a été étudié la sécurité de TLS 1.3, à Paris en 2017, et un autre à San Diego en 2016,
- Bon article sur la question des middleboxes, expliquant notamment les extensions « inutiles », mais permettant de tromper ces middleboxes pour ressembler à TLS 1.2.
L'article seul
RFC 8422: Elliptic Curve Cryptography (ECC) Cipher Suites for Transport Layer Security (TLS) Versions 1.2 and Earlier
Date de publication du RFC : Août 2018
Auteur(s) du RFC : Y. Nir (Check Point), S. Josefsson
(SJD AB), M. Pegourie-Gonnard (Independent /
PolarSSL)
Chemin des normes
Réalisé dans le cadre du groupe de travail IETF tls
Première rédaction de cet article le 7 août 2018
Ce RFC décrit les algorithmes cryptographiques à base de courbes elliptiques utilisés dans TLS. Il remplace le RFC 4492.
Plus exactement, il normalise les algorithmes utilisés dans les versions de TLS allant jusqu'à 1.2 incluse. L'utilisation des courbes elliptiques par TLS 1.3 est décrite dans le RFC sur TLS 1.3, le RFC 8446. Les deux points importants de ce nouveau RFC sont :
- L'utilisation de courbes elliptiques pour un échange Diffie-Hellman de la clé de session TLS (ce qu'on nomme ECDHE),
- Les algorithmes de signature à courbes elliptiques ECDSA et EdDSA pour authentifier le pair TLS.
Commençons par l'échange de clés de session (section 2). TLS nécessite que les deux pairs se mettent d'accord sur une clé de chiffrement symétrique qui sera ensuite utilisée pendant toute la session, avec des algorithmes comme AES. Une des façons de synchroniser cette clé de session est qu'un des pairs la génère aléatoirement, puis la chiffre avec la clé publique (chiffrement asymétrique) de son pair avant de lui transmettre (cela marche avec RSA mais je n'ai pas l'impression qu'il y ait un moyen normalisé de faire cela avec les courbes elliptiques). Une autre façon est d'utiliser un échange Diffie-Hellman. Contrairement à l'échange Diffie-Hellman originel, celui présenté dans ce RFC, ECDHE, utilise la cryptographie sur courbes elliptiques. (J'ai simplifié pas mal : par exemple, l'échange ECDHE ne donnera pas directement la clé de session, celle-ci sera en fait dérivée de la clé obtenue en ECDHE.) Le principal avantage de Diffie-Hellman est de fournir de la sécurité même en cas de compromission ultérieure de la clé privée.
Notre RFC présente trois variantes d'ECDHE, selon la manière dont l'échange est authentifié, l'une utilisant ECDSA ou EdDSA, l'autre utilisant le traditionnel RSA, et la troisième n'authentifiant pas du tout, et étant donc vulnérable aux attaques de l'Homme du Milieu, sauf si une authentification a lieu en dehors de TLS. (Attention, dans le cas de ECDHE_RSA, RSA n'est utilisé que pour authentifier l'échange, la génération de la clé se fait bien en utilisant les courbes elliptiques.)
Lorsque l'échange est authentifié (ECDHE_ECDSA
- qui, en dépit de son nom, inclut EdDSA -
ou bien ECDHE_RSA), les paramètres
ECDH (Diffie-Hellman avec courbes elliptiques)
sont signés par la
clé privée (ECDSA, EdDSA ou RSA). S'il n'est pas authentifié
(ECDH_anon, mais notez que le nom est trompeur,
bien que le E final - ephemeral - manque, la clé
est éphémère), on n'envoie évidemment pas de certificat, ou de demande
de certificat.
Voilà, avec cette section 2, on a pu générer une clé de session
avec Diffie-Hellman, tout en authentifiant le serveur avec des courbes
elliptiques. Et pour l'authentification du client ? C'est la section 3
de notre RFC. Elle décrit un mécanisme ECDSA_sign
(là encore, en dépit du nom du mécanisme, il fonctionne aussi bien
pour EdDSA), où le client s'authentifie en signant ses messages avec
un algorithme à courbes elliptiques.
Les courbes elliptiques ont quelques particularités qui justifient
deux extensions à TLS que présente la section 4 du RFC. Il y a
Supported Elliptic Curves Extension et Supported Point
Formats Extension, qui permettent de décrire les
caractéristiques de la courbe elliptique utilisée (on verra plus loin
que la deuxième extension ne sert plus guère). Voici, vue par
tshark, l'utilisation de ces extensions dans un
ClientHello TLS envoyé par OpenSSL :
Extension: elliptic_curves
Type: elliptic_curves (0x000a)
Length: 28
Elliptic Curves Length: 26
Elliptic curves (13 curves)
Elliptic curve: secp256r1 (0x0017)
Elliptic curve: secp521r1 (0x0019)
Elliptic curve: brainpoolP512r1 (0x001c)
Elliptic curve: brainpoolP384r1 (0x001b)
Elliptic curve: secp384r1 (0x0018)
Elliptic curve: brainpoolP256r1 (0x001a)
Elliptic curve: secp256k1 (0x0016)
...
Extension: ec_point_formats
Type: ec_point_formats (0x000b)
Length: 4
EC point formats Length: 3
Elliptic curves point formats (3)
EC point format: uncompressed (0)
EC point format: ansiX962_compressed_prime (1)
EC point format: ansiX962_compressed_char2 (2)
La section 5 du RFC donne les détails concrets. Par exemple, les deux extensions citées plus haut s'écrivent, dans le langage de TLS (cf. section 4 du RFC 5246) :
enum {
elliptic_curves(10),
ec_point_formats(11)
} ExtensionType;
La première extension permet d'indiquer les courbes utilisées. Avec celles du RFC 7748, cela donne, comme possibilités :
enum {
deprecated(1..22),
secp256r1 (23), secp384r1 (24), secp521r1 (25),
x25519(29), x448(30),
reserved (0xFE00..0xFEFF),
deprecated(0xFF01..0xFF02),
(0xFFFF)
} NamedCurve;
secp256r1 est la courbe P-256 du
NIST, x25519 est la
Curve-25519 de Bernstein. Notez que beaucoup
des courbes de l'ancien RFC 4492, jamais très utilisées, ont
été abandonnées. (Les courbes se trouvent dans un
registre IANA.)
Normalement, dans TLS, on peut choisir séparément l'algorithme de
signature et celui de condensation (cf. section
7.4.1.4.1 du RFC 5246). Avec certains
algorithmes comme EdDSA dans sa forme « pure », il n'y a pas de
condensation séparée et un « algorithme » bidon,
Intrinsic (valeur 8) a été créé pour mettre
dans le champ « algorithme de condensation » de l'extension signature_algorithms.
Voici une négociation TLS complète, vue par curl :
% curl -v https://www.nextinpact.com ... * Connected to www.nextinpact.com (2400:cb00:2048:1::6819:f815) port 443 (#0) ... * Cipher selection: ALL:!EXPORT:!EXPORT40:!EXPORT56:!aNULL:!LOW:!RC4:@STRENGTH ... * SSL connection using TLSv1.2 / ECDHE-ECDSA-AES128-GCM-SHA256 * ALPN, server accepted to use h2 * Server certificate: * subject: C=US; ST=CA; L=San Francisco; O=CloudFlare, Inc.; CN=nextinpact.com ... > GET / HTTP/1.1 > Host: www.nextinpact.com > User-Agent: curl/7.52.1 > Accept: */*
On voit que l'algorithme utilisé par TLS est
ECDHE-ECDSA-AES128-GCM-SHA256, ce qui indique
ECDHE avec ECDSA. Le certificat du serveur doit donc inclure une clé
« courbe elliptique ». Regardons ledit certificat :
% openssl s_client -connect www.nextinpact.com:443 -showcerts | openssl x509 -text
Certificate:
...
Signature Algorithm: ecdsa-with-SHA256
Issuer: C = GB, ST = Greater Manchester, L = Salford, O = COMODO CA Limited, CN = COMODO ECC Domain Validation Secure Server CA 2
...
Subject: OU = Domain Control Validated, OU = PositiveSSL Multi-Domain, CN = ssl378410.cloudflaressl.com
Subject Public Key Info:
Public Key Algorithm: id-ecPublicKey
Public-Key: (256 bit)
...
ASN1 OID: prime256v1
NIST CURVE: P-256
...
X509v3 Subject Alternative Name:
DNS:ssl378410.cloudflaressl.com, DNS:*.baseballwarehouse.com, DNS:*.campusgroups.com, DNS:*.cretedoc.gr, DNS:*.groupment.com, DNS:*.icstage.com, DNS:*.ideacouture.com, DNS:*.industrialtour-deloitte.com, DNS:*.jonessnowboards.com, DNS:*.nextinpact.com, DNS:*.pcinpact.com, DNS:*.pinkapple.com, DNS:*.softballrampage.com, DNS:*.undercovercondoms.co.uk, DNS:baseballwarehouse.com, DNS:campusgroups.com, DNS:cretedoc.gr, DNS:groupment.com, DNS:icstage.com, DNS:ideacouture.com, DNS:industrialtour-deloitte.com, DNS:jonessnowboards.com, DNS:nextinpact.com, DNS:pcinpact.com, DNS:pinkapple.com, DNS:softballrampage.com, DNS:undercovercondoms.co.uk
Signature Algorithm: ecdsa-with-SHA256
On a bien une clé sur la courbe P-256.
Quel est l'état des mises en œuvre de ces algorithmes dans les bibliothèques TLS existantes ? ECDHE et ECDSA avec les courbes NIST sont très répandus. ECDHE avec la courbe Curve25519 est également dans plusieurs bibliothèques TLS. Par contre, EdDSA, ou ECDHE avec la courbe Curve448, sont certes implémentés mais pas encore largement déployés.
Les changements depuis le RFC 4492 sont résumés dans l'annexe B. Souvent, une norme récente ajoute beaucoup de choses par rapport à l'ancienne mais, ici, pas mal de chose ont au contraire été retirées :
- Plusieurs courbes peu utilisées disparaissent,
- Il n'y a plus qu'un seul format de point accepté (uncompressed),
- Des algorithmes comme toute la famille ECDH_ECDSA (ECDH et pas ECDHE, donc ceux dont la clé n'est pas éphémère) sont retirés.
Parmi les ajouts, le plus important est évidemment l'intégration des « courbes Bernstein », Curve25519 et Curve448, introduites par le RFC 7748. Et il y avait également plusieurs erreurs techniques dans le RFC 4492, qui sont corrigées par notre nouveau RFC.
Et, pendant que j'y suis, si vous voulez générer un certificat avec les courbes elliptiques, voici comment faire avec OpenSSL :
% openssl ecparam -out ec_key.pem -name prime256v1 -genkey % openssl req -new -key ec_key.pem -nodes -days 1000 -out cert.csr
J'ai utilisé ici la courbe P-256 (prime256v1 est encore un autre identificateur pour la courbe
NIST P-256, chaque organisme qui normalise dans ce domaine ayant ses
propres identificateurs). Si vous voulez la liste des courbes que
connait OpenSSL :
% openssl ecparam -list_curves
Ce blog est accessible en TLS mais pas avec des courbes elliptiques. En effet, l'AC que j'utilise, CAcert, ne les accepte hélas pas (« The keys you supplied use an unrecognized algorithm. For security reasons these keys can not be signed by CAcert. ») Il y a des raisons pour cela mais c'est quand même déplorable. (Enfin, j'accepte quand même ECDHE.)
Enfin, un échange TLS complet vu par tshark est visible ici.
Merci à Manuel Pégourié-Gonnard pour sa relecture vigilante.
L'article seul
RFC 8399: Internationalization Updates to RFC 5280
Date de publication du RFC : Mai 2018
Auteur(s) du RFC : R. Housley (Vigil Security)
Chemin des normes
Réalisé dans le cadre du groupe de travail IETF lamps
Première rédaction de cet article le 30 juillet 2018
Ce court RFC ajoute aux certificats PKIX du RFC 5280 la possibilité de contenir des adresses de courrier électronique dont la partie locale est en Unicode. Et il modifie légèrement les règles pour les noms de domaine en Unicode dans les certificats. Il a par la suite été remplacé par le RFC 9549.
Les certificats sur
l'Internet sont normalisés dans le RFC 5280, qui décrit un profil de
X.509 nommé PKIX
(définir un profil était nécessaire car la norme X.509 est bien
trop riche et complexe). Ce RFC 5280
permettait des noms de domaine en
Unicode (sections 4.2.1.10 et 7 du RFC 5280) mais il suivait l'ancienne norme
IDN, celle des RFC 3490 et suivants. Depuis, les IDN sont normalisés dans
le RFC 5890 et suivants, et notre nouveau
RFC 8399 modifie très légèrement le RFC 5280 pour s'adapter à cette nouvelle norme de noms de
domaines en Unicode. Les noms de domaine dans un
certificat peuvent être présents dans les champs Sujet (titulaire
du certificat) et
Émetteur (AC ayant signé le certificat) mais aussi dans les contraintes sur le nom (une
autorité de certification peut être
limitée à des noms se terminant en
example.com, par exemple).
Notez que, comme avant, ces noms sont
exprimés dans le certificat en Punycode
(RFC 3492, xn--caf-dma.fr au lieu de
café.fr). C'est un bon exemple du fait que
les limites qui rendaient difficiles d'utiliser des noms de
domaine en Unicode n'avaient rien à voir avec le DNS
(qui n'a jamais
été limité à ASCII, contrairement à ce qu'affirme une
légende courante). En fait, le problème venait des applications
(comme PKIX), qui ne s'attendaient pas à
des noms en Unicode. Un logiciel qui traite des certificats
aurait été bien étonné de voir des noms de domaines
non-ASCII, et aurait peut-être
planté. D'où ce choix du Punycode.
Nouveauté plus importante de notre RFC 8399, les adresses de courrier électronique en Unicode (EAI pour Email Address Internationalization). Elles étaient déjà permises par la section 7.5 du RFC 5280, mais seulement pour la partie domaine (à droite du @). Désormais, elles sont également possibles dans la partie locale (à gauche du @). Le RFC 8398 donne tous les détails sur ce sujet.
Reste à savoir quelles AC vont accepter
Unicode. J'ai testé avec Let's
encrypt (avec le client Dehydrated, en mettant le
Punycode dans domains.txt) et ça marche, regardez le certificat de
https://www.potamochère.fr/
% gnutls-cli www.potamochère.fr
...
- subject `CN=www.xn--potamochre-66a.fr', issuer `CN=Let's Encrypt Authority X3,O=Let's Encrypt,C=US', serial 0x03ed9617bb88bab3ad5b236675d1dd6e5d27, ...
D'autres AC acceptent ces noms en Unicode :
Gandi le fait aussi, regardez le certificat
de https://réussir-en.fr
Enfin, le registre du
.ru a participé au
développement
de logiciels pour traiter l'Unicode dans les certificats.
L'article seul
Testing DNS-over-TLS servers with the RIPE Atlas probes
First publication of this article on 18 July 2018
The RIPE Atlas probes can now perform DNS-over-TLS measurements, following RFC 7858. Several DNS-over-TLS servers exist. This article shows rapidly a few measurements.
To ask the RIPE Atlas
probes to perform
DNS-over-TLS tests,
we will use the Blaeu
software. Blaeu is made for one-off measurements, so the
results here are not long-term measurements of the evolution of
DNS-over-TLS servers. To do a DNS test with Blaeu, you use
blaeu-resolve :
% blaeu-resolve mamot.fr
[2001:67c:288::14] : 5 occurrences
Test #15279055 done at 2018-07-18T21:06:14Z
By default, the Atlas probes will use the locally configured
resolver. But we can direct the probes to a specific resolver,
with --nameserver :
% blaeu-resolve --nameserver dns.quad9.net www.france-ix.net
Nameserver dns.quad9.net
[2a00:a4c0:1:1::69] : 5 occurrences
Test #15279064 done at 2018-07-18T21:09:11Z
By default, this will use the usual DNS, in clear
text, over UDP. But you can now
ask for DNS over TLS, with --tls :
% blaeu-resolve --nameserver dns.quad9.net --tls www.bortzmeyer.org Nameserver dns.quad9.net [2001:4b98:dc0:41:216:3eff:fe27:3d3f 2605:4500:2:245b::42] : 5 occurrences Test #15279068 done at 2018-07-18T21:10:29Z
The --tls option will instruct the Atlas probes
to use TLS, here is the entire JSON request
which has been sent:
% blaeu-resolve --nameserver dnsovertls.sinodun.com --verbose --tls signal.eu.org
{'is_oneoff': True, 'definitions': [{'description': 'DNS resolution of signal.eu.org/AAAA via nameserver dnsovertls.sinodun.com', 'af': 6, 'type': 'dns', 'query_argument': 'signal.eu.org', 'query_class': 'IN', 'query_type': 'AAAA', 'set_rd_bit': True, 'tls': True, 'protocol': 'TCP', 'use_probe_resolver': False, 'target': 'dnsovertls.sinodun.com'}], 'probes': [{'requested': 5, 'type': 'area', 'value': 'WW', 'tags': {'include': ['system-ipv6-works']}}]}
...
The 'tls': True is the part that triggers DNS-over-TLS.
Now that we have this tool, what can we do? First, let's check if DNS-over-TLS works from everywhere. Some people voiced concerns that port 853, used by DNS-over-TLS, may be blocked on some networks. Let's try:
% blaeu-resolve --requested 1000 --nameserver getdnsapi.net --tls femen.org Nameserver getdnsapi.net [2607:5300:60:9fb5::2] : 126 occurrences [TUCONNECT (may be a TLS negotiation error)] : 845 occurrences [TIMEOUT] : 20 occurrences Test #15279078 done at 2018-07-18T21:13:45Z
First problem, a lot of TLS negotiation errors. That's because most
Atlas probes have old TLS code, and this specific server requires very recent
TLS options and ciphers (we have the same problem with
Cloudflare's 1.1.1.1
server and, indeed, with many servers).
The probes are currently being upgraded but
it is far from complete. Let's move to a server which is may be more lax:
% blaeu-resolve --requested 1000 --nameserver ns0.ldn-fai.net --tls femen.org Nameserver ns0.ldn-fai.net [TIMEOUT] : 970 occurrences [TUCONNECT (may be a TLS negotiation error)] : 12 occurrences [2607:5300:60:9fb5::2] : 10 occurrences Test #15279106 done at 2018-07-18T21:21:59Z
OK, way too many timeouts. It could be because the small server cannot handle all the Atlas probes banging at the same time (Atlas has an option to add jitter but it is not used here). Let's try with another server:
% blaeu-resolve --requested 1000 --nameserver unicast.censurfridns.dk --tls gitlab.isc.org Nameserver unicast.censurfridns.dk [2001:4f8:3:d::126] : 937 occurrences [TIMEOUT] : 32 occurrences [TUCONNECT (may be a TLS negotiation error)] : 12 occurrences Test #15279169 done at 2018-07-18T21:42:11Z
OK, this is better, 3 % timeouts only. But it is still too much. Is it
because of TLS? Let's try with regular DNS over
TCP, without TLS, using the same set of probes
(option --old_measurement):
% blaeu-resolve --requested 1000 --old_measurement 15279169 --nameserver unicast.censurfridns.dk --tcp gitlab.isc.org Warning: --requested=1000 ignored since a list of probes was requested Nameserver unicast.censurfridns.dk [2001:4f8:3:d::126] : 482 occurrences [TUCONNECT (may be a TLS negotiation error)] : 6 occurrences [TIMEOUT] : 5 occurrences Test #15279208 done at 2018-07-18T21:51:15Z
This time, we have 1.0 % of timeouts, so it seems TLS has indeed problems. (The error message "may be a TLS negotiation error" is spurious. The problems are instead connections refused by the server, or by a middlebox on the path.)
OK, may be the problem of timeouts is because the server unicast.censurfridns.dk is
not well connected? Let's try with a well managed and powerful
server, Quad9 :
% blaeu-resolve --requested 1000 --nameserver 9.9.9.9 --tls www.ietf.org Nameserver 9.9.9.9 [TIMEOUT] : 106 occurrences [2400:cb00:2048:1::6814:155 2400:cb00:2048:1::6814:55] : 872 occurrences [ERROR: SERVFAIL] : 1 occurrences [TUCONNECT (may be a TLS negotiation error)] : 11 occurrences Test #15277228 done at 2018-07-18T17:44:54Z
10 % of timeouts, that's certainly too much, and it proves that the 3 % problems before were not because the server was too weak. (Note there are also TLS negotiation errors, that shouldn't happen, but may have been triggered by middleboxes.) Again, let's try with ordinary DNS, using the same set of probes (unfortunately, many were not available for this comparison, so we have less results):
% blaeu-resolve --nameserver 9.9.9.9 --old_measurement 15277228 www.ietf.org Nameserver 9.9.9.9 [2400:cb00:2048:1::6814:155 2400:cb00:2048:1::6814:55] : 474 occurrences [ERROR: SERVFAIL] : 2 occurrences [TIMEOUT] : 19 occurrences Test #15277243 done at 2018-07-18T17:53:42Z
Only 3.8 % of timeouts, that's better. So, it seems there is indeed a problem specific to port 853, but it seems quite server-specific. (A routing problem would have give the same results on port 53 and 853.) Remember to take these results with a serious grain of salt: it's one measurement, on a specific day and hour, and the Internet is always changing. Serious measurements would require doing it again at different times.
And, even when it works, is DNS-over-TLS much slower? Let's display the RTT of the requests. First with TLS:
% blaeu-resolve --nameserver dns.quad9.net --requested 1000 --tls --displayrtt www.afnic.fr Nameserver dns.quad9.net [2001:67c:2218:30::24] : 849 occurrences Average RTT 2235 ms [TIMEOUT] : 129 occurrences Average RTT 0 ms [TUCONNECT (may be a TLS negotiation error)] : 15 occurrences Average RTT 0 ms Test #15279140 done at 2018-07-18T21:34:30Z
Then with ordinary TCP:
% blaeu-resolve --nameserver dns.quad9.net --old_measurement 15279140 --tcp --displayrtt www.afnic.fr Nameserver dns.quad9.net [2001:67c:2218:30::24] : 473 occurrences Average RTT 142 ms [TUCONNECT (may be a TLS negotiation error)] : 10 occurrences Average RTT 0 ms [TIMEOUT] : 9 occurrences Average RTT 0 ms ... Test #15279164 done at 2018-07-18T21:41:37Z
And finally with good old UDP:
% blaeu-resolve --nameserver dns.quad9.net --old_measurement 15279140 --displayrtt www.afnic.fr Nameserver dns.quad9.net [2001:67c:2218:30::24] : 471 occurrences Average RTT 237 ms [TIMEOUT] : 24 occurrences Average RTT 0 ms [NETWORK PROBLEM WITH RESOLVER] : 1 occurrences Average RTT 0 ms Test #15279176 done at 2018-07-18T21:45:42Z
Clearly, TLS is much slower, because we have to establish a TLS session first (in real-world use, DNS-over-TLS relies on session reuse.) Note also that TCP seems faster than UDP, which will require more investigation, may be the Atlas is not taking into account the time to establish a TCP connection.
Note that another public resolver show a different picture:
% blaeu-resolve --requested 1000 --nameserver 1.1.1.1 --tls www.ietf.org Nameserver 1.1.1.1 [TUCONNECT (may be a TLS negotiation error)] : 907 occurrences [TIMEOUT] : 35 occurrences [2400:cb00:2048:1::6814:155 2400:cb00:2048:1::6814:55] : 49 occurrences Test #15277231 done at 2018-07-18T17:47:12Z % blaeu-resolve --requested 1000 --nameserver 1.1.1.1 --old_measurement 15277231 www.ietf.org Warning: --requested=1000 ignored since a list of probes was requested Nameserver 1.1.1.1 [2400:cb00:2048:1::6814:155 2400:cb00:2048:1::6814:55] : 465 occurrences [TIMEOUT] : 29 occurrences [] : 1 occurrences Test #15277240 done at 2018-07-18T17:53:30Z
Here, we have more timeouts with UDP than with TLS+TCP.
L'article seul
Conférence « Cryptographie post-quantique » à Pas Sage en Seine
Première rédaction de cet article le 30 juin 2018
Dernière mise à jour le 7 juillet 2018
Le 29 juin, au festival Pas Sage en Seine , j'ai eu le plaisir de faire un exposé technique sur la cryptographie post-quantique. Vu les progrès des calculateurs quantiques, faut-il jeter tout de suite les algorithmes classiques comme RSA ?
Voici les supports de l'exposé :
- Version adaptée à l'écran,
- Version adaptée à l'impression sur des arbres morts,
- Source en LaTeX/Beamer (format certainement le plus utilisé à Pas Sage en Seine).
- Sur la quantique, mais pas sur le calcul quantique, j'avais déjà fait un article sur une application de la cryptographie quantique.
La vidéo est en ligne, format WebM (et sur PeerTube).
Les calculateurs quantiques utilisés, simulés ou réels :
- libquantum,
d'où venait le code
shorutilisé sur un des transparents, - Quintuple,
- Et le vrai calculateur quantique d'IBM. Voir son excellente documentation, ou l'exposé vidéo introductif de Talia Gershon. Depuis la rédaction de ces transparents, IBM propose également au public un ordinateur de 16 qubits.
Les logiciels post-quantiques utilisés :
Il y avait plein d'autres trucs géniaux (comme d'habitude) à Pas Sage en Seine, n'hésitez pas à regarder le programme. Mes préférés (c'est complètement subjectif) : celui de Luckylex sur les lanceurs d'alerte, dénonçant la répression dont ils sont victimes, celui très concret de Nanar DeNanardon sur les innombrables traces numériques que nous laissons, avec plein de détails peu connus, comme le rôle de DHCP (cf. RFC 7819 pour l'exposé du problème, et RFC 7844 pour une solution), l'exposé de David Legrand (Next Inpact) sur « 20 ans d’évolution du numérique et de Next INpact », retraçant l'aventure d'un fanzine devenu un pilier de l'information libre sur le numérique (cf. leur dernier projet, La presse libre), celui de Shaft « Un panda roux peut-il avoir une vie privée ? » montrant que Firefox a de sérieuses failles en matière de protection de la vie privée (mais les autres navigateurs sont pires), en partie parce que la Fondation Mozilla est trop proche des GAFA. Mais le meilleur exposé était celui de Suzanne Vergnolle et Benoît Piédallu sur leur projet « GDPRBookClub », un très intéressant projet de travail en commun sur le RGPD.
Sinon, sur les phénomènes quantiques, et notamment sur l'intrication, Marc Kaplan m'a fait découvrir cette excellente BD qui l'explique très bien, et avec humour.
L'article seul
Aurait-il fallu faire IPv6 « compatible » avec IPv4 ?
Première rédaction de cet article le 7 juin 2018
Le déploiement du protocole IPv6 continue, mais à un rythme très réduit par rapport à ce qui était prévu et espéré. À cette vitesse, on aura encore de l'IPv4 dans 20 ou 30 ans. Face à cette lenteur exaspérante, on entend souvent des Monsieur Jesaistout affirmer que c'est la conséquence d'une erreur fondamentale au début de la conception du protocole IPv6 : il aurait fallu le faire « compatible avec IPv4 ». Qu'est-ce que cela veut dire, et est-ce que cela aurait été possible ?
On trouve par exemple ce regret d'une absence de compatibilité dans le livre de Milton Mueller, « Will the Internet Fragment?: Sovereignty, Globalization and Cyberspace ». Cet auteur, quoique non-technicien, fait en général très attention à être rigoureux sur les questions techniques et à ne pas écrire de bêtises. Pourtant, là, il en a fait une belle (« in a fateful blunder, [...] the IETF did not make it backwards compatible with the old one »). Pour comprendre en quoi, voyons d'abord en quoi IPv6 est incompatible avec IPv4. Cela concerne notamment les routeurs et les applications. En effet, le format de l'en-tête des paquets IPv6 est très différent de celui de l'en-tête des paquets IPv4. Un routeur ne connaissant qu'IPv4 ne peut rien faire d'un paquet IPv6, il ne peut même pas l'analyser. IPv6 imposait donc une mise à jour de tous les routeurs (aujourd'hui largement faite, même sur le bas de gamme). Et les applications ? Normalement, une bonne partie des applications n'a pas besoin de connaitre les détails de la couche réseau. Après tout, c'est un des buts du modèle en couches que d'isoler les applications des particularités du réseau. Mais il y a des exceptions (application serveur ayant des ACL et devant donc manipuler des adresses IP, par exemple), et, surtout, beaucoup d'applications ne sont pas écrites avec une API de haut niveau : le programmeur ou la programmeuse a utilisé, par exemple, l'API socket, qui expose des tas de détails inutiles, comme la taille des adresses IP, liant ainsi l'application à un protocole réseau particulier. IPv6 impose donc de mettre à jour pas mal d'applications, ce qui est fait depuis longtemps pour les grands logiciels libres connus (Apache, Unbound, Postfix, etc) mais pas forcément pour les petits logiciels locaux développés par l'ESN du coin.
Aurait-on pu s'en tirer en concevant IPv6 différemment ? En gros, non. Pour voir pourquoi, il faut repartir du cahier des charges d'IPv6 : le principal problème était l'épuisement des adresses IPv4. Il fallait donc des adresses plus longues (elles font 128 bits pour IPv6 contre 32 pour IPv4). Même si cela avait été le seul changement dans le format de l'en-tête des paquets, cela aurait suffit à le rendre incompatible, et donc à obliger à changer les routeurs, ainsi que les applications dépendant d'IPv4. Regretter que l'IETF ait changé d'autres aspects de l'en-tête, qu'on aurait pu laisser tranquilles, n'a pas de sens : rien que le changement de taille des adresses invalide tout le code IPv4. Cela ne serait pas le cas si les en-têtes des paquets IP étaient encodés en TLV, ou bien dans un autre format avec des champs de taille variable. Mais, pour des raisons de performance (un routeur peut avoir à traiter des centaines de millions de paquets par seconde), les paquets IP ont un encodage en binaire, avec des champs de taille fixe. Toute modification de la taille d'un de ces champs nécessite donc de changer tout le code de traitement des paquets, tous les ASIC des routeurs.
Même en l'absence de ce problème d'encodage « sur le câble », il n'est pas sûr
que tous les programmes existants supporteraient le changement de
taille des adresses. Combien d'applications anciennes tiennent
pour acquis que les adresses IP ont une taille de seulement 32
bits et, si elles sont écrites en C, les
mettent dans des int (entier qui fait en
général 32 bits) ?
Néanmoins, malgré ces faits connus depuis longtemps, on croise relativement souvent des affirmations du genre « l'IETF aurait juste dû rajouter des bits aux adresses mais sans changer le format ». Comme on l'a vu, tout changement de taille des adresses change le format. Et, si on ne change pas la taille des adresses, pourquoi utiliser un nouveau protocole ? À moins que, malgré Shannon, on ne croit à la possibilité de mettre 128 bits dans 32 bits ?
Cela ne veut pas dire qu'IPv4 et IPv6 doivent être incapables de se parler, comme « des navires qui se croisent dans la nuit ». On peut penser qu'une solution de traduction d'adresses permettrait au moins certains échanges. Mais attention à ne pas copier simplement le NAT d'IPv4 : IPv4 utilise les ports de TCP et UDP pour identifier une session particulière et savoir où envoyer les paquets. Il n'y a que 16 bits pour stocker les ports, et cela ne suffirait donc pas pour permettre de représenter toutes les adresses IPv6 dans des adresses IPv4 (il manquerait encore 80 bits à trouver…) Il y a bien des solutions avec traduction d'adresses, comme NAT64 (RFC 6146) mais elles ne peuvent s'utiliser que dans des cas limités (pour NAT64, entre un client purement IPv6 et un serveur purement IPv4), et entrainent des dépendances supplémentaires (pour NAT64, la nécessité de disposer d'un résolveur DNS spécial, cf. RFC 6147). Bref, enfonçons le clou : il n'existe pas et il ne peut pas exister de mécanisme permettant une compatibilité complète entre un protocole qui utilise des adresses de 32 bits et un protocole qui utilise des adresses de 128 bits. Il y a des solutions partielles (la plus simple, qu'on oublie souvent, est d'avoir un relais applicatif), mais pas de solution complète.
Bien sûr, c'est en supposant qu'on veut garder la compatibilité avec les anciennes machines et logiciels. Si on repartait de zéro, on pourrait faire un protocole de couche 3 aux adresses de taille variable, mais ce ne serait plus IP, et un tel protocole serait encore plus difficile et coûteux à déployer qu'une nouvelle version d'IP, comme IPv6.
Est-ce simplement moi qui ne vois pas de solution, ou bien est-ce vraiment un problème de fond ? Jusqu'à présent, plein de gens ont râlé « il aurait fallu faire un IPv6 compatible avec IPv4 » mais je n'ai encore vu aucune proposition détaillée indiquant comment faire cela. Il y a plein d'idées « dos de l'enveloppe », de ces idées griffonnées en deux minutes mais qui n'iront jamais plus loin. Écrire un tweet, c'est une chose. Spécifier, même partiellement, un protocole, c'est autre chose. On voit par exemple quelqu'un qui sort de son domaine de compétence (la cryptographie) écrire « they designed the IPv6 address space as an alternative to the IPv4 address space, rather than an extension to the IPv4 address space »). Mais il n'est pas allé plus loin. Au moins, l'auteur du ridicule projet baptisé IPv10 avait fait l'effort de détailler un peu sa proposition (le même auteur avait commis un projet de connecter les satellites par des fibres optiques). C'est d'ailleurs le fait que sa proposition soit relativement détaillée qui permet de voir qu'elle ne tient pas la route : le format des paquets (la seule chose qu'il spécifie de manière un peu précise) étant différent, son déploiement serait au moins aussi lent que celui d'IPv6. Le cryptographe cité plus haut, lui, ne s'est même pas donné cette peine.
Si vous n'êtes pas convaincus par mon raisonnement, je vous propose d'essayer de spécifier un « IPv4 bis » qui serait compatible avec IPv4 tout en offrant davantage d'adresses. Vous pouvez écrire cette spécification sous forme d'un Internet-Draft, d'un article scientifique, ou d'un article sur votre blog. Mettre en œuvre n'est pas obligatoire. Envoyez-moi l'URL ensuite, je suis curieux de voir les résultats. (Rappel : les vagues propositions, trop vagues pour être réfutées, ne sont pas acceptées, il faut une vraie spécification, qu'on puisse soumettre à une analyse technique.) Quelques exemples :
- IPv10, déjà cité,
- EnIP (notez son optimisme sur les pare-feux qui, tout à coup, respecteraient ce qu'ils ne connaissent pas).
- Le délirant IPv4+ d'Elad Cohen, bien démonté par Johann.
L'article seul
Version 11 d'Unicode
Première rédaction de cet article le 6 juin 2018
Aujourd'hui 6 juin, la nouvelle version d'Unicode est sortie, la 11.0. Une description officielle des principaux changements est disponible mais voici ceux qui m'ont intéressé particulièrement. (Il n'y a pas de changement radical.)
Pour explorer plus facilement la grande base Unicode, j'utilise un programme qui la convertit en SQL et permet ensuite de faire des analyses variées. Faisons quelques requêtes SQL :
ucd=> SELECT count(*) AS Total FROM Characters; total -------- 137439
Combien de caractères sont arrivés avec la version 11 ?
ucd=> SELECT version,count(version) FROM Characters GROUP BY version ORDER BY version::float; ... 9.0 | 7500 10.0 | 8518 11.0 | 684
684 nouveaux, bien moins que dans les versions précédentes. Quels sont ces nouveaux caractères ?
ucd=> SELECT To_U(codepoint) AS Codepoint, name FROM Characters WHERE version='11.0'; codepoint | name -----------+---------------------------------------------------------------------------- ... U+1F9B8 | SUPERHERO U+1F9B9 | SUPERVILLAIN U+1F9C1 | CUPCAKE ... U+10D00 | HANIFI ROHINGYA LETTER A ... U+16E60 | MEDEFAIDRIN SMALL LETTER M ... U+1D2E0 | MAYAN NUMERAL ZERO ... U+1F12F | COPYLEFT SYMBOL ... U+1F99D | RACCOON U+1F99E | LOBSTER U+1F99F | MOSQUITO ... U+1F9B0 | EMOJI COMPONENT RED HAIR
Outre les habituels emojis plus ou moins utiles, et le symbole du copyleft (enfin !) qui plaira aux libristes, on trouve aussi six écritures plus ou moins nouvelles comme le medefaidrin, les chiffres mayas ou comme le hanifi. Les Rohingyas se font massacrer mais au moins leur écriture est désormais dans Unicode.
Toujours dans les emojis, on notera que la norme a précisé que
les emojis n'ont
pas forcément de genre. Et elle a ajouté des modificateurs
permettant de faire varier l'image comme le U+1F9B0 pour mettre des
cheveux roux à un personnage, ou comme les
changements
de direction. Une des erreurs les plus souvent commises à
propos des emojis (et d'ailleurs à propos d'Unicode en général) est
de croire que l'image proposée par Unicode est normative : ce n'est
qu'un exemple, et chaque auteur de police
peut l'adapter (comme l'a récemment montré l'affaire
de la salade Google). Ainsi, si l'image proposée d'un coureur est un
homme aux cheveux sombres, rien n'empêche une police Unicode
d'utiliser une femme aux cheveux blonds. Pour les cas où il faut
préciser, Unicode offre des mécanismes de modification d'un emoji
comme les séquences
ZWJ. Si elles sont gérées par votre logiciel (cela semble
rare aujourd'hui dans le monde Unix libre mais ça marche, par exemple, chez Apple), vous devriez voir ici un coureur et une
coureuse : 🏃♂ 🏃♀. Si
vous voyez au contraire un personnage puis le symbole mâle ou
femelle, c'est que votre logiciel ne traite pas ces séquences
ZWJ. Voici ce que
cela donne avec un Safari sur
Mac : 
Tiens, d'ailleurs, combien de caractères Unicode sont des symboles (il n'y a pas que les emojis parmi eux, mais Unicode n'a pas de catégorie « emoji ») :
ucd=> SELECT count(*) FROM Characters WHERE category IN ('Sm', 'Sc', 'Sk', 'So');
count
-------
7110
Ou, en plus détaillé, et avec les noms longs des catégories :
ucd=> SELECT description,count(category) FROM Characters,Categories WHERE Categories.name = Characters.category AND category IN ('Sm', 'Sc', 'Sk', 'So') GROUP BY category, description;
description | count
-----------------+-------
Other_Symbol | 5984
Math_Symbol | 948
Modifier_Symbol | 121
Currency_Symbol | 57
(4 rows)
L'article seul
RFC 8373: Negotiating Human Language in Real-Time Communications
Date de publication du RFC : Mai 2018
Auteur(s) du RFC : R. Gellens (Core Technology Consulting)
Chemin des normes
Réalisé dans le cadre du groupe de travail IETF slim
Première rédaction de cet article le 26 mai 2018
Le groupe de travail SLIM de l'IETF s'occupe de définir des mécanismes pour le choix d'une langue lors de la communication. Son premier RFC, le RFC 8255, concernait le courrier électronique. Ce nouveau RFC concerne, lui, les communications « en temps réel », comme la téléphonie sur IP.
Un scénario d'usage typique est celui d'un client qui appelle le support d'une société internationale. Mettons que le client a pour langue maternelle l'ourdou mais peut se débrouiller en anglais. On veut qu'il puisse préciser cet ordre de préférences, et, idéalement, que le logiciel utilisé dans le call center le route automatiquement vers un employé qui parle ourdou ou, si aucun n'est disponible, vers un employé qui parle anglais. Plus vital, le scénario d'un appel d'urgence où un touriste danois en vacances en Italie appelle le 112 et où il faut trouver très vite quelqu'un qui peut parler une langue qu'il comprend (sachant qu'en situation d'urgence, on est moins à l'aise avec les langues étrangères). Comme le dit avec euphémisme le RFC « avoir une langue en commun est utile pour la communication ». Pour gérer tous ces scénarios, notre RFC va utiliser les attributs de SDP (RFC 4566, SDP est un format - pas un protocole, en dépit de son nom - déjà très utilisé dans les protocoles de communication instantanée pour transmettre des métadonnées au sujet d'une communication).
Parfois, on a déjà l'information disponible (si on appelle une personne qu'on connait et qui nous connait), et déjà choisi une langue (par exemple une audioconférence dans une entreprise où la règle est que tout se fasse en anglais). Notre RFC traite le cas où on n'a pas cette information, et il faut donc une négociation au début de la communication. Cela implique que le logiciel des deux côtés ait été configuré avec les préférences et capacités linguistiques des deux parties (une question d'interface utilisateur, non spécifiée par ce RFC).
Notez qu'il peut y avoir plusieurs langues différentes utilisées, une pour chaque flux de données. Par exemple, l'appelant peut parler dans une langue que son interlocuteur comprend, mais qu'il a du mal à parler, et il utilisera donc une autre langue pour la réponse. Notez aussi que la communication n'est pas uniquement orale, elle peut être écrite, par exemple pour les malentendants. Le RFC rappelle à juste titre qu'un sourd n'est pas forcément muet et qu'il ou elle peut donc choisir l'oral dans une direction et le texte dans une autre. (Au passage, la synchronisation des lèvres, pour la lecture sur les lèvres, est traitée dans le RFC 5888.)
La solution choisie est décrite en détail dans la section 5 de
notre RFC. Elle consiste en deux attributs SDP,
hlang-send et
hlang-recv (hlang =
human language). Leur valeur est évidemment une
étiquette de langue, telles qu'elles sont
normalisées dans le RFC 5646. Dans une offre
SDP, hlang-send est une liste (pas une langue
unique) de langues que l'offreur sait parler, séparées par des
espaces, donnée dans l'ordre de
préférence décroissante, et
hlang-recv une liste de langues qu'elle ou
lui comprend. Notez qu'il est de la responsabilité de l'offreur
(typiquement celui ou celle qui appelle) de proposer des choix
réalistes (le RFC donne le contre-exemple d'un offreur qui demanderait à
parler en hongrois et à avoir la réponse en
portugais…) D'autre part, notre RFC
recommande de bien lire la section 4.1 du RFC 5646, qui indique d'étiqueter intelligement, et
notamment de ne pas être trop spécifique : si on est australien et qu'on comprend bien
l'anglais, indiquer comme langue en est
suffisant, préciser (ce qui serait une étiquette légale)
en-AU est inutile et même dangereux si le
répondant se dit « je ne sais pas parler avec l'accent australien,
tant pis, je raccroche ».
La langue choisie par le répondant est indiquée dans la
réponse. hlang-send et
hlang-recv sont cette fois des langues
uniques. Attention, ce qui est envoi pour l'une des parties est
réception pour l'autre : hlang-send dans la
réponse est donc un choix parmi les
hlang-recv de l'offre. L'offreur (l'appelant) est ainsi prévenu du choix qui a
été effectué et peut se préparer à parler la langue indiquée par
le hlang-recv du répondant, et à comprendre
celle indiquée par le hlang-send.
Voici un exemple simple d'un bloc SDP (on n'en montre qu'une partie), où seul l'anglais est proposé ou accepté (cet exemple peut être une requête ou une réponse) :
m=audio 49170 RTP/AVP 0
a=hlang-send:en
a=hlang-recv:en
Le cas où hlang-send et
hlang-recv ont la même valeur sera sans doute
fréquent. Il avait même été envisagé de permettre un seul
attribut (par exemple hlang) dans ce cas
courant mais cela avait été écarté, au profit de la solution
actuelle, plus générale.
Un exemple un peu plus compliqué où la demande propose trois langues (espagnol, basque et anglais dans l'ordre des préférences décroissantes) :
m=audio 49250 RTP/AVP 20
a=hlang-send:es eu en
a=hlang-recv:es eu en
Avec une réponse où l'espagnol est utilisé :
m=audio 49250 RTP/AVP 20
a=hlang-send:es
a=hlang-recv:es
Et si ça rate ? S'il n'y a aucune langue en commun ? Deux choix sont possibles, se résigner à utiliser une langue qu'on n'avait pas choisi, ou bien raccrocher. Le RFC laisse aux deux parties la liberté du choix. En cas de raccrochage, le code d'erreur SIP à utiliser est 488 (Not acceptable here) ou bien 606 (Not acceptable), accompagné d'un en-tête d'avertissement avec le code 308, par exemple :
Warning: 308 code proxy.example.com
"Incompatible language specification: Requested languages "fr
zh" not supported. Supported languages are: "es en".
Si la langue indiquée est une langue des signes, elle peut être utilisée dans un canal vidéo, mais évidemment pas dans un canal audio. (Le cas d'un canal texte est laissé à l'imagination des lecteurs. Le cas des sous-titres, ou autres textes affichés dans une vidéo, n'est pas traité par notre RFC.)
Voici un exemple bien plus riche, avec plusieurs médias. La vidéo en langue des signes argentine, le texte en espagnol (ou à la rigueur en portugais), et un canal audio, mêmes préférences que le texte :
m=video 51372 RTP/AVP 31 32
a=hlang-send:aed
m=text 45020 RTP/AVP 103 104
a=hlang-send:es pt
m=audio 49250 RTP/AVP 20
a=hlang-recv:es pt
Voici une réponse possible à cette requête, avec de l'espagnol pour le canal texte et pour la voix. Aucune vidéo n'est proposée, sans doute car aucune n'était disponible dans la langue demandée :
m=video 0 RTP/AVP 31 32
m=text 45020 RTP/AVP 103 104
a=hlang-recv:es
m=audio 49250 RTP/AVP 20
a=hlang-send:es
Notez que ce RFC ne fournit pas de mécanisme pour exprimer des préférences entre les différents canaux (texte et audio, par exempe), uniquement entre langues pour un même canal.
Les deux attributs hlang-recv et
hlang-send ont été ajoutés au registre
IANA des attributs SDP.
Notons que la section 8 du RFC, sur la protection de la vie privée, rappelle qu'indiquer les préférences linguistiques peut permettre d'apprendre des choses sur l'utilisateur, par exemple sa nationalité. Une section Privacy considerations, quoique non obligatoire, est de plus en plus fréquente dans les RFC.
Enfin, question alternatives, le RFC note aussi (section 4) qu'on aurait pu utiliser
l'attribut existant lang, qui existe déjà
dans SDP (RFC 4566, section 6). Mais il n'est pas
mentionné dans le RFC 3264, ne semble pas
utilisé à l'heure actuelle, et ne permet pas de spécifier une
langue différente par direction de communication.
À ma connaissance, il n'y a pas encore de mise en œuvre de ce RFC mais comme il est cité dans des documents normatifs, par exemple dans le NENA 08-01 de la North American Emergency Number Association, il est possible qu'elles apparaissent bientôt.
L'article seul
RFC 8375: Special-Use Domain 'home.arpa.'
Date de publication du RFC : Mai 2018
Auteur(s) du RFC : P. Pfister (Cisco Systems), T. Lemon
(Nominum)
Chemin des normes
Réalisé dans le cadre du groupe de travail IETF homenet
Première rédaction de cet article le 18 mai 2018
Ce nouveau RFC a l'air compliqué comme
cela, mais en fait il ne fait qu'une chose : remplacer, dans le
protocole Homenet/HNCP (Home Networking Control Protocol), le
nom de domaine .home
par home.arpa.
home.arpa est désormais enregistré
dans la liste officielle des noms de domaine
spéciaux, ceux qui ne passent pas par les mécanismes
habituels d'enregistrement de noms de domaine, et/ou les mécanismes habituels
de résolution DNS. (Cette liste a été créée
par le RFC 6761, et critiquée par le RFC 8244. home.arpa n'étant
pas un TLD, il pose moins de problèmes politiciens.)
Quelle est l'utilité de ce nom home.arpa ?
La série de protocoles Homenet
(l'architecture de Homenet est décrite dans le RFC 7368)
vise à doter la maison de l'utilisateur normal (pas participant à
l'IETF) d'un ensemble de réseaux
IPv6 qui marchent automatiquement, sans
intervention humaine. Parmi les protocoles Homenet,
HNCP, normalisé dans le protocole RFC 7788 est le protocole de configuration.
Il utilise un suffixe pour les noms de domaines
comme nas.SUFFIXE ou
printer.SUFFIX. C'est ce
home.arpa qui va désormais servir de
suffixe.
Mais quel était le problème avec le suffixe
.home du RFC 7788 ?
D'abord, le RFC 7788 avait commis une grosse
erreur, enregistrée sous le numéro
4677 : il ne tenait pas compte des règles du RFC 6761, et réservait ce TLD
.home sans suivre les procédures du RFC 6761. Notamment, il ne listait pas les
particularités qui font que ce domaine est spécial (pour
home.arpa, notre nouveau RFC 8375 le fait dans sa section 5), et il ne demandait pas à
l'IANA de le mettre dans le registre
des noms de domaine spéciaux. Cela avait des conséquences
pratiques comme le fait que ce .home ne
pouvait pas marcher à travers un résolveur DNS validant (puisque ce nom n'existait pas
du tout dans la racine). Un bon article sur ce choix et sur les
problèmes qu'il posait était « Homenet, and the hunt for a name ».
On peut aussi ajouter que le risque de « collision » entre deux
noms de domaine était élevé puisque pas mal de réseaux locaux sont
nommés sous .home et que ce nom est un de
ceux qui « fuitent » souvent vers les serveurs
racines (voir par exemple les statistiques
du serveur racine L.). On peut consulter à ce sujet les
documents de l'ICANN « New
gTLD Collision Risk Mitigation » et
« New
gTLD Collision Occurence Management ». Notons
qu'il y avait eu plusieurs
candidatures
(finalement rejetées en
février 2018) pour un .home
en cours auprès de l'ICANN. Exit, donc,
.home, plus convivial mais trop
convoité. Demander à l'ICANN de déléguer un
.home pour l'IETF (ce qui aurait été
nécessaire pour faire une délégation DNSSEC
non signée, cf. RFC 4035, section 4.3)
aurait pris dix ou quinze ans.
À la place, voici home.arpa, qui profite
du RFC 3172, et du caractère décentralisé
du DNS, qui permet de déléguer des
noms sous .arpa.
L'utilisation de home.arpa n'est pas
limitée à HNCP, tous les protocoles visant le même genre d'usage
domestique peuvent s'en servir. Il n'a évidemment qu'une
signification locale.
La section 3 décrit le comportement général attendu avec
home.arpa. Ce n'est pas un nom de domaine comme les
autres. Sa signification est purement
locale. printer.home.arpa désignera une
machine à un endroit et une autre machine dans une autre
maison. Les serveurs DNS globaux ne peuvent
pas être utilisés pour résoudre les noms sous home.arpa. Tous les
noms se terminant par ce suffixe doivent être traités uniquement
par les résolveurs locaux, et jamais transmis à l'extérieur.
Notez que, la plupart du temps, les utilisateurs ne verront pas
le suffixe home.arpa, l'interface des
applications « Homenet » leur masquera cette
partie du nom. Néanmoins, dans certains cas, le nom sera sans
doute visible, et il déroutera sans doute certains utilisateurs,
soit à cause du suffixe arpa qui n'a pas de
signification pour eux, soit parce qu'ils ne sont pas anglophones et qu'ils ne comprennent
pas le home. Il n'y a pas de solution miracle
à ce problème.
La section 4 est le formulaire d'enregistrement dans le registre des noms spéciaux, suivant les formalités du RFC 6761, section 5. (Ce sont ces formalités qui manquaient au RFC 7788 et qui expliquent l'errata.) Prenons-les dans l'ordre (relisez bien la section 5 du RFC 6761) :
- Les humains et les applications qu'ils utilisent n'ont pas à faire quelque chose de particulier, ces noms, pour eux, sont des noms comme les autres.
- Les bibliothèques de résolution de noms (par exemple, sur
Mint, la GNU libc)
ne devraient pas non plus appliquer un traitement spécial aux
noms en
home.arpa. Elles devraient passer par le mécanisme de résolution normal. Une exception : si la machine a été configurée pour utiliser un autre résolveur DNS que celui de la maison (un résolveur public, par exemple, qui ne connaîtra pas votrehome.arpa), il peut être nécessaire de mettre une règle particulière pour faire résoudre ces noms par un résolveur local. - Les résolveurs locaux (à la maison), eux, doivent traiter ces noms à part, comme étant des « zones locales » à l'image de celles décrites dans le RFC 6303. Bref, le résolveur ne doit pas transmettre ces requêtes aux serveurs publics faisant autorité (il y a une exception pour le cas particulier des enregistrements DS). Ils doivent transmettre ces requêtes aux serveurs locaux qui font autorité pour ces noms (cf. section 7).
- Les serveurs publics faisant autorité n'ont pas besoin
d'un comportement particulier. Par exemple, ceux qui font
autorité pour
.arparetournent une délégation normale.
Voici la délégation :
% dig @a.root-servers.net ANY home.arpa
; <<>> DiG 9.10.3-P4-Debian <<>> @a.root-servers.net ANY home.arpa
; (2 servers found)
;; global options: +cmd
;; Got answer:
;; ->>HEADER<<- opcode: QUERY, status: NOERROR, id: 48503
;; flags: qr rd; QUERY: 1, ANSWER: 0, AUTHORITY: 4, ADDITIONAL: 1
;; WARNING: recursion requested but not available
;; OPT PSEUDOSECTION:
; EDNS: version: 0, flags: do; udp: 4096
;; QUESTION SECTION:
;home.arpa. IN ANY
;; AUTHORITY SECTION:
home.arpa. 172800 IN NS blackhole-1.iana.org.
home.arpa. 172800 IN NS blackhole-2.iana.org.
home.arpa. 86400 IN NSEC in-addr.arpa. NS RRSIG NSEC
home.arpa. 86400 IN RRSIG NSEC 8 2 86400 (
20180429000000 20180415230000 56191 arpa.
K4+fNoY6SXQ+VtHsO5/F0oYrRjZdNSG0MSMaeDSQ78aC
NHko4uqNAzoQzoM8a2joFeP4wOL6kVQ72UJ5zqd/iZJD
0ZSh/57lCUVxjYK8sL0dWy/3xr7kbaqi58tNVTLkp8GD
TfyQf5pW1rtRB/1pGzbmTZkK1jXw4ThG3e9kLHk= )
;; Query time: 24 msec
;; SERVER: 2001:503:ba3e::2:30#53(2001:503:ba3e::2:30)
;; WHEN: Mon Apr 16 09:35:35 CEST 2018
;; MSG SIZE rcvd: 296
La section 5 rassemble les changements dans la norme HNCP (RFC 7788. C'est juste un remplacement de
.home par home.arpa.
Quelques petits trucs de sécurité (section 6). D'abord, il ne
faut pas s'imaginer que ces noms locaux en
home.arpa sont plus sûrs que n'importe quel
autre nom. Ce n'est pas parce qu'il y a home
dedans qu'on peut leur faire confiance. D'autant plus qu'il y a,
par construction, plusieurs home.arpa, et
aucun moyen, lorsqu'on se déplace de l'un à l'autre, de les
différencier. (Des travaux ont lieu pour concevoir un mécanisme
qui pourrait permettre d'avertir l'utilisateur « ce n'est pas le
home.arpa que vous pensez » mais ils n'ont
pas encore abouti.)
home.arpa n'est pas sécurisé par
DNSSEC. Il ne serait pas possible de mettre
un enregistrement DS dans
.arpa puisqu'un tel
enregistrement est un condensat de la clé
publique de la zone et que chaque home.arpa
qui serait signé aurait sa propre clé. Une solution possible aurait été
de ne pas déléguer
home.arpa. .arpa étant
signé, une telle non-délégation aurait pu être validée par DNSSEC
(« denial of existence »). La réponse DNS
aurait été (commande tapée avant la délégation de home.arpa) :
% dig A printer.home.arpa ... ;; ->>HEADER<<- opcode: QUERY, status: NXDOMAIN, id: 37887 ;; flags: qr rd ra ad; QUERY: 1, ANSWER: 0, AUTHORITY: 6, ADDITIONAL: 1 ... ;; AUTHORITY SECTION: arpa. 10800 IN SOA a.root-servers.net. nstld.verisign-grs.com. ( 2017112001 ; serial 1800 ; refresh (30 minutes) 900 ; retry (15 minutes) 604800 ; expire (1 week) 86400 ; minimum (1 day) ) arpa. 10800 IN RRSIG SOA 8 1 86400 ( 20171203120000 20171120110000 36264 arpa. QqiRv85fb6YO/79ZdtQ8Ke5FmZHF2asjLrNejjcivAAo... arpa. 10800 IN RRSIG NSEC 8 1 86400 ( 20171203120000 20171120110000 36264 arpa. dci8Yr95yQtL9nEBFL3dpdMVTK3Z2cOq+xCujeLsUm+W... arpa. 10800 IN NSEC as112.arpa. NS SOA RRSIG NSEC DNSKEY e164.arpa. 10800 IN RRSIG NSEC 8 2 86400 ( 20171203120000 20171120110000 36264 arpa. jfJS6QuBEFHWgc4hhtvdfR0Q7FCCgvGNIoc6169lsxz7... e164.arpa. 10800 IN NSEC in-addr.arpa. NS DS RRSIG NSEC ;; Query time: 187 msec ;; SERVER: 127.0.0.1#53(127.0.0.1) ;; WHEN: Mon Nov 20 20:28:27 CET 2017 ;; MSG SIZE rcvd: 686
Ici, on reçoit un NXDOMAIN (ce domaine n'existe pas), et les
enregistrements NSEC qui prouvent que
home.arpa n'existe pas non plus (rien entre
e164.arpa et in-addr.arpa).
Mais cela
aurait nécessité un traitement spécial de
home.arpa par le résolveur validant (par
exemple, sur Unbound,
domain-insecure: "home.arpa"). Finalement, le
choix fait a été celui d'une délégation non sécurisée (section 7
du RFC), vers les
serveurs blackhole-1.iana.org et blackhole-2.iana.org :
% dig NS home.arpa
; <<>> DiG 9.10.3-P4-Debian <<>> NS home.arpa
;; global options: +cmd
;; Got answer:
;; ->>HEADER<<- opcode: QUERY, status: NOERROR, id: 64059
;; flags: qr rd ra; QUERY: 1, ANSWER: 2, AUTHORITY: 0, ADDITIONAL: 1
;; OPT PSEUDOSECTION:
; EDNS: version: 0, flags: do; udp: 4096
;; QUESTION SECTION:
;home.arpa. IN NS
;; ANSWER SECTION:
home.arpa. 190 IN NS blackhole-1.iana.org.
home.arpa. 190 IN NS blackhole-2.iana.org.
;; Query time: 0 msec
;; SERVER: 127.0.0.1#53(127.0.0.1)
;; WHEN: Mon Apr 16 09:36:25 CEST 2018
;; MSG SIZE rcvd: 98
Cette délégation a été faite le 15 mars 2018.
Le domaine home.arpa a été ajouté dans
le registre des noms de domaine spéciaux
ainsi que dans celui
des noms servis localement.
En testant avec les
sondes RIPE Atlas, on voit que tous les résolveurs ne
voient pas la même chose, ce qui est normal, chaque maison pouvant
avoir son home.arpa local :
% blaeu-resolve -r 1000 -q SOA home.arpa [prisoner.iana.org. hostmaster.root-servers.org. 1 604800 60 604800 604800] : 548 occurrences [prisoner.iana.org. hostmaster.root-servers.org. 1 1800 900 604800 604800] : 11 occurrences [prisoner.iana.org. hostmaster.root-servers.org. 1 1800 900 604800 15] : 33 occurrences [prisoner.iana.org. hostmaster.root-servers.org. 2002040800 1800 900 604800 60480] : 229 occurrences [ERROR: FORMERR] : 1 occurrences [ERROR: SERVFAIL] : 132 occurrences [] : 4 occurrences [prisoner.iana.org. hostmaster.root-servers.org. 1 604800 60 604800 3600] : 11 occurrences [prisoner.iana.org. hostmaster.trex.fi. 1 604800 86400 2419200 86400] : 4 occurrences [prisoner.iana.org. ops.inx.net.za. 1513082668 10800 3600 604800 3600] : 2 occurrences [TIMEOUT(S)] : 19 occurrences Test #12177308 done at 2018-04-16T07:38:32Z
On voit sur ce premier test que la grande majorité des sondes
voient le vrai SOA (numéro de série 1 ou 2002040800 ; curieusement,
les serveurs faisant autorité envoient des numéros
différents). Certaines voient un tout autre SOA (par exemple celle
où l'adresse du responsable est en Afrique du
Sud ou bien en Finlande), et le
numéro de série très différent. Ce n'est pas un problème ou un
piratage : le principe de home.arpa est que
chacun peut avoir le sien.
Pour une autre description de ce home.arpa,
voyez l'article de
John Shaft (où il utilise Unbound) et
(en anglais), regardez celui
de Daniel Aleksandersen.
À l'heure actuelle, toutes les mises en œuvre en logiciel libre
que j'ai regardées utilisent encore .home, mais
elles semblent souvent non maintenues.
L'article seul
RFC 8374: BGPsec Design Choices and Summary of Supporting Discussions
Date de publication du RFC : Avril 2018
Auteur(s) du RFC : K. Sriram (USA NIST)
Pour information
Première rédaction de cet article le 1 mai 2018
Ce RFC est un peu spécial : il ne normalise pas un protocole, ni des procédures internes à l'IETF, et il n'est pas non plus la description d'un problème à résoudre, ou un cahier des charges d'une solution à développer. Non, ce RFC est la documentation a posteriori des choix qui ont été effectués lors du développement de BGPsec, une solution de sécurisation du routage Internet. C'est donc un document utile si vous lisez les RFC sur BGPsec, comme le RFC 8205 et que vous vous demandez « mais pourquoi diable ont-ils choisi cette approche et pas cette autre, qui me semble bien meilleure ? »
Un petit rappel du contexte : le protocole de
routage BGP
fonctionne en échangeant des informations entre pairs, sur les
routes que chaque pair sait joindre. Par défaut, un pair peut
raconter n'importe quoi, dire qu'il a une route vers
2001:db8::/32 alors qu'il n'est pas le
titulaire de ce préfixe et n'a pas non plus appris cette route
d'un de ses pairs. Cela rend donc le routage Internet assez
vulnérable. Pour le sécuriser, il existe plusieurs mécanismes qui
font que, en pratique, ça ne marche pas trop
mal. L'IETF a développé une solution
technique, qui a deux couches : une infrastructure à clés publiques, la
RPKI, normalisée dans les RFC 6480 et RFC 6481, et une seconde
couche, les services qui utilisent la RPKI pour authentifier tel
ou tel aspect du routage. Deux de ces services sont normalisés,
les ROA (Route Origin Authorization) des RFC 6482
et RFC 6811, qui servent à authentifier
l'AS d'origine d'un préfixe, et
BGPsec (RFC 8205),
qui sert à authentifier le chemin d'AS, la
liste des AS empruntés par une annonce de
route (cf. section 2.1.1 de notre RFC). Sans BGPsec, les ROA,
utilisés seuls, ne peuvent pas arrêter certaines attaques
(cf. RFC 7132, qui explique quelles menaces
traite BGPsec, et RFC 7353, cahier des
charges de BGPsec). Par exemple, si l'AS 64641, malhonnête, veut
tromper son pair, l'AS 64642, à propos du préfixe
2001:db8::/32, et que ce préfixe a un ROA
n'autorisant que 64643 à être à l'origine, le malhonnête peut
fabriquer une annonce avec le chemin d'AS 64641
[éventuellement d'autres AS] 64643 (rappelez-vous que
les chemins d'AS se lisent de droite à gauche) et l'envoyer à
64641. Si celui-ci vérifie le ROA, il aura l'impression que tout
est normal, l'AS 64643 étant bien indiqué comme l'origine. Et cela
marchera même si les annonces de l'AS 64643 ne sont jamais passées
par ce chemin ! BGPsec répare ce problème en transportant un
chemin d'AS signé,
authentifiant toutes les étapes.
Lors du développement de BGPsec, un document avait été rédigé pour documenter tous les choix effectués, mais n'avait pas été publié. C'est désormais chose faite avec ce RFC, qui documente les choix, les justifie, et explique les différences entre ces choix initiaux et le protocole final, modifié après un long développement. Parmi les points importants du cahier des charges (RFC 7353) :
- Valider la totalité du chemin d'AS (et pas seulement détecter certains problèmes, comme le font les ROA),
- Déployable de manière incrémentale puisqu'il est évidemment impossible que tous les opérateurs adoptent BGPsec le même jour,
- Ne pas diffuser davantage d'informations que celles qui sont déjà diffusées. Par exemple, les opérateurs ne souhaitent pas forcément publier la liste de tous leurs accords d'appairage.
Finie, l'introduction, passons tout de suite à certains des choix qui ont été effectués. (Il est évidemment recommandé de lire le RFC 8205 avant, puis de lire notre RFC 8374 après, si on veut tous les choix documentés.) D'abord, à quoi ressemblent les signatures, et les nouveaux messages BGP (section 2 de notre RFC). Les signatures BGPsec signent le préfixe IP, l'AS signataire, et l'AS suivant à qui on va transmettre l'annonce. Le premier point important est qu'on signe l'AS suivant, de manière à créer une chaîne de signatures vérifiables. Autrement, un attaquant pourrait fabriquer un faux chemin à partir de signatures correctes.
Si on utilise le prepending d'AS, la
première version de BGPsec prévoyait une signature à chaque fois,
mais on peut finalement mettre une seule signature pour la
répétition d'AS, avec une variable pCount qui indique leur nombre (RFC 8205, section 3.1), afin
de diminuer le nombre de signatures (les signatures peuvent
représenter la grande majorité des octets d'une annonce BGP).
Le second point important est que certains attributs ne sont
pas pas signés, comme par exemple la
préférence locale (RFC 4271, section 5.1.5)
ou les communautés (cf. RFC 1997). Ces
attributs pourront donc être modifiés par un attaquant à sa
guise. Ce n'est pas si grave que ça en a l'air car la plupart de
ces attributs n'ont de sens qu'entre deux AS (c'est le cas de la
communauté NO_EXPORT) ou sont internes à un
AS (la
préférence locale). Sur ces courtes distances, on espère de toute
façon que la session BGP sera protégée, par exemple par AO (RFC 5925).
La signature est transportée dans un attribut BGP optionnel et non-transitif (qui n'est pas transmis tel quel aux routeurs suivants). Optionnel car, sinon, il ne serait pas possible de déployer BGPsec progressivement. Et non-transitif car un routeur BGPsec n'envoie les signatures que si le routeur suivant lui a dit qu'il savait gérer BGPsec.
Dans le message BGP signé, le routeur qui signe est identifié par sa clé publique, pas par le certificat entier. Cela veut dire qu'on ne peut valider les signatures que si on a accès à une dépôt de la RPKI, avec les certificats.
La section 3 de notre RFC traite le cas des retraits de route : contrairement aux annonces, ils ne sont pas signés. Un AS est toujours libre de retirer une route qu'il a annoncée (BGP n'accepte pas un retrait venant d'un autre pair). Si on a accepté l'annonce, il est logique d'accepter le retrait (en supposant évidemment que la session entre les deux routeurs soit raisonnablement sécurisée).
La section 4, elle, parle des algorithmes de signature. Le RFC 8208 impose ECDSA avec la courbe P-256 (cf. RFC 6090). RSA avait été envisagé mais ECDSA avait l'avantage de signatures bien plus petites (cf. l'étude du NIST sur les conséquences de ce choix).
Une autre décision importante dans cette section est la possibilité d'avoir une clé par routeur et pas par AS (cf. RFC 8207). Cela évite de révoquer un certificat global à l'AS si un seul routeur a été piraté. (Par contre, il me semble que c'est indiscret, permettant de savoir quel routeur de l'AS a relayé l'annonce, une information qu'on n'a pas forcément actuellement.)
Décision plus anecdotique, en revanche, celle comme quoi le nom
dans le certificat (Subject) sera la chaîne
router suivie du numéro d'AS (cf. RFC 5396) puis de
l'identité BGP du routeur. Les détails figurent dans le RFC 8209.
Voyons maintenant les problèmes de performance (section 5). Par exemple, BGPsec ne permet pas de regrouper plusieurs préfixes dans une annonce, comme on peut le faire traditionnellement avec BGP. C'est pour simplifier le protocole, dans des cas où un routeur recevrait une annonce avec plusieurs préfixes et n'en transmettrait que certains. Actuellement, il y a en moyenne quatre préfixes par annonce (cf. l'étude faite par l'auteur du RFC). Si tout le monde adoptait BGPsec, on aurait donc quatre fois plus d'annonces, et il faudra peut-être dans le futur optimiser ce cas.
On l'a vu plus haut, il n'est pas envisageable de déployer BGPsec partout du jour au lendemain. Il faut donc envisager les problèmes de coexistence entre BGPsec et BGP pas sécurisé (section 6 de notre RFC). Dès que deux versions d'un protocole, une sécurisée et une qui ne l'est pas, coexistent, il y a le potentiel d'une attaque par repli, où l'attaquant va essayer de convaindre une des parties de choisir la solution la moins sécurisée. Actuellement, BGPsec ne dispose pas d'une protection contre cette attaque. Ainsi, il n'y a pas de moyen de savoir si un routeur qui envoie des annonces non-signées le fait parce qu'il ne connait pas BGPsec, ou simplement parce qu'un attaquant a modifié le trafic.
La possibilité de faire du BGPsec est négociée à l'établissement de la session BGP. Notez qu'elle est asymétrique. Par exemple, il est raisonnable qu'un routeur de bordure signe ses propres annonces mais accepte tout de la part de ses transitaires, et ne lui demande donc pas d'envoyer les signatures. Pendant un certain temps (probablement plusieurs années), nous aurons donc des ilots BGPsec au milieu d'un océan de routeurs qui font du BGP traditionnel. On peut espérer qu'au fur et à mesure du déploiement, ces ilots se rejoindront et formeront des iles, puis des continents.
La question de permettre des chemins d'AS partiellement signés avait été discutée mais cela avait été rejeté : il faut signer tout le chemin, ou pas du tout. Des signatures partielles auraient aidé au déploiement progressif mais auraient été dangereuses : elle aurait permis aux attaquants de fabriquer des chemins valides en collant des bouts de chemins signés - et donc authentiques - avec des bouts de chemins non-signés et mensongers.
La section 7 de notre RFC est consacrée aux interactions entre BGPsec et les fonctions habituelles de BGP, qui peuvent ne pas bien s'entendre avec la nouvelle sécurité. Par exemple, les très utiles communautés BGP (RFC 1997 et RFC 8092). On a vu plus haut qu'elles n'étaient pas signées du tout et donc pas protégées. La raison est que les auteurs de BGPsec considèrent les communautés comme mal fichues, question sécurité. Certaines sont utilisées pour des décisions effectives par les routeurs, d'autres sont juste pour le débogage, d'autres encore purement pour information. Certaines sont transitives, d'autres utilisées seulement entre pairs se parlant directement. Et elles sont routinement modifiées en route. Le RFC conseille, pour celles qui ne sont utilisées qu'entre pairs directs, de plutôt sécuriser la session BGP.
Pour les communautés qu'on veut voir transmises transitivement, il avait été envisagé d'utiliser un bit libre pour indiquer que la communauté était transitive et donc devait être incluse dans la signature. Mais la solution n'a pas été retenue. Conseil pratique, dans la situation actuelle : attention à ne pas utiliser des communautés transmises transitivement pour des décisions de routage.
Autre cas pratique d'interaction avec un service très utile, les serveurs de route. Un point d'échange peut fonctionner de trois façons :
- Appairages directs entre deux membres et, dans ce cas, BGPsec n'a rien de particulier à faire.
- Utilisation d'un serveur de routes qui ajoute son propre
AS dans le chemin (mais, évidemment, ne change pas le
NEXT_HOP, c'est un serveur de routes, pas un routeur). Cette méthode est de loin la plus rare des trois. Là aussi, BGPsec n'a rien de particulier à faire. - Utilisation d'un serveur de routes qui n'ajoute pas son
propre AS dans le chemin. Sur un gros point d'échange, cette
méthode permet d'éviter de gérer des dizaines, voire des
centaines d'appairages. Pour BGPsec, c'est le cas le plus
délicat. Il faut que le serveur de routes mette son AS dans le
chemin, pour qu'il puisse être validé, mais en positionnant
pCountà 0 (sa valeur normale est 1, ou davantage si on utilise le prepending) pour indiquer qu'il ne faut pas en tenir compte pour les décisions de routage (fondées sur la longueur du chemin), seulement pour la validaton.
Un point de transition intéressant est celui des numéros d'AS de quatre octets, dans le RFC 4893. La technique pour que les AS ayant un tel numéro puisse communiquer avec les vieux routeurs qui ne comprennent pas ces AS est un bricolage utilisant un AS spécial (23456), bricolage incompatible avec BGPsec, qui, d'ailleurs, exige que les AS de quatre octets soient acceptés. En pratique, on peut espérer que les derniers routeurs ne gérant pas les AS de quatre octets auront disparu bien avant que BGPsec soit massivement déployé.
La section 8 du RFC discute de la validation des chemins d'AS signés. Par exemple, le RFC 8205 demande qu'un routeur transmette les annonces ayant des signatures invalides. Pourquoi ? Parce que la RPKI n'est que modérement synchrone : il est parfaitement possible qu'un nouveau certificat ne soit arrivé que sur certains routeurs et que, donc, certains acceptent la signature et d'autres pas. Il ne faut donc pas préjuger de ce que pourront valider les copains.
Une question qui revient souvent avec les techniques de sécurité (pas seulement BGPsec mais aussi des choses comme DNSSEC) est « et si la validation échoue, que doit-on faire des données invalides ? » Vous ne trouverez pas de réponse dans le RFC : c'est une décision locale. Pour BGPsec, chaque routeur, ou plus exactement son administrateur, va décider de ce qu'il faut faire avec les annonces dont le chemin d'AS signé pose un problème. Contrairement à DNSSEC, où la validation peut donner trois résultats (oui, en fait, quatre, mais je simplifie, cf. RFC 4035), « sûr », « non sûr », et « invalide », BGPsec n'a que deux résultats possibles, « valide » et « invalide ». L'état « invalide » regroupe aussi bien les cas où le chemin d'AS n'est pas signé (par exemple parce qu'un routeur non-BGPsec se trouvait sur le trajet) que le cas où une signature ne correspond pas aux données (les deux états « non sûr » et « invalide » de DNSSEC se réduisent donc à un seul ici). Il avait été discuté de faire une division plus fine entre les différents cas d'invalidité mais il avait semblé trop complexe de rendre en compte tous les cas possibles. Notez que « invalide » couvre même le cas où un ROA valide l'origine (un cas particulier des chemins partiellement signés, déjà traités).
Donc, si une annonce est invalide, que doit faire le routeur ? D'abord, la décision d'accepter ou pas une route dépend de plusieurs facteurs, la validation BGPsec n'en étant qu'un seul. Ensuite, il n'est pas évident de traiter tous les cas. D'où la décision de laisser le problème à l'administrateur réseaux.
Ah, et si vous utilisez iBGP, notez que la validation BGPsec ne se fait qu'en bord d'AS. Vous pouvez transporter l'information comme quoi une annonce était valide ou invalide comme vous voulez (une communauté à vous ?), il n'existe pas de mécanisme standard dans iBGP pour cela.
Enfin, la section 9 de notre RFC traite de quelques problèmes d'ordre opérationnel. Mais pensez à lire le RFC 8207 avant. Par exemple, elle estime que BGPsec, contrairement à la validation avec les ROA seuls, nécessitera sans doute du nouveau matériel dans les routeurs, comme un coprocesseur cryptographique, et davantage de RAM. C'est une des raisons pour lesquelles on ne verra certainement pas de déploiement significatif de BGPsec avant des années. Ceci dit, au début, les routeurs BGPsec auront peu de travail supplémentaire, précisément puisqu'il y aura peu d'annonces signées, donc pourront retarder les mises à jour matérielles. D'ici que BGPsec devienne banal, des optimisations comme celles décrites dans cet exposé ou celui-ci, ou encore dans l'article « Design and analysis of optimization algorithms to minimize cryptographic processing in BGP security protocols » aideront peut-être.
L'article seul
A Fediverse/Mastodon bot for DNS queries
First publication of this article on 25 April 2018
Last update on of 3 May 2018
I created a bot to answer DNS queries over the fediverse (decentralized social network, best known implementation being Mastodon). What for? Well, mostly for the fun, a bit to learn about Mastodon bots, and a bit because, in these times of censorship, filtering, lying DNS resolvers and so on, offering to the users a way to make DNS requests to the outside can be useful. This article is to document this project.
First, how to use it. Once you have a
Fediverse account (for
Mastodon, see https://joinmastodon.org/@DNSresolver@botsin.space. You just tell it
the domain name you want to resolve. Here is an example, with the
answer: 
If you want, you can specify the DNS
query type after the name (the defaut is A, for IPv4
adresses): 
The bot replies with the same level of confidentiality as the query. So, if you want the request to be private, use the "direct" mode. Note that the bot itself is very indiscreet: it logs everything, and I read it. So, it will be only privacy against third parties.
And, yes IDN do work. This is 2018, we now know that not
everyone on Earth use the latin
alphabet: 
Last, but not least, when the bot sees an IP
address, it automatically does a "reverse" query:
If you are a command-line fan, you can use the madonctl tool to send the query to the bot:
% madonctl toot "@DNSresolver@botsin.space framapiaf.org"
You can even make a shell function:
# Function definition
dnsfediverse() {
madonctl toot --visibility direct "@DNSresolver@botsin.space $1"
}
# Function usages
% dnsfediverse www.face-cachee-internet.fr
% dnsfediverse societegenerale.com\ NS
There is at least a second public bot using this code,
@ResolverCN@mastodon.xyz, which uses a
chinese DNS resolver so you can see a (part of)
the chinese censorship. To do DNS when normal access is blocked or otherwise
unavailable, you have other solutions. You can use DNS looking glasses, public DNS resolver over the
Web, the Twitter bot @1111Resolver,
email auto-responder resolver@lookup.email…
Now, the implementation. (You can get all the files at
https://framagit.org/bortzmeyer/mastodon-DNS-bot/
Mastodon.py has a very good
documentation. I first create two files with the
credentials to connect to the Mastodon instance of the bot. I
choosed the Mastodon instance https://botsin.spaceDNSresolver. Then, first
file to create, DNSresolver_clientcred.secret
is to register the application, with this Python code:
Mastodon.create_app(
'DNSresolverapp',
api_base_url = 'https://botsin.space/',
to_file = 'DNSresolver_clientcred.secret'
)
Second file, DNSresolver_usercred.secret, is
after you logged in:
mastodon = Mastodon(
client_id = 'DNSresolver_clientcred.secret',
api_base_url = 'https://botsin.space/'
)
mastodon.log_in(
'the-email-address@the-domain',
'the secret password',
to_file = 'DNSresolver_usercred.secret'
)
Then we can connect to the instance of the bot and listen to incoming requests with the streaming API:
mastodon = Mastodon(
client_id = 'DNSresolver_clientcred.secret',
access_token = 'DNSresolver_usercred.secret',
api_base_url = 'https://botsin.space')
listener = myListener()
mastodon.stream_user(listener)
And everything else is event-based. When an incoming request comes
in, the program will "immediately" call
listener. Use of the streaming API (instead
of polling) makes the bot very responsive.
But what is listener? It has to be an
instance of the class
StreamListener from Mastodon.py, and to
provide routines to act when a given event takes place. Here, I'm
only interested in notifications (when people mention the bot in a
message, a toot):
class myListener(StreamListener):
def on_notification(self, notification):
if notification['type'] == 'mention':
# Parse the request, find out domain name and possibly query type
# Perform the DNS query
# Post the result on the fediverse
The routine on_notification will receive the
toot as a dictionary in the parameter
notification. The fields of this dictionary
are
documented.
For the first step, parsing the request, Mastodon unfortunately returns the content of the toot in HTML. We have to extract the text with lxml:
doc = html.document_fromstring(notification['status']['content']) body = doc.text_content()
We can then get the parameters of the query with a
regular expression (remember all the files
are at https://framagit.org/bortzmeyer/mastodon-DNS-bot/
Second thing to do, perform the actual DNS query. We use dnspython which is very simple to use, sending the request to the local resolver (an Unbound) with just one function call:
msg = self.resolver.query(qname, qtype)
for data in msg:
answers = answers + str(data) + "\n"
Finally, we send the reply through the Mastodon API:
id = notification['status']['id']
visibility = notification['status']['visibility']
mastodon.status_post(answers, in_reply_to_id = id,
visibility = visibility)
We retrieve the visibility (public/private/etc) from the original message, and we mention the original identifier of the toot, to let Mastodon keep both query and reply in the same thread.
That's it, you now have a Mastodon bot! Of course, the real code is more complicated. You have to guard against code injection (for instance, using a call to the shell to call dig for DNS resolution would be dangerous if there were semicolons in the domain name), that's why we keep only the text from the HTML. And, of course, because the sender of the original message can be wrong (or malicious), you have to consider many possible failures and guard accordingly. The exception handlers are therefore longer than the "real" code. Remember the Internet is a jungle!
One last problem: when you open a streaming connection to Mastodon, sometimes the network is down, or the server restarted, or closed the connection violently, and you won't be notified. (A bit like a TCP connection with no traffic: you have no way of knowing if it is broken or simply idle, besides sending a message.) The streaming API solves this problem by sending "heartbeats" every fifteen seconds. You need to handle these heartbeats, and do something if they stop arriving. Here, we record the time of the last heartbeat in a file:
def handle_heartbeat(self):
self.heartbeat_file = open(self.hb_filename, 'w')
print(time.time(), file=self.heartbeat_file)
self.heartbeat_file.close()
We run the Mastodon listener in a separate process, with Python's
multiprocessing module:
proc = multiprocessing.Process(target=driver,
args=(log, tmp_hb_filename[1],tmp_pid_filename[1]))
proc.start()
And we have a timer that checks the timestamps written in the heartbeats file, and kills the listener process if the last heartbeat is too old:
h = open(tmp_hb_filename[1], 'r')
last_heartbeat = float(h.read(128))
if time.time() - last_heartbeat > MAXIMUM_HEARTBEAT_DELAY:
log.error("No more heartbeats, kill %s" % proc.pid)
proc.terminate()
We use multiprocessing and not threading
because threads in Python have some annoying
limitations. For instance, there is no way to kill them (no
equivalent of the terminate() we use. Here is
the log file when running with "debug" verbosity. Note the times:
2018-05-02 18:01:25,745 - DEBUG - HEARTBEAT 2018-05-02 18:01:40,746 - DEBUG - HEARTBEAT 2018-05-02 18:01:55,758 - DEBUG - HEARTBEAT 2018-05-02 18:02:10,757 - DEBUG - HEARTBEAT 2018-05-02 18:02:25,770 - DEBUG - HEARTBEAT 2018-05-02 18:02:40,769 - DEBUG - HEARTBEAT 2018-05-02 18:03:38,473 - ERROR - No more heartbeats, kill 28070 2018-05-02 18:03:38,482 - DEBUG - Done, it exited with code -15 2018-05-02 18:03:38,484 - DEBUG - Creating a new process 2018-05-02 18:03:38,659 - INFO - Driver/listener starts, PID 20396 2018-05-02 18:03:53,838 - DEBUG - HEARTBEAT 2018-05-02 18:04:08,837 - DEBUG - HEARTBEAT
The second possibility that I considered for writing the bot, but discarded, is the use of madonctl. It is a very powerful command-line tool. You can listen to the stream of toots:
% madonctl stream --command "command.sh"
Where command.sh is a program that will parse the
message (the toot) and act. A more detailed example is:
% madonctl stream --notifications-only --notification-types mentions --command "dosomething.sh"
where dosomething.sh has the content:
#!/bin/sh echo "A notification !!!" echo Args: $* cat echo ""
If you write to the account used by madonctl, the script
dosomething.sh will display:
Command output: A notification !!!
Args:
- Notification ID: 3907
Type: mention
Timestamp: 2018-04-09 13:43:34.746 +0200 CEST
- Account: (8) @bortzmeyer@mastodon.gougere.fr - S. Bortzmeyer ✅
- Status ID: 99829298934602015
From: bortzmeyer@mastodon.gougere.fr (S. Bortzmeyer ✅)
Timestamp: 2018-04-09 13:43:34.704 +0200 CEST
Contents: @DNSresolver Test 1
Test 2
URL: https://mastodon.gougere.fr/@bortzmeyer/99829297476510997
You then have to parse it. For my DNS bot, it was not ideal, that's why I choosed Mastodon.py.
Other resources about bot implementation on the fediverse:
- The Python source of the bot @Birb, using Mastodon.py, like me.
- The source of the bot @DrawMeASheep.
- A source in Node.js for an auto-responding bot.
Thanks a lot to Alarig for the initial server (now down) and the good ideas.
L'article seul
À propos d'une tribune « Contre le numérique à l’école »
Première rédaction de cet article le 8 avril 2018
Dans Libération daté du 5 avril 2018, on a pu lire une tribune d'« un collectif d'enseignants » s'opposant vigoureusement au numérique à l'école. Quels étaient leurs arguments ?
Ils étaient variés. On y trouvait une critique de la pression qui pousse à acheter toujours plus d'équipements numériques, une inquiétude face aux conséquences « psychologiques et cognitives » qu'aurait le numérique, un reproche fait à Facebook de chercher délibérement à rendre ses utilisateurs « accros », un scepticisme vis-à-vis du numérique présenté comme solution magique à tous les problèmes…
On le voit dans cette liste, il y a plein d'arguments auxquels je suis sensible. En effet, les vendeurs comme Apple font tout leur possible pour vendre leurs produits, y compris avec la complicité de l'Éducation Nationale. En effet, Facebook joue un rôle très néfaste de plein de façons. Et, c'est sûr, le numérique ne résout pas tous les problèmes : on n'en finit pas avec l'échec scolaire juste en distribuant des tablettes, comme c'est pourtant souvent affirmé dans les discours ministériels. Mais le problème est que leur liste est vraiment fourre-tout.
Bien sûr, les vendeurs… vendent. Mais ils n'existent pas que dans le numérique ! Dans le domaine du livre, est-ce que Gallimard ou Hachette sont moins des entreprises capitalistes que Microsoft ou Samsung ? Les auteurs dénoncent « une boulimie consumériste » mais elle est une conséquence du capitalisme, pas une spécificité du numérique.
Ensuite, je ne suis pas moi-même un utilisateur de Facebook donc je ne vais pas défendre ce service, mais, ici, quel rapport avec le numérique ? De même que le numérique ne se réduit pas à l'Internet, l'Internet ne se réduit pas au Web, et le Web ne se réduit pas à Facebook. Ces nuances sont trop compliquées ? Pas pour des enseignants, j'espère, qui doivent justement apprendre aux enfants des points délicats et subtils. Commencer par leur expliquer que le Web est bien plus riche que Facebook et offre bien d'autres possibilités serait un bon départ.
Et l'affirmation comme quoi le numérique n'est pas la solution miracle ? Clairement, il ne l'est pas. Mais cela veut-il dire qu'il est complètement inutile, et peut être ignoré complètement ? Une bonne partie du corps enseignant avait déjà suivi ce raisonnement pour le cinéma, la bande dessinée et la télévision, avec le résultat qu'on sait. On retrouve ici une démarche classique des conservateurs : protester contre chaque nouveauté, refuser de considérer son utilisation, puis s'y mettre quand cette nouveauté a été remplacée par une autre. J'ai entendu lors d'une réunion au lycée un enseignant d'économie se plaindre de ce que les enfants ne regardaient pas assez la télévision, « par la faute d'Internet » et ne connaissaient pas assez l'actualité. Quand on sait quelle fut la réaction de ces conservateurs à la télévision, on ne peut qu'être assez étonné de cet amour tardif pour le petit écran.
Plus grave, la tribune publiée dans Libération reprend une légende urbaine, celle comme quoi « les cadres de la Silicon Valley [protègent] leurs propres enfants des écrans, dans et en dehors de l’école ». Cette légende a pourtant été réfutée plusieurs fois (voir par exemple l'article d'Emmanuel Davidenkoff ou bien la chronique de Xavier de la Porte). Mais elle continue à circuler, sans tenir compte des faits. C'est inquiétant pour des enseignants qui ont à former l'esprit critique des enfants, à leur apprendre à se méfier des fake news, à leur montrer l'indispensable questionnement devant les légendes répétées en boucle.
Pourtant, il y aurait des tas de choses à critiquer dans l'Éducation Nationale, à propos du numérique. C'est le cas par exemple du scandaleux accord entre Microsoft et l'Éducation Nationale (accord ancien mais régulièrement reconduit fièrement par le gouvernement), qui sous-traite l'éducation au numérique à une entreprise de logiciels privateurs. Mais les auteurs n'en parlent pas. Je soupçonne que c'est parce qu'ils ne suivent pas tellement ce qui se passe dans le monde du numérique et de l'éducation…
J'aurais bien envoyé ce texte au « collectif d'enseignants » mais je n'ai pas trouvé leur adresse.
L'article seul
RFC 8352: Energy-Efficient Features of Internet of Things Protocols
Date de publication du RFC : Avril 2018
Auteur(s) du RFC : C. Gomez (UPC), M. Kovatsch (ETH Zurich), H. Tian (China Academy of Telecommunication Research), Z. Cao (Huawei Technologies)
Pour information
Réalisé dans le cadre du groupe de travail IETF lwig
Première rédaction de cet article le 7 avril 2018
Les objets contraints, engins connectés ayant peu de capacités (un capteur de température dans la nature, par exemple), ont en général une réserve d'énergie électrique très limitée, fournie par des piles ou batteries à la capacité réduite. L'usage des protocoles de communication traditionnels, souvent très bavards, épuiserait rapidement ces réserves. Ce RFC étudie les mécanismes utilisables pour limiter la consommation électrique, et faire ainsi durer ces objets plus longtemps.
La plupart des protocoles de couche 2 utilisés pour ces « objets contraints » disposent de fonctions pour diminuer la consommation électrique. Notre RFC décrit ces fonctions, et explique comment les protocoles de couches supérieures, comme IP peuvent en tirer profit. Si vous ne connaissez pas le monde des objets contraints, et les problèmes posés par leur connexion à l'Internet, je recommande fortement la lecture des RFC 6574, RFC 7228, et RFC 7102. Le but des techniques présentées dans ce RFC est bien de faire durer plus longtemps la batterie, ce n'est pas un but écologique. Si l'objet est alimenté en permanence (une télévision connectée, ou bien un grille-pain connecté), ce n'est pas considéré comme problème.
Des tas de travaux ont déjà eu lieu sur ce problème de la diminution de la consommation électrique de ces objets. Il y a eu moins d'efforts sur celle des protocoles réseau, et ce sont ces efforts que résume ce RFC. Les protocoles traditionnels étaient conçus pour des machines alimentées en permanence et pour qui la consommation électrique n'était pas un problème. Diffuser très fréquemment une information, même inutile, n'était pas perçu comme du gaspillage, contrairement à ce qui se passe avec l'Internet des Objets. (Voir le RFC 7772 pour une solution à un tel problème.)
L'IETF a déjà développé un certain nombre de protocoles qui sont spécifiques à cet « Internet des Objets ». Ce sont par exemple 6LoWPAN (RFC 6282, RFC 6775 et RFC 4944), ou bien le protocole de routage RPL (RFC 6550) ou encore l'alternative à HTTP CoAP (RFC 7252). En gros, l'application fait tourner du CoAP sur IPv6 qui est lui-même au-dessus de 6LoWPAN, couche d'adaptation d'IP à des protocoles comme IEEE 802.15.4. Mais l'angle « économiser l'énergie » n'était pas toujours clairement mis en avant, ce que corrige notre nouveau RFC.
Qu'est ce qui coûte cher à un engin connecté (cher en terme d'énergie, la ressource rare) ? En général, faire travailler le CPU est bien moins coûteux que de faire travailler la radio, ce qui justifie une compression énergique. Et, question réseau, la réception n'est pas forcément moins coûteuse que la transmission. L'étude Powertrace est une bonne source de mesures dans ce domaine mais on peut également lire « Measuring Power Consumption of CC2530 With Z-Stack ». Le RFC contient aussi (section 2) des chiffres typiques, mesurés sur Contiki et publiés dans « The ContikiMAC Radio Duty Cycling Protocol » :
Une technique courante quand on veut réduire la consommation électrique lors de la transmission est de réduire la puissance d'émission. Mais cela réduit la portée, donc peut nécessiter d'introduire du routage, ce qui augmenterait la consommation.
On a vu que la simple écoute pouvait consommer beaucoup d'énergie. Il faut donc trouver des techniques pour qu'on puisse couper l'écoute (éteindre complètement la radio), tout en gardant la possibilité de parler à l'objet si nécessaire. Sans ce duty-cycling (couper la partie radio de l'objet, cf. RFC 7228, section 4.3), la batterie ne durerait que quelques jours, voire quelques heures, alors que certains objets doivent pouvoir fonctionner sans entretien pendant des années. Comment couper la réception tout en étant capable de recevoir des communications ? Il existe trois grandes techniques de RDC (Radio Duty-Cycling, section 3 de notre RFC) :
- Échantillonage : on n'est pas en réception la plupart du temps mais on écoute le canal à intervalles réguliers. Les objets qui veulent me parler doivent donc émettre un signal pendant une durée plus longue que la période d'échantillonage.
- Transmissions aux moments prévus. On annonce les moments où on est prêt à recevoir. Cela veut dire que les objets qui veulent parler avec moi doivent le faire au bon moment.
- Écouter quand on transmet. Dans ce cas, ceux qui ont envie de me parler doivent attendre que j'émette d'abord.
Dans les trois cas, la latence va évidemment en souffrir. On doit faire un compromis entre réduire la consommation électrique et augmenter la latence. On va également diminuer la capacité du canal puisqu'il ne pourra pas être utilisé en permanence. Ce n'est pas forcément trop grave, un capteur a peu à transmettre, en général.
Il existe plein de méthodes pour gagner quelques μJ, comme le regroupement de plusieurs paquets en un seul (il y a un coût fixe par paquet, indépendamment de leur taille). Normalement, le RDC est quelque part dans la couche 2 et les protocoles IETF, situés plus haut, ne devraient pas avoir à s'en soucier. Mais une réduction sérieuse de la consommation électrique nécessite que tout le monde participe, et que les couches hautes fassent un effort, et connaissent ce que font les couches basses, pour s'adapter.
La section 3.6 de notre RFC détaille quelques services que fournissent les protocoles de couche 2 de la famille IEEE 802.11. Une station (un objet ou un ordinateur) peut indiquer au point d'accès (AP, pour access point) qu'il va s'endormir. L'AP peut alors mémoriser les trames qui lui étaient destinées, pour les envoyer plus tard. IEEE 802.11v va plus loin en incluant des mécanismes comme le proxy ARP (répondre aux requêtes ARP à la place de l'objet endormi).
Bluetooth a un ensemble de services pour la faible consommation, nommés Bluetooth LE (pour Low Energy). 6LoWPAN peut d'ailleurs en tirer profit (cf. RFC 7668).
IEEE 802.15.4 a aussi des solutions. Il permet par exemple d'avoir deux types de réseaux, avec ou sans annonces périodiques (beacons). Dans un réseau avec annonces, des machines nommés les coordinateurs envoient régulièrement des annonces qui indiquent quand on peut émettre et quand on ne peut pas, ces dernières périodes étant le bon moment pour s'endormir afin de diminuer la consommation : on est sûr de ne rien rater. Les durées de ces périodes sont configurables par l'administrateur réseaux. Dans les réseaux sans annonces, les différentes machines connectées n'ont pas d'informations et transmettent quand elles veulent, en suivant CSMA/CA.
Enfin, DECT a aussi un mode à basse consommation, DECT ULE. Elle est également utilisable avec 6LoWPAN (RFC 8105). DECT est très asymétrique, il y a le FP (Fixed Part, la base), et le PP (Portable Part, l'objet). DECT ULE permet au FP de prévenir quand il parlera (et le PP peut dormir jusque là). À noter que si la « sieste » est trop longue (plus de dix secondes), le PP devra refaire une séquence de synchronisation avec le FP, qui peut être coûteuse en énergie. Il faut donc bien calculer son coup : si on s'endort souvent pour des périodes d'un peu plus de dix secondes, le bilan global sera sans doute négatif.
La section 4 de notre RFC couvre justement ce que devrait faire IP, en supposant qu'on utilisera 6LoWPAN. Il y a trois services importants de 6LoWPAN pour la consommation électrique :
- 6LoWPAN a un mécanisme de fragmentation et de réassemblage. IPv6 impose que les liens aient une MTU d'au moins 1 280 octets. Si ce n'est pas le cas, il faut un mécanisme de fragmentation sous IP. Mais la fragmentation n'est pas gratuite et il vaut mieux que les applications s'abstiennent de faire des paquets trop gros (un cas que traite CoAP, dans le RFC 7959).
- 6LoWPAN sait que le processeur consomme moins d'énergie que la partie radio de l'objet connecté, et qu'il est donc rentable de faire des calculs qui diminuent la quantité de données à envoyer, notamment la compression. Par exemple, 6LoWPAN permet de diminuer sérieusement la taille de l'en-tête de paquet IPv6 (normalement 40 octets), en comptant sur le fait que les paquets successifs d'un même flot se ressemblent.
- 6LoWPAN a un mécanisme de découverte du voisin optimisé pour les réseaux contraints, nommé 6LoWPAN-ND.
Il y a aussi des optimisations qui ne changent pas le protocole. Par exemple, Contiki ne suit pas, dans sa mise en œuvre, une stricte séparation des couches, afin de pouvoir optimiser l'activité réseau.
De même, les protocoles de routage doivent tenir compte des contraintes de consommation électrique (section 5 du RFC). Le protocole « officiel » de l'IETF pour le routage dans les réseaux contraints est RPL (RFC 6550). L'étude Powertrace déjà citée étudie également la consommation de RPL et montre qu'il est en effet assez efficace, si le réseau est stable (s'il ne l'est pas, on consommera évidemment du courant à envoyer et recevoir les mises à jours des routes). On peut adapter les paramètres de RPL, via l'algorithme Trickle (RFC 6206, rien à voir avec le protocole de transfert de fichiers de BitNet), pour le rendre encore plus économe, mais au prix d'une convergence plus lente lorsque le réseau change.
À noter que le RFC ne parle que de RPL, et pas des autres protocoles de routage utilisables par les objets, comme Babel (RFC 8966).
Et les applications ? La section 6 du RFC leur donne du boulot, à elles aussi. Bien sûr, il est recommandé d'utiliser CoAP (RFC 7252) plutôt que HTTP, entre autre en raison de son en-tête plus court, et de taille fixe. D'autre part, CoAP a un mode de pure observation, où le client indique son intérêt pour certaines ressources, que le serveur lui enverra automatiquement par la suite, lorsqu'elles changeront, économisant ainsi une requête. Comme HTTP, CoAP peut utiliser des relais qui mémorisent la ressource demandée, ce qui permet de récupérer des ressources sans réveiller le serveur, si l'information était dans le cache. D'autres protocoles étaient à l'étude, reprenant les principes de CoAP, pour mieux gérer les serveurs endormis. (Mais la plupart de ces projets semblent… endormis à l'heure actuelle.)
Enfin, la section 7 de notre RFC résume les points importants :
- Il ne faut pas hésiter à violer le modèle en couches, en accédant à des informations des couches basses, elles peuvent sérieusement aider à faire des économies.
- Il faut comprimer.
- Il faut se méfier de la diffusion, qui consomme davantage.
- Et il faut s'endormir souvent, pour économiser l'énergie (la méthode Gaston Lagaffe, même si le RFC ne cite pas ce pionnier).
L'article seul
RFC 8360: Resource Public Key Infrastructure (RPKI) Validation Reconsidered
Date de publication du RFC : Avril 2018
Auteur(s) du RFC : G. Huston (APNIC), G. Michaelson
(APNIC), C. Martinez
(LACNIC), T. Bruijnzeels (RIPE
NCC), A. Newton (ARIN), D. Shaw
(AFRINIC)
Chemin des normes
Réalisé dans le cadre du groupe de travail IETF sidr
Première rédaction de cet article le 6 avril 2018
La RPKI est un ensemble de formats et de règles pour certifier qui est le titulaire d'une ressource Internet, une ressource étant un préfixe d'adresses IP, un numéro de système autonome, etc. La RPKI est utilisée dans les mécanismes de sécurisation de BGP, par exemple pour vérifier qu'un AS est bien autorisé à être à l'origine d'un préfixe donné. Les règles initiales de la RPKI pour valider un certificat était trop strictes et ce RFC les assouplit légèrement (normalement, en gardant le même niveau de sécurité).
La RPKI est normalisée dans le RFC 6480. Elle prévoit notamment un système de certificats par lequel une autorité affirme qu'une autorité de niveau inférieur a bien reçu une délégation pour un groupe de ressources Internet. (On appelle ces ressources les INR, pour Internet Number Resource.) La validation des certificats est décrite dans le RFC 6487. L'ancienne règle était que le certificat de l'autorité inférieure ne devait lister que des ressources qui étaient dans le certificat de l'autorité qui signait (RFC 6487, section 7.2, notamment la condition 6 de la seconde énumération). En pratique, cette règle s'est avérée trop rigide, et la nouvelle, décrite dans notre RFC 8360 est que le certificat de l'autorité inférieure n'est accepté que pour des ressources qui étaient dans le certificat de l'autorité qui signait. S'il y a d'autres ressources, le certificat n'est plus invalide, simplement, ces ressources sont ignorées. Dit autrement, l'ensemble des ressources dont la « possession » est certifiée, est l'intersection des ressources du certificat de l'autorité parente et de celui de l'autorité fille. Cette intersection se nomme VRS, pour Verified Resource Set.
Voici d'abord une chaîne de certificats qui était valide avec l'ancienne règle, et qui l'est toujours :
Certificate 1 (trust anchor):
Issuer TA,
Subject TA,
Resources 192.0.2.0/24, 198.51.100.0/24,
2001:db8::/32, AS64496-AS64500
Certificate 2:
Issuer TA,
Subject CA1,
Resources 192.0.2.0/24, 198.51.100.0/24, 2001:db8::/32
Certificate 3:
Issuer CA1,
Subject CA2,
Resources 192.0.2.0/24, 198.51.100.0/24, 2001:db8::/32
ROA 1:
Embedded Certificate 4 (EE certificate):
Issuer CA2,
Subject R1,
Resources 192.0.2.0/24
La chaîne part d'un certificat (TA, pour Trust Anchor, le point de départ de la validation). Elle aboutit à un ROA (Route Origin Authorization, cf. RFC 6482). Chaque certificat est valide puisque chacun certifie un jeu de ressources qui est un sous-ensemble du jeu de ressources de l'autorité du dessus. Idem pour le ROA.
Et voici par contre une chaîne de certificats qui était invalide selon les anciennes règles, et est désormais valide avec les règles de notre RFC 8360 :
Certificate 1 (trust anchor):
Issuer TA,
Subject TA,
Resources 192.0.2.0/24, 198.51.100.0/24,
2001:db8::/32, AS64496-AS64500
Certificate 2:
Issuer TA,
Subject CA1,
Resources 192.0.2.0/24, 2001:db8::/32
Certificate 3 (invalid before, now valid):
Issuer CA1,
Subject CA2,
Resources 192.0.2.0/24, 198.51.100.0/24, 2001:db8::/32
ROA 1 (invalid before, now valid):
Embedded Certificate 4 (EE certificate, invalid before, now valid):
Issuer CA2,
Subject R1,
Resources 192.0.2.0/24
La chaîne était invalide car le troisième certificat ajoutait
198.51.100.0/24, qui n'était pas couvert par
le certificat supérieur. Désormais, elle est valide mais vous
noterez que seuls les préfixes 192.0.2.0/24 et
2001:db8::/32 sont
couverts, comme précédemment (198.51.100.0/24
est ignoré). Avec les règles de notre nouveau RFC, le ROA final
est désormais valide (il n'utilise pas
198.51.100.0/24). Notez que les nouvelles
règles, comme les anciennes, n'autoriseront jamais l'acceptation
d'un ROA pour des ressources dont l'émetteur du certificat n'est
pas titulaire (c'est bien le but de la RPKI). Ce point est
important car l'idée derrière ce nouveau RFC de rendre plus
tolérante la validation n'est pas passée toute seule à l'IETF.
Un cas comme celui des deux chaînes ci-dessus est probablement rare. Mais il pourrait avoir des conséquences sérieuses si une ressource, par exemple un préfixe IP, était supprimée d'un préfixe situé très haut dans la hiérarchie : plein de certificats seraient alors invalidés avec les règles d'avant.
La section 4 de notre RFC détaille la procédure de validation. Les anciens certificats sont toujours validés avec
l'ancienne politique, celle du RFC 6487. Pour avoir la nouvelle politique, il faut de
nouveaux certificats, identifiés par un OID
différent. La section 1.2 du RFC 6484
définissait id-cp-ipAddr-asNumber / 1.3.6.1.5.5.7.14.2 comme OID pour
l'ancienne politique. La nouvelle politique est
id-cp-ipAddr-asNumber-v2 / 1.3.6.1.5.5.7.14.3 et c'est elle qui doit
être indiquée dans un certificat pour que lui soient appliquées
les nouvelles règles. (Ces OID sont dans un
registre IANA.) Comme les logiciels existants rejetteront
les certificats avec ces nouveaux OID, il faut adapter les
logiciels avant que les AC ne se mettent à
utiliser les nouveaux OID (cf. section 6 du RFC). Les changements
du RFC n'étant pas dans le protocole mais uniquement dans les
règles de validation, le déploiement devrait être relativement facile.
Le cœur des nouvelles règles est dans la
section 4.2.4.4 de notre RFC, qui remplace la section 7.2 du RFC 6487. Un nouveau concept est introduit, le
VRS (Verified Resource Set). C'est
l'intersection des ressources d'un certificat
et de son certificat supérieur. Dans le deuxième exemple plus
haut, le VRS du troisième certificat est
{192.0.2.0/24,
2001:db8::/32}, intersection de
{192.0.2.0/24,
2001:db8::/32} et
{192.0.2.0/24,
198.51.100.0/24,
2001:db8::/32}. Si le VRS est vide, le
certificat est invalide (mais on ne le rejette pas, cela peut être
un cas temporaire puisque la RPKI n'est pas cohérente en permanence).
Un ROA est valide si les ressources qu'il contient sont un sous-ensemble du VRS du certificat qui l'a signé (si, rappelons-le, ce certificat déclare la nouvelle politique). La règle exacte est un peu plus compliquée, je vous laisse lire le RFC pour les détails. Notez qu'il y a également des règles pour les AS, pas seulement pour les préfixes IP.
La section 5 du RFC contient davantage d'exemples, illustrant les nouvelles règles.
L'article seul
RFC 8354: Use Cases for IPv6 Source Packet Routing in Networking (SPRING)
Date de publication du RFC : Mars 2018
Auteur(s) du RFC : J. Brzozowski, J. Leddy
(Comcast), C. Filsfils, R. Maglione, M. Townsley
(Cisco)
Pour information
Réalisé dans le cadre du groupe de travail IETF spring
Première rédaction de cet article le 29 mars 2018
Le sigle SPRING signifie « Source Packet Routing In NetworkinG ». C'est quoi, le routage par la source (source routing) ? Normalement, la transmission de paquets IP se fait uniquement en fonction de l'adresse de destination, chaque routeur sur le trajet prenant sa décision indépendemment des autres, et sans que l'émetteur original du paquet n'ait son mot à dire. L'idée du routage par la source est de permettre à cet émetteur d'indiquer par où il souhaite que son paquet passe. L'idée est ancienne, et resurgit de temps en temps sur l'Internet. Ce nouveau RFC décrit les cas où une solution de routage par la source serait utile.
L'idée date des débuts de l'Internet. Par exemple, la norme IPv4, le RFC 791, spécifie, dans sa section 3.1, deux mécanismes de routage par la source, « Loose Source Routing » et « Strict Source Routing ». Mais ces mécanismes sont peu déployés et vous n'avez guère de chance, si vous mettez ces options dans un paquet IP, de voir un effet. En effet, le routage par la source est dangereux, il permet des attaques variées, et il complique beaucoup le travail des routeurs. Le but du projet SPRING, dont c'est le deuxième RFC, est de faire mieux. Le cahier des charges du projet est dans le RFC 7855.
L'architecture technique de SPRING est dans le RFC 8402. Ce segment routing est déjà mis en œuvre dans le noyau Linux depuis la version 4.14 (cf. le site du projet). Notre nouveau RFC 8354 ne contient, lui, que les scénarios d'usage. (Certains étaient déjà dans la section 3 du RFC 7855.) Seul IPv6 est pris en compte.
D'abord, le cas du SOHO connecté à
plusieurs fournisseurs
d'accès. Comme chacun de ces fournisseurs n'acceptera
que des paquets dont l'adresse IP source est dans un préfixe qu'il
a alloué au client, il est essentiel de pouvoir router en fonction
de la source, afin d'envoyer les paquets ayant une adresse source
du FAI A vers le FAI A et seulement celui-ci. Voici par exemple
comment faire sur Linux, quand on veut
envoyer les paquets ayant l'adresse IP source
2001:db8:dc2:45:216:3eff:fe4b:8c5b vers un
routeur différent de l'habituel (le RFC 3178
peut être une bonne lecture, quoique daté, notamment sa section 5) :
#!/bin/sh
DEVICE=eth1
SERVICE=2001:db8:dc2:45:216:3eff:fe4b:8c5b
TABLE=CustomTable
ROUTER=2001:db8:dc2:45:1
echo 200 ${TABLE} >> /etc/iproute2/rt_tables
ip -6 rule add from ${SERVICE} table ${TABLE}
ip -6 route add default via ${ROUTER} dev ${DEVICE} table ${TABLE}
ip -6 route flush cache
Notez que la décision correcte peut être prise par la machine terminale, comme dans l'exemple ci-dessus, ou bien par un routeur situé plus loin sur le trajet (dans le projet SPRING, la source n'est pas forcément la machine terminale initiale).
Outre le fait que le FAI B rejetterait probablement les paquets ayant une adresse source qui n'est pas à lui (RFC 3704), il peut y avoir d'autres raisons pour envoyer les paquets sur une interface de sortie particulière :
- Elle est plus rapide,
- Elle est moins chère (pensez à un réseau connecté en filaire mais également à un réseau mobile avec forfait « illimité » ce qui, en langage telco, veut dire ayant des limites),
- Dans le cas du télétravailleur, il peut être souhaitable de faire passer les paquets de la machine personnelle par un FAI payé par le télétravailleur et ceux de la machine de bureau par un FAI payé par l'employeur.
Autre cas où un routage par la source peut être utile, le FAI peut s'en servir pour servir certains utilisateurs ou certains usages dans des conditions différentes, par exemple avec des prix à la tête du client. Cela viole sans doute la neutralité du réseau mais c'est peut-être un scénario qui en tentera certains (sections 2.2 et 2.5 du RFC). Cela concerne le réseau d'accès (de M. Michu au FAI) et aussi le cœur de réseau ; « l'opérateur peut vouloir configurer un chemin spécial pour les applications sensibles à la latence ».
De plus haute technologie est le scénario présenté dans la section 2.3. Ici, il s'agit d'un centre de données entièrement IPv6. Cela simplifie considérablement la gestion du réseau, et cela permet d'avoir autant d'adresses qu'on veut, sans se soucier de la pénurie d'adresses IPv4. Certains opérateurs travaillent déjà à de telles configurations. Dans ce cas, le routage par la source serait un outil puissant pour, par exemple, isoler différents types de trafic et les acheminer sur des chemins spécifiques.
Si le routage par la source, une très vieille idée, n'a jamais vraiment pris, c'est en grande partie pour des raisons de sécurité. La section 4 rappelle les risques associés, qui avaient mené à l'abandon de la solution « Type 0 Routing Header » (cf. RFC 5095).
L'article seul
La vie privée à l'ère du RGPD
Première rédaction de cet article le 26 mars 2018
Dernière mise à jour le 22 août 2019
Samedi 24 mars 2018, aux JDLL (Journées du Logiciel Libre) à Lyon, j'ai fait un exposé sur la question de La vie privée sur l’Internet à l’ère du RGPD.
Je sais, le RGPD est un sujet à la mode. Mais ce n'est pas une raison pour ne pas en parler. Les supports de l'exposé :
- En version adaptée à la vue sur écran,
- En version adaptée à l'impression,
- Bien sûr le source,
- La vidéo capturée à cette occasion est sur PeerTube, la voici.
Et voici aussi des jolies photos de l'évènement.
L'article seul
Developing DNS-over-HTTPS clients and servers
First publication of this article on 23 March 2018
The weekend of 17-18 March 2018, I participated to the IETF 101 hackathon in London. The project was DoH, aka DNS-over-HTTPS, and the idea was to develop clients, servers, and to test that they interoperate.
DoH (
DNS-over-HTTPS) is
not yet published as a RFC. One of the goals
of IETF
hackathons is precisely to test
Internet-Drafts before they become RFC, to
be reasonably sure they are not wrong, too complicated, or
useless. DoH is developed in the DoH working
group and currently has one Internet-Draft, the
specification of DNS-over-HTTPS, draft-ietf-doh-dns-over-https. Why
creating DoH? DNS privacy is the main factor
behind this project. Issues with DNS privacy are documented in
RFC 7626. One of them is that traffic is sent in
clear and therefore can be read by any
sniffer. To prevent that, there is a
standard, in RFC 7858, to run DNS over
TLS, using a dedicated
port, 853. But this port may be easily
blocked by an hostile middlebox. The only
port which is always open is 443, because it's used by
HTTPS. Of course, DNS-over-TLS could use
port 443 but you may have DPI devices
checking that it is actually HTTPS running (yes, the trafic is
encrypted but think of things like TLS'
ALPN). And HTTPS gives us other things: proxies, caching, availability from
JavaScript code…
So, DNS-over-HTTPS. This technique allows a stub resolver to talk to a DNS resolver over a secure transport. Let's see if we can implement the draft and make this implementation work with other implementations. My personal idea was to modify the excellent getdns library to add DoH as a possible transport (DNS-over-TLS is already there). But it was too complicated for me and, moreover, Willem Toorop decided to refactor the code, to make easier to add new transports, so getdns was too "in flux" for me. (Willem worked on it during the hackathon.) Instead, I developed first a server in Python, then developed a client in Python to test my server, then tested them against other clients and servers, then developed a second client in C. Let's see the issues.
DoH requires (I know, the actual rules are more complicated
than a simple requirement) HTTP/2 (RFC 7540). One of
the reasons is that DNS requests can take a very variable
time. You don't want your requests for
datatracker.ietf.org to be delayed by a
previous request for
brokendomain.allserversdown.example, standing
in the queue. HTTP/2,
with its streams, allow requests to be run in parallel. But HTTP/2
is recent, and many libraries and servers don't support it yet,
specially on stable releases of operating systems. For the
Python server, I choose the Quart framework,
which relies itself on hyper, an
implementation of HTTP/2 in Python. Because these were recent
libraries, not always available as a package for
Ubuntu, I created a
LXC container with
the "unstable" (very recent) version of
Debian. I installed Quart with
pip, as well as dnspython. dnspython is required because
DoH uses the DNS wire format, a binary
format (other systems running DNS over HTTPS, not yet
standardized, use JSON). So, I needed to
pack DNS packets from data and to unpack them at the other end,
hence dnspython.
Like many HTTP development frameworks for Python, Quart allows you to define code to be run in response to some HTTP methods, for a given path in the URI. For instance:
@app.route('/hello')
async def hello():
return 'Hello\n'
The decorator
@app.route routes requests to
https://YOURDOMAIN/hello to the
hello routine, which executes asynchronously
(people used to Flask will recognize the
syntax; those who don't know Flask should learn it, in order to be
able to use Quart). More complicated:
@app.route('/dns', methods=['POST'])
async def index():
ct = request.headers.get('content-type')
if ct != "application/dns-udpwireformat":
abort(415)
data = await request.get_data()
r = bytes(data)
message = dns.message.from_wire(r)
# get the DNS response from the DNS message, see later…
return (response
{'Content-Type': 'application/dns-udpwireformat'})
Here, we handle only POST requests, we check the
Content-Type: HTTP header, we parse the body
of the request with dnspython
(dns.message.from_wire(…)) and we return a
response with the proper content type.
How do we get the answer to a specific DNS request? We simply give it to our local resolver, with dnspython:
resolver = "::1"
raw = dns.query.udp(message, resolver)
response = raw.to_wire()
The biggest goal of DoH is privacy, so we need to activate encryption:
tls_context = ssl.create_default_context(ssl.Purpose.CLIENT_AUTH) tls_context.options |= ssl.OP_NO_TLSv1 | ssl.OP_NO_TLSv1_1 | ssl.OP_NO_COMPRESSION tls_context.set_alpn_protocols(['h2', 'http/1.1']) app.run(host=bind, port=port, ssl=tls_context)
(We accept HTTP/1.1, also, because we're tolerant.)
To get a certificate (because,
unfortunately, few programs and libraries support
DANE), we use Let's
Encrypt. The server I wrote cannot handle the
ACME challenge. But one call to certbot
certonly, choosing the option "Spin up a temporary
webserver" (with my own server stopped, of course) was enough to get a nice certificate.
I then load it:
tls_context.load_cert_chain(certfile='le-cert.pem', keyfile='le-key.pem')
Putting every together, we have the complete code quart-doh.py
% ./quart-doh.py -c -r ::1
Obviously, this is not a successful hackathon if you don't discover at least one bug in the library. Note it was fixed by the author even before the end of the event.
Having a server is nice but there were not many DoH clients to test it (some were developed during the hackathon). I then developed a client in Python, still with dnspython for the DNS part, but using pycurl for HTTP/2. The DNS request is built from a name entered by the user (note that the DNS query type, here, is fixed and set to ANY):
message = dns.message.make_query(queryname, dns.rdatatype.ANY)
message.id = 0 # DoH requests that
We use pycurl to establish a HTTP/2 connection:
c = pycurl.Curl()
c.setopt(c.URL, url) # url is the URL of the DoH server
data = message.to_wire()
c.setopt(pycurl.POST, True)
c.setopt(pycurl.POSTFIELDS, data)
c.setopt(pycurl.HTTPHEADER, ["Content-type: application/dns-udpwireformat"])
c.setopt(c.WRITEDATA, buffer)
c.setopt(pycurl.HTTP_VERSION, pycurl.CURL_HTTP_VERSION_2)
c.perform()
The c.setopt(pycurl.HTTP_VERSION, where we
require HTTP/2, works only if the libcurl library used by
pycurl has been linked with the nghttp2 library. Otherwise, you
get a pycurl.error: (1, '') which is not very helpful (error 1 is CURL_UNSUPPORTED_PROTOCOL). Again, you need
recent versions of everything.
We then get the answer in the buffer
variable, we can parse it and do something with it:
body = buffer.getvalue()
response = dns.message.from_wire(body)
The complete code is doh-client.py
% ./doh-client.py https://dns.dnsoverhttps.net/dns-query gitlab.com
...
;ANSWER
gitlab.com. 300 IN A 52.167.219.168
...
I also developed a C client. Because parallel programming in C
is very difficult (unlike Go, where it is a
pleasure), I wanted an asynchronous HTTP/2 library, in order to
make it usable in the future in getdns, which is
asynchronous. I use nghttp2, already mentioned, and
getdns for the DNS packing and unpacking (parsing). The HTTP/2
code was shamelessly copied from a nghttp2 example, so let's focus
on the DNS part. getdns provides
getdns_convert_fqdn_to_dns_name to put names
in DNS wire format (if you don't know the DNS, remember the wire
format is different from the presentation format
www.foobar.example; for instance, the wire
format do not use dots) and routines like
getdns_dict_set_bindata to create getdns messages :
getdns_convert_fqdn_to_dns_name (session_data->qname, dns_name_wire_fmt);
getdns_dict_set_bindata (dict, "qname", *dns_name_wire_fmt);
getdns_dict_set_int (dict, "qtype", GETDNS_RRTYPE_A);
getdns_dict_set_dict (qdict, "question", dict);
getdns_dict_set_int (rdict, "rd", 1);
getdns_dict_set_dict (qdict, "header", rdict);
Yes, building getdns data structures is a pain. In the end, all
that was necessary was (as displayed by
getdns_pretty_print_dict(qdict)):
{
"header":
{
"rd": 1
},
"question":
{
"qname": <bindata for gitlab.com.>,
"qtype": GETDNS_RRTYPE_A
}
}
We then put it in DNS wire format with getdns_msg_dict2wire
(qdict, buffer, &size); and give it to nghttp2. At
this time, it works only for GET requests, there is something
wrong in the code I used for sending the body in POST requests.
When getting the answer, getdns allows us to search info with the JSON pointer (RFC 6901) syntax (getdns does not use JSON but the data model is the same):
getdns_dict_get_int (msg_dict, "/header/rcode", &this_error);
getdns_dict_get_bindata (msg_dict, "/answer/0/rdata/ipv4_address", &this_address_data);
char *this_address_str = getdns_display_ip_address (this_address_data);
fprintf (stdout, "The address is %s\n", this_address_str);
The complete code is doh-nghttp.c and can be used
this way:
% ./doh-nghttp https://dns.dnsoverhttps.net/dns-query gitlab.com The address is 52.167.219.168
The -v option will display a lot more details.
What were the lessons learned during the hackathon? I let you see that in the presentation I gave at the DoH working group afterwards. For the other code developed during the hackathon, see the notes taken during the hackathon.
Other reports:
- Sara Dickinson's synthesis at the end of the hackathon,
- Tony Finch's notes, day 1 and day 2.
Many thanks to Charles Eckel for organising this wonderful event, to the other people working on DoH at the same time, making this both a fun and useful experience, and to the authors of the very good libraries I used, Quart, nghttp2, getdns and pycurl.
L'article seul
RFC 8310: Usage Profiles for DNS over TLS and DNS over DTLS
Date de publication du RFC : Mars 2018
Auteur(s) du RFC : S. Dickinson (Sinodun), D. Gillmor (ACLU), T. Reddy (McAfee)
Chemin des normes
Réalisé dans le cadre du groupe de travail IETF dprive
Première rédaction de cet article le 22 mars 2018
Afin de mieux protéger la vie privée des utilisateurs du DNS, le RFC 7858 normalise comment faire du DNS sur TLS, le chiffrement empêchant la lecture des requêtes et réponses DNS. Mais le chiffrement sans authentification n'a qu'un intérêt limité. Notamment, il ne protège pas contre un attaquant actif, qui joue les hommes du milieu. Le RFC 7858 ne proposait qu'un seul mécanisme d'authentification, peu pratique, les clés publiques configurées statiquement dans le client DNS. Ce nouveau RFC décrit d'autres mécanismes d'authentification, classés selon deux profils, un Strict (sécurité maximum) et un Opportuniste (disponibilité maximum).
Le problème de la protection de la vie privée quand on utilise le DNS est décrit dans le RFC 7626. Les solutions, comme toujours quand il s'agit de vie privée, se répartissent en deux catégories, la minimisation des données (RFC 9156) et le chiffrement (RFC 7858 et RFC 8094). Le chiffrement protège bien contre un attaquant purement passif. Mais si celui qui veut écouter les échanges DNS est capable de lancer des attaques actives (ARP spoofing, par exemple), le chiffrement ne suffit pas, il faut le doubler d'une authentification du serveur. Par exemple, en mars 2014, en Turquie, l'attaquant (le gouvernement) a pu détourner le trafic avec Google Public DNS. Même si Google Public DNS avait permis le chiffrement, il n'aurait pas servi, lors de cette attaque active. Sans l'authentification, on risque de parler en chiffré… à l'attaquant.
Le problème de l'authentification, c'est que si elle échoue, que faut-il faire ? Renoncer à envoyer des requêtes DNS ? Cela revient à se couper d'Internet. Notre nouveau RFC, considérant qu'il n'y a pas une solution qui conviendra à tous les cas, propose deux profils :
- Le profil strict privilégie la confidentialité. Si on ne peut pas chiffrer et authentifier, on renonce.
- Le profil opportuniste privilégie le fonctionnement du DNS. Si on ne peut pas authentifier, tant pis, on chiffre sans authentifier, mais, au moins, on a du DNS.
Notez bien qu'un profil spécifie des propriétés, une fin et pas un moyen. Un profil est défini par ces propriétés, qu'on implémente ensuite avec des mécanismes, décrits en section 6. Le RFC 7858 spécifiait déjà, dans sa section 4.2, un mécanisme d'authentification, fondé sur la connaissance préalable, par le client DNS, de la clé publique du serveur (SPKI, pour Subject Public Key Info, une solution analogue à celle du RFC 7469 pour HTTP). Mais beaucoup de détails manquaient. Ce nouveau RFC 8310 :
- Décrit comment le client est censé obtenir les informations nécessaires à l'authentification,
- Quelles lettres de créance peut présenter le serveur pour s'authentifier,
- Et comment le client peut les vérifier.
À propos de ces « informations nécessaires à
l'authentification », il est temps d'introduire un acronyme
important (section 2 du RFC), ADN (Authentication
Domain Name), le nom du serveur qu'on veut
authentifier. Par exemple, pour Quad9,
ce sera dns.quad9.net. Autres termes
importants :
- Ensemble de clés (SPKI pinset), un ensemble de clés cryptographiques (ou plutôt de condensats de clés),
- Identificateur de référence (reference identifier), l'identificateur utilisé pour les vérifications (cf. RFC 6125).
- Lettres de créance (credentials), les informations du serveur qui lui servent à s'authentifier, certificat PKIX, enregistrement TLSA (RFC 6698) ou ensemble de clés.
Note importante, la section 3 du RFC pointe le fait que les
mécanismes d'authentification présentés ici ne traitent que
l'authentification d'un résolveur DNS par son
client. L'éventuelle future authentification d'un serveur faisant
autorité par le résolveur est hors-sujet, tout comme
l'authentification du client DNS par le serveur. Sont également
exclus les idées d'authentifier le nom de l'organisation qui gère
le serveur ou son pays : on authentifie uniquement l'ADN, « cette
machine est bien dns-resolver.yeti.eu.org »,
c'est tout.
La section 5 présente les deux profils normalisés. Un profil est une politique choisie par le client DNS, exprimant ses exigences, et les compromis qu'il est éventuellement prêt à accepter si nécessaire. Un profil n'est pas un mécanisme d'authentification, ceux-ci sont dans la section suivante, la section 6. La section 5 présente deux profils :
- Le profil strict, où le client exige chiffrement avec le serveur DNS et authentification du serveur. Si cela ne peut pas être fait, le profil strict renonce à utiliser le DNS, plutôt qu'à prendre des risques d'être surveillé. Le choix de ce profil protège à la fois contre les attaques passives et contre les attaques actives.
- Le profil opportuniste, où le client tente de chiffrer et d'authentifier, mais est prêt à continuer quand même si ça échoue (cf. RFC 7435, sur ce concept de sécurité opportuniste). Si le serveur DNS permet le chiffrement, l'utilisateur de ce profil est protégé contre une attaque passive, mais pas contre une attaque active. Si le serveur ne permet pas le chiffrement, l'utilisateur risque même de voir son trafic DNS passer en clair.
Les discussions à l'IETF (par exemple pendant la réunion de Séoul en novembre 2016) avaient été vives, notamment sur l'utilité d'avoir un profil strict, qui peut mener à ne plus avoir de résolution DNS du tout, ce qui n'encouragerait pas son usage.
Une petite nuance s'impose ici : pour les deux profils, il faudra, dans certains cas, effectuer une requête DNS au tout début pour trouver certaines informations nécessaires pour se connecter au serveur DNS (par exemple son adresse IP si on n'a que son nom). Cette « méta-requête » peut se faire en clair, et non protégée contre l'écoute, même dans le cas du profil strict. Autrement, le déploiement de ce profil serait très difficile (il faudrait avoir toutes les informations stockées en dur dans le client).
Le profil strict peut être complètement inutilisable si les requêtes DNS sont interceptées et redirigées, par exemple dans le cas d'un portail captif. Dans ce cas, la seule solution est d'avoir un mode « connexion » pendant lequel on n'essaie pas de protéger la confidentialité des requêtes DNS, le temps de passer le portail captif, avant de passer en mode « accès Internet ». C'est ce que fait DNSSEC-trigger (cf. section 6.6).
Le tableau 1 du RFC résume les possibilités de ces deux profils, face à un attaquant actif et à un passif. Dans tous les cas, le profil strict donnera une connexion DNS chiffrée et authentifiée, ou bien pas de connexion du tout. Dans le meilleur cas, le profil opportuniste donnera la même chose que le strict (connexion chiffrée et authentifiée). Si le serveur est mal configuré ou si le client n'a pas les informations nécessaires pour authentifier, ou encore si un Homme du Milieu intervient, la session ne sera que chiffrée, et, dans le pire des cas, le profil opportuniste donnera une connexion en clair. On aurait pu envisager d'autres profils (par exemple un qui impose le chiffrement, mais pas l'authentification) mais le groupe de travail à l'IETF a estimé qu'ils n'auraient pas eu un grand intérêt, pour la complexité qu'ils auraient apporté.
Un mot sur la détection des problèmes. Le profil opportuniste peut permettre la détection d'un problème, même si le client continue ensuite malgré les risques. Par exemple, si un résolveur DNS acceptait DNS-sur-TLS avant, que le client avait enregistré cette information, mais que, ce matin, les connexions vers le port 853 sont refusées, avec le profil opportuniste, le client va quand même continuer sur le port 53 (en clair, donc) mais peut noter qu'il y a un problème. Il peut même (mais ce n'est pas une obligation) prévenir l'utilisateur. Cette possibilité de détection est le « D » dans le tableau 1, et est détaillée dans la section 6.5. La détection permet d'éventuellement prévenir l'utilisateur d'une attaque potentielle, mais elle est aussi utile pour le débogage.
Évidemment, seul le profil strict protège réellement l'utilisateur contre l'écoute et toute mise en œuvre de DNS-sur-TLS devrait donc permettre au moins ce profil. Le profil opportuniste est là par réalisme : parfois, il vaut mieux une connexion DNS écoutée que pas de DNS du tout.
Les deux profils vont nécessiter un peu de configuration (le nom ou l'adresse du résolveur) mais le profil strict en nécessite davantage (par exemple la clé du résolveur).
Maintenant qu'on a bien décrit les profils, quels sont les mécanismes d'authentification disponibles ? La section 6 les décrit rapidement, et le tableau 2 les résume, il y en a six en tout, caractérisés par l'information de configuration nécessaire côté client (ils seront détaillés en section 8) :
- Adresse IP du résolveur + clé du résolveur (SPKI, Subject Public Key Info). C'est celui qui était présenté dans la section 4.2 du RFC 7858, et qui est illustré dans mon article sur la supervision de résolveurs DNS-sur-TLS. Ce mécanisme est pénible à gérer (il faut par exemple tenir compte des éventuels changements de clé) mais c'est celui qui minimise la fuite d'information : l'éventuel surveillant n'apprendra que l'ADN (dans le SNI de la connexion TLS). En prime, il permet d'utiliser les clés nues du RFC 7250 (cf. section 9 du RFC).
- ADN (nom de domaine du résolveur DNS-sur-TLS) et adresse
IP du résolveur. On peut alors authentifier avec le
certificat PKIX, comme on le fait souvent avec TLS (cf. section 8
du RFC, RFC 5280 et RFC 6125). L'identificateur à vérifier est l'ADN, qui
doit se trouver dans le certificat, comme
subjectAltName. - ADN seul. La configuration est plus simple et plus stable mais les méta-requêtes (obtenir l'adresse IP du résolveur à partir de son ADN) ne sont pas protégées et peuvent être écoutées. Si on n'utilise pas DNSSEC, on peut même se faire détourner vers un faux serveur (la vérification du certificat le détecterait, si on pouvait faire confiance à toutes les AC situées dans le magasin).
- DHCP. Aucune configuration (c'est bien le but de DHCP) mais deux problèmes bloquants : il n'existe actuellement pas d'option DHCP pour transmettre cette information (même pas de projet) et DHCP lui-même n'est pas sûr.
- DANE (RFC 6698). On peut authentifier le certificat du résolveur, non pas
avec le fragile système des AC
X.509, mais avec DANE. L'enregistrement
TLSA devra être en
_853._tcp.ADN. Cela nécessite un client capable de faire de la validation DNSSEC (à l'heure actuelle, le résolveur sur la machine cliente est en général un logiciel minimal, incapable de valider). Et les requêtes DANE (demande de l'enregistrement TLSA) peuvent passer en clair. - DANE avec une extension TLS. Cette extension (RFC 9102) permet au serveur DNS-sur-TLS d'envoyer les enregistrements DNS et DNSSEC dans la session TLS elle-même. Plus besoin de méta-requêtes et donc plus de fuites d'information.
Cela fait beaucoup de mécanismes d'authentification ! Comment se combinent-ils ? Lesquels essayer et que faire s'ils donnent des résultats différents ? La méthode recommandée, si on a un ADN et une clé, est de tester les deux et d'exiger que les deux fonctionnent.
On a parlé à plusieurs reprises de l'ADN
(Authentication Domain Name). Mais comment
on obtient son ADN ? La section 7 du RFC détaille les sources
d'ADN. La première est évidemment le cas où l'ADN est
configuré manuellement. On pourrait imaginer, sur
Unix, un
/etc/resolv.conf avec une nouvelle
syntaxe :
nameserver 2001:db8:53::1 adn resolver.example.net
Ici, on a configuré manuellement l'adresse IP et le nom
(l'ADN) du résolveur. Cela convient au cas de résolveurs
publics comme Quad9. Mais on pourrait imaginer des cas où seul
l'ADN serait configuré quelque part, le résolveur dans
/etc/resolv.conf étant rempli par
DHCP, et n'étant utilisé que pour
les méta-requêtes. Par exemple un (mythique, pour l'instant) /etc/tls-resolver.conf :
adn resolver.example.net # IP address will be found via the "DHCP" DNS resolver, and checked # with DNSSEC and/or TLS authentication
Troisième possibilité, l'ADN et l'adresse IP pourraient être découverts dynamiquement. Il n'existe à l'heure actuelle aucune méthode normalisée pour cela. Si on veut utiliser le profil strict, cette future méthode normalisée devra être raisonnablement sécurisée, ce qui n'est typiquement pas le cas de DHCP. On peut toujours normaliser une nouvelle option DHCP pour indiquer l'ADN mais elle ne serait, dans l'état actuel des choses, utilisable qu'avec le profil opportuniste. Bon, si vous voulez vous lancer dans ce travail, lisez bien la section 8 du RFC 7227 et la section 22 du RFC 8415 avant.
La section 11 du RFC décrit les mesures à mettre en œuvre contre deux attaques qui pourraient affaiblir la confidentialité, même si on chiffre. La première est l'analyse des tailles des requêtes et des réponses. L'accès au DNS étant public, un espion peut facilement récolter l'information sur la taille des réponses et, puisque TLS ne fait rien pour dissimuler cette taille, déduire les questions à partir des tailles. La solution recommandée contre l'attaque est le remplissage, décrit dans le RFC 7830.
Seconde attaque possible, un résolveur peut inclure l'adresse IP de son client dans ses requêtes au serveur faisant autorité (RFC 7871). Cela ne révèle pas le contenu des requêtes et des réponses, mais c'est quand même dommage pour la vie privée. Le client DNS-sur-TLS doit donc penser à mettre l'option indiquant qu'il ne veut pas qu'on fasse cela (RFC 7871, section 7.1.2).
Enfin, l'annexe A de notre RFC rappelle les dures réalités de l'Internet d'aujourd'hui : même si votre résolveur favori permet DNS-sur-TLS (c'est le cas par exemple de Quad9), le port 853 peut être bloqué par un pare-feu fasciste. Le client DNS-sur-TLS a donc intérêt à mémoriser quels résolveurs permettent DNS-sur-TLS, et depuis quels réseaux.
Pour l'instant, les nouveaux mécanismes d'authentification, et la possibilité de configurer le profil souhaité, ne semblent pas encore présents dans les logiciels, il va falloir patienter (ou programmer soi-même).
Merci à Willem Toorop pour son aide.
L'article seul
RFC 8336: The ORIGIN HTTP/2 Frame
Date de publication du RFC : Mars 2018
Auteur(s) du RFC : M. Nottingham, E. Nygren
(Akamai)
Chemin des normes
Réalisé dans le cadre du groupe de travail IETF httpbis
Première rédaction de cet article le 22 mars 2018
Le concept d'origine est crucial pour la
sécurité de HTTP. L'idée est d'empêcher du
contenu actif (code JavaScript, par
exemple) d'interagir avec des serveurs autres que ceux de
l'origine, de l'endroit où on a chargé ce contenu actif. Dans la
version 1 de HTTP, cela ne posait pas (trop) de problèmes. Mais la
version 2 de HTTP permet d'avoir, dans une même connexion HTTP
vers un serveur donné, accès à des ressources d'origines
différentes (par exemple parce qu'hébergées sur des
Virtual Hosts
différents). Ce nouveau RFC ajoute donc au protocole HTTP/2 un
nouveau type de trame, ORIGIN, qui permet de
spécifier les origines utilisées dans une connexion.
L'origine est un concept ancien, mais sa description formelle n'est venue au'avec le RFC 6454, dont la lecture est fortement recommandée, avant de lire ce nouveau RFC 8336. Son application à HTTP/2, normalisé dans le RFC 7540, a posé quelques problèmes (sections 9.1.1 et 9.1.2 du RFC 7540). En effet, avec HTTP/2, des origines différentes peuvent coexister sur la même connexion HTTP. Si le serveur ne peut pas produire une réponse, par exemple parce qu'il sépare le traitement des requêtes entre des machines différentes, il va envoyer un code de retour 421, indiquant à un client HTTP de re-tenter, avec une connexion différente. Pour lui faire gagner du temps, notre nouveau RFC 8336 va indiquer préalablement les origines acceptables sur cette connexion. Le client n'aura donc pas à essayer, il saura d'avance si ça marchera ou pas. Cette méthode évite également au client HTTP de se faire des nœuds au cerveau pour déterminer si une requête pour une origine différente a des chances de réussir ou pas, processus compliqué, et qui ne marche pas toujours.
Ce n'est pas clair ? Voici un exemple concret. Le client, un
navigateur Web,
vient de démarrer et on lui demande de se connecter à
https://www.toto.example/. Il établit une
connexion TCP, puis lance
TLS, et enfin fait du HTTP/2. Dans la phase
d'établissement de la connexion TLS, il a récupéré un
certificat qui liste des noms possibles
(subjectAltName),
www.toto.example mais aussi
foobar.example. Et, justement, quelques
secondes plus tard, l'utilisateur demande à visiter
https://foobar.example/ToU/TLDR/. Un point
central de HTTP/2 est la réutilisation des connexions, pour
diminuer la latence, due entre autres
à l'établissement de connexion, qui peut être
long avec TCP et, surtout TLS. Notre navigateur va donc se dire
« chic, je garde la même connexion puisque c'est la même
adresse IP et que ce serveur m'a dit
qu'il gérait aussi foobar.example, c'était
dans son certificat » (et la section 9.1.1 du RFC 7540 le lui permet explicitement). Mais patatras,
l'adresse IP est en fait celle d'un répartiteur de
charge qui envoie les requêtes pour
www.toto.example et
foobar.example à des machines différentes. La
machine qui gère foobar.example va alors
renvoyer 421 Misdirected Request au navigateur
qui sera fort marri, et aura perdu du temps pour rien. Alors
qu'avec la trame ORIGIN de notre RFC 8336, le serveur de
www.toto.example aurait dès le début envoyé
une trame ORIGIN disant « sur cette
connexion, c'est www.toto.example et rien
d'autre ». Le navigateur aurait alors été prévenu.
La section 2 du RFC décrit en détail ce nouveau type de trame
(RFC 7540, section 4, pour le concept de
trame). Le type de la trame est 12 (cf. le registre des types), et elle contient une liste
d'origines, chacune sous forme d'un doublet longueur-valeur. Une
origine est identifiée par un nom de
domaine (RFC 6454, sections 3 et
8). Il n'y a pas de limite de taille à la liste, programmeurs,
faites attention aux débordements de
tableau. Un nom de la liste ne peut pas inclure de jokers (donc, pas d'origine
*.example.com, donc attention si vous avez
des certificats utilisant des jokers). Ce type de trames doit être envoyée sur le ruisseau HTTP/2 de
numéro 0 (celui
de contrôle).
Comme toutes les trames d'un type inconnu du récepteur, elles
sont ignorées par le destinataire. Donc, en pratique, le serveur
peut envoyer ces trames sans inquiétude, le client HTTP trop
vieux pour les connaitre les ignorera. Ces trames
ORIGIN n'ont de sens qu'en cas de liaison
directe, les relais
doivent les ignorer, et ne pas les transmettre.
Au démarrage, le client HTTP/2 a un jeu d'origines qui est
déterminé par les anciennes règles (section 9.1.1 du RFC 7540). S'il reçoit une trame
ORIGIN, celle-ci remplace complètement ce
jeu, sauf pour la première origine vue (le serveur auquel on s'est
connecté, identifié par son adresse IP et, si on utilise
HTTPS, par le nom indiqué dans l'extension
TLS SNI, cf. RFC 6066) qui, elle, reste
toujours en place. Ensuite, les
éventuelles réponses 421 (Misdirected request)
supprimeront des entrées du jeu d'origines.
Notez bien que la trame ORIGIN ne fait
qu'indiquer qu'on peut utiliser cette connexion HTTP/2 pour cette
origine. Elle n'authentifie pas le serveur. Pour cela, il faut
toujours compter sur le certificat
(cf. section 4 du RFC).
En parlant de sécurité, notez que le RFC 7540, section
9.1.1 obligeait le client HTTP/2 à vérifier le
DNS et le nom dans le
certificat, avant d'ajouter une origine. Notre nouveau RFC est
plus laxiste, on ne vérifie que le certificat quand on reçoit une
nouvelle origine dans une trame ORIGIN
envoyée sur HTTPS (cela avait suscité des réactions diverses lors
de la discussion à l'IETF). Cela veut dire qu'un méchant qui a pu avoir un
certificat valable pour un nom, via une des nombreuses
AC du magasin, n'a plus besoin de faire une
attaque de l'Homme du Milieu (avec, par
exemple, un détournement DNS). Il lui
suffit, lorsqu'un autre nom qu'il contrôle est visité, d'envoyer
une trame ORIGIN et de présenter le
certificat. Pour éviter cela, le RFC conseille au client de
vérifier le certificat plus soigneusement, par exemple avec les
journaux publics du RFC 6962, ou bien avec
une réponse OCSP (RFC 6960 montrant que le certificat n'a pas été révoqué, en
espérant qu'un certificat « pirate » sera détecté et révoqué…)
Les développeurs regarderont avec intérêt l'annexe B, qui donne
des conseils pratiques. Par exemple, si un serveur a une très
longue liste d'origines possibles, il n'est pas forcément bon de
l'envoyer dès le début de la connexion, au moment où la latence
est critique. Il vaut mieux envoyer une liste réduite, et attendre
un moment où la connexion est tranquille pour envoyer la liste
complète. (La liste des origines, dans une trame
ORIGIN, ne s'ajoute pas aux origines
précédentes, elle les remplace. Pour retirer une origine, on
envoie une nouvelle liste, sans cette origine, ou bien on compte
sur les 421. Ce point avait
suscité beaucoup de discussions au sein du groupe de travail.)
Pour l'instant, la gestion de ce nouveau type de trames ne semble se trouver que dans Firefox, et n'est dans aucun serveur, mais des programmeurs ont annoncé qu'ils allaient s'y mettre.
L'article seul
RFC 8332: Use of RSA Keys with SHA-256 and SHA-512 in the Secure Shell (SSH) Protocol
Date de publication du RFC : Mars 2018
Auteur(s) du RFC : D. Bider (Bitvise)
Chemin des normes
Réalisé dans le cadre du groupe de travail IETF curdle
Première rédaction de cet article le 21 mars 2018
Les RFC normalisant le protocole SSH mentionnaient la possibilité pour le serveur d'avoir une clé publique RSA, mais uniquement avec l'algorithme de condensation SHA-1. Celui-ci a subi plusieurs attaques et n'est plus du tout conseillé aujourd'hui. Ce nouveau RFC est la description officielle de l'utilisation de RSA avec SHA-2 dans SSH.
Le RFC officiel du protocole
SSH, le RFC 4253,
définit l'algorithme ssh-rsa comme utilisant
the SHA-1 hash pour la signature et la vérification. Ce n'est plus cohérent avec ce
qu'on sait aujourd'hui des faiblesses de
SHA-1. Par exemple, le NIST
(dont les règles s'imposent aux organismes gouvernementaux
états-uniens), interdit
SHA-1 (voir aussi la section 5.1 du RFC).
(Petit point au passage, dans SSH, le format de la clé ne
désigne que la clé elle-même, alors que l'algorithme désigne un
format de clé et des procédures de signature et de vérification,
qui impliquent un algorithme de
condensation. Ainsi, ssh-keygen
-t rsa va générer une clé RSA, indépendamment de
l'algorithme qui sera utilisé lors d'une session SSH. Le registre IANA indique désormais séparement le
format et l'algorithme.)
Notre nouveau RFC définit donc deux nouveaux algorithmes :
rsa-sha2-256, qui utilise SHA-256 pour la condensation, et dont la mise en œuvre est recommandée pour tout programme ayant SSH,- et
rsa-sha2-512, qui utilise SHA-512 et dont la mise en œuvre est facultative.
Les deux algorithmes sont maintenant dans le
registre IANA. Le format, lui, ne change pas, et est toujours qualifié de
ssh-rsa (RFC 4253,
section 3.) Il n'est donc pas nécessaire de
changer ses clés RSA. (Si vous utilisez RSA : SSH permet d'autres
algorithmes de cryptographie
asymétrique, voir également la section 5.1 du RFC.)
Les deux « nouveaux » (ils sont déjà présents dans plusieurs
programmes SSH) algorithmes peuvent être utilisés aussi bien pour
l'authentification du client que pour celle du serveur. Ici, par
exemple, un serveur OpenSSH version 7.6p1
annonce les algorithme qu'il connait (section 3.1 de notre RFC), affichés par un client
OpenSSH utilisant l'option -v :
debug1: kex_input_ext_info: server-sig-algs=<ssh-ed25519,ssh-rsa,rsa-sha2-256,rsa-sha2-512,ssh-dss,ecdsa-sha2-nistp256,ecdsa-sha2-nistp384,ecdsa-sha2-nistp521>
On y voit la présence des deux nouveaux
algorithmes. ssh-rsa est celui du RFC 4253, avec SHA-1 (non explicitement indiqué).
En parlant d'OpenSSH, la version 7.2
avait une bogue (corrigée en 7.2p2), qui faisait que la signature
était étiquetée ssh-rsa quand elle aurait dû
l'être avec rsa-sha2-256 ou
rsa-sha2-512. Pour compenser cette bogue, le
RFC autorise les programmes à accepter ces signatures quand même.
Autre petit piège pratique (et qui a suscité les discussions
les plus vives dans le groupe de travail), certains serveurs SSH « punissent »
les clients qui essaient de s'authentifier avec des algorithmes que le serveur ne sait
pas gèrer, pour diminuer l'efficacité d'éventuelles
attaques par repli. Pour éviter d'être
pénalisé (serveur qui raccroche brutalement, voire qui vous met en
liste noire), le RFC recommande que les serveurs déploient
le protocole qui permet de négocier des extensions,
protocole normalisé dans le RFC 8308. (L'extension intéressante est server-sig-algs.) Le
client prudent peut éviter d'essayer les nouveaux
algorithmes utilisant SHA-2, si le serveur n'annonce pas cette
extension. L'ancien algorithme, utilisant SHA-1, devrait
normalement être abandonné au fur et à mesure que tout le monde migre.
Les nouveaux algorithmes de ce RFC sont présents dans :
Vous pouvez aussi regarder le
tableau de comparaison des versions de SSH. Voici encore un
ssh -v vers un serveur dont la clé de machine
est RSA et qui utilise l'algorithme RSA-avec-SHA512 :
... debug1: kex: host key algorithm: rsa-sha2-512 ... debug1: Server host key: ssh-rsa SHA256:yiol3GPr1dgVo/SNXPvtFqftLw4UF+nL+ECa1yXAtG0 ...
Par comparaison avec les SSH récents, voici un ssh -v
OpenSSH vers un serveur un peu vieux :
debug1: kex_input_ext_info: server-sig-algs=<ssh-ed25519,ssh-rsa,ssh-dss,ecdsa-sha2-nistp256,ecdsa-sha2-nistp384,ecdsa-sha2-nistp521>
On voit que les nouveaux algorithmes manquent (pour RSA ; SHA-2 est utilisable pour ECDSA). Et pour sa clé de machine :
... debug1: kex: host key algorithm: ssh-rsa ... debug1: Server host key: ssh-rsa SHA256:a6cLkwFRGuEorbmN0oRjvKrXELhIVXdgHRCcbQOM2w8
Le serveur utilise le vieil algorithme,
ssh-rsa, ce qui veut dire SHA-1 (le
SHA256 qui apparait a été généré par le client).
L'article seul
RFC 8308: Extension Negotiation in the Secure Shell (SSH) Protocol
Date de publication du RFC : Mars 2018
Auteur(s) du RFC : D. Bider (Bitvise Limited)
Chemin des normes
Réalisé dans le cadre du groupe de travail IETF curdle
Première rédaction de cet article le 21 mars 2018
Dernière mise à jour le 28 mars 2018
Le protocole SSH n'avait pas de mécanisme propre pour négocier des extensions au protocole de base (comme celle du RFC 4335). En outre, une partie de la négociation, par exemple des algorithmes cryptographiques, se déroulait avant le début du chiffrement et n'était donc pas protégée. Ce nouveau RFC ajoute à SSH un mécanisme pour négocier les extensions après l'échange de clés et le début de la communication sécurisée, une fois que tout est confidentiel.
Un mécanisme de négociation pour un protocole cryptographique est toujours délicat (comme TLS s'en est aperçu à plusieurs reprises). Si on n'en a pas, le client et le serveur perdent beaucoup de temps à faire des essais/erreurs « tiens, il vient de déconnecter brusquement, c'est peut-être qu'il n'aime pas SHA-512, réessayons avec SHA-1 ». Et ces deux mécanismes (négociation explicite et essai/erreur) ouvrent une nouvelle voie d'attaque, celle des attaques par repli, où l'Homme du Milieu va essayer de forcer les deux parties à utiliser des algorithmes de qualité inférieure. (La seule protection serait de ne pas discuter, de choisir des algorithmes forts et de refuser tout repli. En sécurité, ça peut aider d'être obtus.)
Notez aussi que la méthode essais/erreurs a un danger spécifique, car bien des machines SSH mettent en œuvre des mécanismes de limitation du trafic, voire de mise en liste noire, si la machine en face fait trop d'essais, ceci afin d'empêcher des attaques par force brute. D'où l'intérêt d'un vrai mécanisme de négociation (qui peut en outre permettre de détecter certaines manipulations par l'Homme du Milieu).
Vue par tshark, voici
le début d'une négociation SSH, le message
SSH_MSG_KEXINIT, normalisé dans le RFC 4253, section 7.1 :
SSH Protocol
SSH Version 2
Packet Length: 1332
Padding Length: 5
Key Exchange
Message Code: Key Exchange Init (20)
Algorithms
Cookie: 139228cb5cfbf6c97d6b74f6ae99453d
kex_algorithms length: 196
kex_algorithms string: curve25519-sha256@libssh.org,ecdh-sha2-nistp256,ecdh-sha2-nistp384,ecdh-sha2-nistp521,diffie-hellman-group-exchange-sha256,diffie-hellman-group-exchange-sha1,diffie-hellman-group14-sha1,ext-info-c
server_host_key_algorithms length: 290
server_host_key_algorithms string [truncated]: ecdsa-sha2-nistp256-cert-v01@openssh.com,ecdsa-sha2-nistp384-cert-v01@openssh.com,ecdsa-sha2-nistp521-cert-v01@openssh.com,ssh-ed25519-cert-v01@openssh.com,ssh-rsa-cert-v01@openssh.com,ecdsa-s
encryption_algorithms_client_to_server length: 150
encryption_algorithms_client_to_server string: chacha20-poly1305@openssh.com,aes128-ctr,aes192-ctr,aes256-ctr,aes128-gcm@openssh.com,aes256-gcm@openssh.com,aes128-cbc,aes192-cbc,aes256-cbc,3des-cbc
encryption_algorithms_server_to_client length: 150
encryption_algorithms_server_to_client string: chacha20-poly1305@openssh.com,aes128-ctr,aes192-ctr,aes256-ctr,aes128-gcm@openssh.com,aes256-gcm@openssh.com,aes128-cbc,aes192-cbc,aes256-cbc,3des-cbc
mac_algorithms_client_to_server length: 213
mac_algorithms_client_to_server string [truncated]: umac-64-etm@openssh.com,umac-128-etm@openssh.com,hmac-sha2-256-etm@openssh.com,hmac-sha2-512-etm@openssh.com,hmac-sha1-etm@openssh.com,umac-64@openssh.com,umac-128@openssh.com,hmac-sha2-2
mac_algorithms_server_to_client length: 213
mac_algorithms_server_to_client string [truncated]: umac-64-etm@openssh.com,umac-128-etm@openssh.com,hmac-sha2-256-etm@openssh.com,hmac-sha2-512-etm@openssh.com,hmac-sha1-etm@openssh.com,umac-64@openssh.com,umac-128@openssh.com,hmac-sha2-2
compression_algorithms_client_to_server length: 26
compression_algorithms_client_to_server string: none,zlib@openssh.com,zlib
compression_algorithms_server_to_client length: 26
compression_algorithms_server_to_client string: none,zlib@openssh.com,zlib
languages_client_to_server length: 0
languages_client_to_server string: [Empty]
languages_server_to_client length: 0
languages_server_to_client string: [Empty]
KEX First Packet Follows: 0
Reserved: 00000000
Padding String: 0000000000
Le message était en clair (c'est pour cela que tshark a pu le décoder). L'autre machine envoie un message équivalent. Suite à cet échange, les deux machines sauront quels algorithmes sont disponibles.
Notre RFC 8308 (section 2.1) ajoute à ce message le nouveau
mécanisme d'extension. Pour préserver la compatibilité avec les
anciennes mises en œuvre de SSH, et comme il n'y a pas de place
« propre » disponible dans le message, le nouveau mécanisme se
place dans la liste des algorithmes cryptographiques (champ
kex_algorithms, celui qui commence par
curve25519-sha256@libssh.org,ecdh-sha2-nistp256…). On
ajoute à cette liste ext-info-c si on est
client et ext-info-s si on est serveur. (Le
nom est différent dans chaque direction, pour éviter que les deux
parties ne se disent « cool, cet algorithme est commun,
utilisons-le ».) Vous
pouvez donc savoir si votre SSH gère le nouveau mécanisme en
capturant ce premier paquet SSH et en examinant la liste des
algorithmes d'échange de clé. (C'était le cas ici, avec
OpenSSH 7.2. Vous l'aviez repéré ?)
Une fois qu'on a proposé à son pair d'utiliser le nouveau
mécanisme de ce RFC 8308, on peut s'attendre, si le pair
est d'accord, à recevoir un message SSH d'un nouveau type,
SSH_MSG_EXT_INFO, qui sera, lui, chiffré. Il contient la liste des
extensions gérées avec ce mécanisme. Notez qu'il peut être envoyé
plusieurs fois, par exemple avant et après l'authentification du
client, pour le cas d'un serveur timide qui ne voulait pas révéler
sa liste d'extensions avant l'authentification. Ce nouveau type de
message figure désormais dans le
registre des types de message, avec le numéro 7.
La section 3 définit les quatre extensions actuelles (un registre accueillera les extensions futures) :
- L'extension
server-sig-algsdonne la liste des algorithmes de signature acceptés par le serveur. delay-compressionindique les algorithmes de compression acceptés. Il y en a deux, un du client vers le serveur et un en sens inverse. Ils étaient déjà indiqués dans le messageSSH_MSG_KEXINIT, dans les champscompression_algorithms_client_to_serveretcompression_algorithms_server_to_clientmais, cette fois, ils sont transmis dans un canal sécurisé (confidentiel et authentifié).no-flow-control, dont le nom indique bien la fonction.elevationsert aux systèmes d'exploitation qui ont un mécanisme d'élévation des privilèges (c'est le cas de Windows, comme documenté dans le blog de Microsoft).
Les futures extensions, après ces quatre-là, nécessiteront un examen par l'IETF, via un RFC IETF (cf. RFC 8126, politique « IETF review »). Elle seront placées dans le registre des extensions.
Quelques petits problèmes de déploiement et d'incompatibilité
ont été notés avec ce nouveau
mécanisme d'extensions. Par exemple OpenSSH 7.3 et 7.4 gérait
l'extension server-sig-algs mais n'envoyait
pas la liste complète des algorithmes acceptés. Un client qui
considérait cette liste comme ferme et définitive pouvait donc
renoncer à utiliser certains algorithmes qui auraient pourtant
marché. Voir ce
message pour une explication détaillée.
Autre gag, les valeurs des extensions peuvent contenir des octets nuls et un logiciel maladroit qui les lirait comme si c'était des chaînes de caractères en C aurait des problèmes. C'est justement ce qui est arrivé à OpenSSH, jusqu'à la version 7.5 incluse, ce qui cassait brutalement la connexion. Le RFC conseille de tester la version du pair, et de ne pas utiliser les extensions en cause si on parle à un OpenSSH ≤ 7.5.
Aujourd'hui, ce mécanisme d'extension est mis en œuvre dans OpenSSH, Bitvise SSH, AsyncSSH et SmartFTP. (Cf. ce tableau de comparaison, mais qui n'est pas forcément à jour.)
Merci à Manuel Pégourié-Gonnard pour avoir détecté une erreur dans la première version.
L'article seul
RFC 8358: Update to Digital Signatures on Internet-Draft Documents
Date de publication du RFC : Mars 2018
Auteur(s) du RFC : R. Housley (Vigil Security)
Pour information
Première rédaction de cet article le 13 mars 2018
Dernière mise à jour le 5 avril 2018
Les Internet-Drafts sont signés suivant les règles du RFC 5485, afin qu'une lectrice ou un lecteur puissent vérifier qu'un Internet-Draft n'a pas été modifié en cours de route. Ce nouveau RFC modifie légèrement le RFC 5485 sur un seul point : la signature d'Internet-Drafts qui sont écrits en Unicode.
En effet, depuis le RFC 7997, les RFC ne sont plus forcément en ASCII, ils peuvent intégrer des caractères Unicode. Le premier RFC publié avec ces caractères a été le RFC 8187, en septembre 2017. Bientôt, cela sera également possible pour les Internet-Drafts. Cela affecte forcément les règles de signature, d'où cette légère mise à jour.
Le RFC 5485 normalisait l'utilisation de CMS (RFC 5652) pour le format des signatures. Vous pouvez télécharger ces signatures sur n'importe lequel des sites miroirs. CMS utilise ASN.1, avec l'obligation d'utiliser l'encodage DER, le seul encodage d'ASN.1 qui ne soit pas ambigu (une seule façon de représenter un texte).
Les Internet-Drafts sont actuellement tous en texte
brut, limité à ASCII. Mais cela
ne va pas durer (RFC 7990). Les signatures des
Internet-Drafts sont détachées de l'Internet-Draft (section 2 de notre RFC), dans un fichier portant le même
nom auquel on ajoute l'extension .p7s (RFC 5751). Par exemple avec wget, pour
récupérer un Internet-Draft et sa signature :
% wget https://www.ietf.org/id/draft-bortzmeyer-dname-root-05.txt % wget https://www.ietf.org/id/draft-bortzmeyer-dname-root-05.txt.p7s
(Ne le faites pas avec un Internet-Draft trop récent, les signatures n'apparaissent qu'au bout de quelques jours, la clé privée n'est pas en ligne.)
La signature est au format CMS (RFC 5652). Son adaptation aux RFC et Internet-Drafts est
normalisée dans le RFC 5485. Le champ
SignedData.SignerInfo.EncapsulatedContentInfo.eContentType
du CMS identifie le type d'Internet-Draft signé. Les valeurs
possibles figurent dans un registre
IANA. Il y avait déjà des valeurs comme
id-ct-asciiTextWithCRLF qui identifiait
l'Internet-Draft classique en texte brut en ASCII, notre RFC ajoute (section
5) id-ct-utf8TextWithCRLF (texte brut en
UTF-8),
id-ct-htmlWithCRLF
(HTML) et id-ct-epub
(EPUB). Chacun de ces types a un
OID, par exemple le texte brut en UTF-8
sera 1.2.840.113549.1.9.16.1.37.
Maintenant, passons à un morceau délicat, la canonicalisation des Internet-Drafts. Signer nécessite de canonicaliser, autrement, deux textes identiques aux yeux de la lectrice pourraient avoir des signatures différentes. Pour le texte brut en ASCII, le principal problème est celui des fins de ligne, qui peuvent être représentées différemment selon le système d'exploitation. Nous utilisons donc la canonicalisation traditionnelle des fichiers texte sur l'Internet, celle de FTP : le saut de ligne est représenté par deux caractères, CR et LF. Cette forme est souvent connue sous le nom de NVT (Network Virtual Terminal) mais, bien que très ancienne, n'avait été formellement décrite qu'en 2008, dans l'annexe B du RFC 5198, qui traitait pourtant un autre sujet.
Pour les Internet-Drafts au format XML, notre RFC
renvoie simplement au W3C et à sa norme
XML, section 2.11 de la cinquième
édition, qui dit qu'il faut translating both the
two-character sequence #xD #xA and any #xD that is not followed by
#xA to a single #xA character. La canonicalisation
XML (telle que faite par xmllint
--c14n) n'est pas prévue.
Les autres formats ne subissent aucune opération particulière de canonicalisation. Un fichier EPUB, par exemple, est considéré comme une simple suite d'octets. On notera que le texte brut en Unicode ne subit pas de normalisation Unicode. C'est sans doute à cause du fait que le RFC 7997, dans sa section 4, considère que c'est hors-sujet. (Ce qui m'a toujours semblé une drôle d'idée, d'autant plus qu'il existe une norme Internet sur la canonicalisation du texte brut en Unicode, RFC 5198, qui impose la normalisation NFC.)
À l'heure actuelle, les Internet-Drafts sont signés, les outils doivent encore être adaptés aux nouvelles règles de ce RFC, mais elles sont simples et ça ne devrait pas être trop dur. Pour vérifier les signatures, la procédure (qui est documentée) consiste d'abord à installer le logiciel de canonicalisation :
% wget https://www.ietf.org/id-info/canon.c
% make canon
Puis à télécharger les certificats racine :
% wget https://www.ietf.org/id-info/verifybundle.pem
Vous pouvez examiner ce groupe de certificats avec :
% openssl crl2pkcs7 -nocrl -certfile verifybundle.pem | openssl pkcs7 -print_certs -text
Téléchargez ensuite des Internet-Drafts par exemple en
https://www.ietf.org/id/ :
% wget https://www.ietf.org/id/draft-ietf-isis-sr-yang-03.txt % wget https://www.ietf.org/id/draft-ietf-isis-sr-yang-03.txt.p7s
On doit ensuite canonicaliser l'Internet-Draft :
% ./canon draft-ietf-isis-sr-yang-03.txt draft-ietf-isis-sr-yang-03.txt.canon
On peut alors vérifier les signatures :
% openssl cms -binary -verify -CAfile verifybundle.pem -content draft-ietf-isis-sr-yang-03.txt.canon -inform DER -in draft-ietf-isis-sr-yang-03.txt.p7s -out /dev/null Verification successful
Si vous avez à la place :
Verification failure 139818719196416:error:2E09A09E:CMS routines:CMS_SignerInfo_verify_content:verification failure:../crypto/cms/cms_sd.c:819: 139818719196416:error:2E09D06D:CMS routines:CMS_verify:content verify error:../crypto/cms/cms_smime.c:393:
c'est sans doute que vous avez oublié l'option -binary.
Si vous trouvez la procédure compliquée, il y a un script qui
automatise tout ça idsigcheck :
% ./idsigcheck --setup
% ./idsigcheck draft-ietf-isis-sr-yang-03.txt
Si ça vous fait bad interpreter: /bin/bash^M,
il faut recoder les sauts de ligne :
% dos2unix idsigcheck
dos2unix: converting file idsigcheck to Unix format...
Ce script appelle OpenSSL mais pas avec les bonnes options à l'heure actuelle, vous risquez donc d'avoir la même erreur que ci-dessus.
L'article seul
Fiche de lecture : Bitcoin, la monnaie acéphale
Auteur(s) du livre : Adli Takkal Bataille, Jacques
Favier
Éditeur : CNRS Éditions
978-2-271-11554-6
Publié en 2017
Première rédaction de cet article le 11 mars 2018
Le succès du Bitcoin puis, plus récemment, celui du concept de chaîne de blocs, ont entrainé l'apparition de nombreux ouvrages sur le sujet. Ce dernier livre a un point de vue résolument « pieds dans le plat », en démolissant pas mal de vaches sacrées de la littérature économique.
Bitcoin dérange, c'est sûr, et les attaques contre lui n'ont pas manqué. Il a été accusé d'être une « monnaie virtuelle » (comme si l'euro ou le dollar avaient plus de réalité), d'être une monnaie de la délinquance (comme si la majorité des transactions illégales n'était pas en dollars), d'être une pyramide de Ponzi (sans doute l'accusation la plus ridicule)… Ce livre va donc tenter de redresser la barre, avec talent, et sans prendre de gants.
Dès la page 17, les discours des ignorants anti-Bitcoin se font étriller : « Ponzi, en matière d'argent, est un peu le point Godwin de l'invective » De nombreux autres clichés vont être remis en cause dans ce livre, qui aime les phrases-choc et, la plupart du temps, parfaitement justes.
Même quand une idée reçue est répétée en boucle par beaucoup de messieurs sérieux, les auteurs n'hésitent pas à lui tordre le cou. Ils exécutent ainsi les chaînes privées (« à permission ») p. 56, sans aucun respect pour tous les consultants qui vendent des rapports expliquant que c'est l'avenir.
Bon, la légende de la pyramide de Ponzi et les chaînes privées étaient des cibles faciles, aisées à réfuter. Mais ce livre ne recule pas non plus devant les critiques plus sérieuses, comme le problème écologique que posent les calculs (la « preuve de travail ») nécessaires pour protéger la chaîne Bitcoin. De même, les problèmes parfois « violents » agitant la « communauté » Bitcoin sont largement exposés et remis dans le contexte. On trouve par exemple une bonne analyse de la question du « pouvoir des mineurs ».
Les auteurs sont très à l'aise aussi bien avec l'informatique
qu'avec l'économie, mais dérapent parfois sur des sujets
« vendeurs » mais sur lesquels ils manquent de sens critique,
comme l'Internet des Objets ou le
vote électronique. De même, la présentation
de Namecoin est très sommaire, et comprend
d'ailleurs une erreur amusante lorsqu'ils disent que le
TLD utilisé pour les noms de domaine Namecoin est
.name (c'est en fait .bit).
Malgré ces défauts, c'est un livre que je recommande très fortement. Son titre à lui seul résume la bonne connaissance du Bitcoin par les auteurs : des tas d'adjectifs ont été utilisés pour le Bitcoin (« virtuel », « cryptographique », « décentralisé »…) mais je trouve qu'aucun ne résume aussi bien le Bitcoin que celui qu'ils ont choisi, « acéphale ».
L'article seul
Ça y est, j'ai la fibre
Première rédaction de cet article le 7 mars 2018
Voilà, après des années de discussions et quelques essais ratés, je suis connecté à la maison avec une fibre optique via Free. C'est plus compliqué que ça n'en a l'air, notamment en raison de la multiplicité des acteurs, qui ne communiquent pas, ou guère.
L'immeuble est récent, avec un mur porteur pas évident à percer, mais, en théorie, il y avait des fourreaux pour passer la fibre. Mais il n'y avait pas de plan correct de ces fourreaux, il a fallu procéder par essai/erreur. On glisse l'aiguille dans les fourreaux. Si elle ressort, c'est que ça passe, on crie « c'est bon, je la vois », on y attache la fibre et on la fait passer. À noter que deux aiguilles ont été testées, l'une, trop rigide, n'allant pas assez loin. Il a fallu utiliser le fourreau du câble téléphonique en cuivre, le seul un peu libre, et il ne restait pas beaucoup de place. L'aiguille passait seule, mais pas quand elle tirait la fibre. Les techniciens de Free m'ont demandé « vous avez du liquide vaisselle ? » Je leur ai donné du Mir, ils ont enduit l'aiguille et la fibre avec… et c'est passé. On oublie souvent que les solutions de haute technologie ne sont pas forcément les meilleures.
J'ai été sympa, le fourreau où passait le câble TV inutilisé a été laissé intact, au cas où le locataire suivant veuille l'utiliser…
Après, il a fallu connecter en bas, dans le sous-sol. La fibre était bien là, illuminée par le laser installé dans l'appartement, mais était cassée. Un coup de soudure, pas mal de recâblage (elle n'était apparemment pas à l'endroit indiqué) et c'est reparti.
Dans l'appartement, la sortie en cuivre du boitier fourni par
Free arrive directement dans la
Freebox. Comme ma Freebox est simplement
configurée en pont
(mode bridge), j'aurais peut-être pu essayer de
brancher le câble directement dans le
routeur, un Turris
Omnia. Mais je n'ai pas osé. Cela semble
possible, mais pas forcément trivial. Il semble notamment
que le trafic soit sur un VLAN (835 pour les données, et 836 pour la
télévision, apparemment). D'après un témoignage sur
proxad.free.ftth, il faut un
media converter (comme le TP-Link MC220L) ou bien demander à Free de
couper la négociation de vitesse.
Le passage de l'ADSL à la fibre entraine un changement d'adresses IP. En IPv4, le Turris apprend la nouvelle adresse automatiquement en DHCP, en IPv6, il faut refaire la configuration manuellement. L'adresse IPv4 ne semble pas partagée (en tout cas, je peux mettre des serveurs sur la Turris, ou sur des machines du réseau interne, et ils fonctionnent). Avantage, par rapport à l'ADSL, plus de tunnel, je peux utiliser une MTU normale.
Et pour finir, j'ai changé les user tags de ma sonde RIPE Atlas pour remplacer « ADSL » par « fibre ».
Notez que cela ne se passe pas toujours aussi bien !
L'article seul
RFC 8326: Graceful BGP Session Shutdown
Date de publication du RFC : Mars 2018
Auteur(s) du RFC : P. Francois, B. Decraene (Orange), C. Pelsser (Strasbourg University), K. Patel (Arrcus), C. Filsfils (Cisco Systems)
Chemin des normes
Réalisé dans le cadre du groupe de travail IETF grow
Première rédaction de cet article le 7 mars 2018
Voici une nouvelle communauté BGP,
GRACEFUL_SHUTDOWN, qui va permettre
d'annoncer une route à son pair BGP, tout en l'avertissant que le
lien par lequel elle passe va être bientôt coupé pour
une maintenance prévue. Le pair pourra alors automatiquement limiter l'usage de cette route
et chercher tout de suite des alternatives. Cela évitera les
pertes de paquets qui se produisent quand
on arrête un lien ou un
routeur.
Le protocole BGP (RFC 4271) qui assure le routage entre
les AS qui composent
l'Internet permet aux routeurs d'échanger des informations
entre eux « pour aller vers
2001:db8:bc9::/48, passe donc par moi ». Avec
ces informations, chaque routeur calcule les routes à suivre pour
chaque destination. Une fois que c'est fait, tout le monde se
repose ? Non, parce qu'il y a tout le temps des
changements. Certains peuvent être imprévus et accidentels (la
fameuse pelleteuse), d'autres sont planifiés à
l'avance : ce sont les opérations de maintenance « le 7 février à
2300 UTC, nous allons remplacer une
line card du routeur, coupant
toutes les sessions BGP de cette carte ». Voici par exemple un
message reçu sur la liste de diffusion des
opérateurs connectés au France-IX :
Date: Wed, 31 Jan 2018 15:57:34 +0000
From: Quelqu'un <quelquun@opérateur>
To: "paris@members.franceix.net" <paris@members.franceix.net>
Subject: [FranceIX members] [Paris] [OPÉRATEUR/ASXXXXX] - France-IX port maintenance
Dear peers,
Tomorrow morning CEST, we will be conducting a maintenance that will
impact one of our connection to France-IX (IPs: x.y.z.t/2001:x:y:z::t).
All sessions will be shut down before and brought back up once the maintenance will be over.
Please note that our MAC address will change as the link will be migrated to a new router.
Cheers
Lorsqu'une telle opération est effectuée, le résultat est le
même que pour une coupure imprévue : les sessions BGP sont
coupées, les routeurs retirent les routes apprises via ces
sessions, et vont chercher d'autres routes dans les annonces
qu'ils ont reçues. Ils propagent ensuite ces changements à leurs
voisins, jusqu'à ce que tout l'Internet soit au courant. Le
problème est que cela prend du temps (quelques secondes au moins,
des dizaines de secondes, parfois, à moins que les routeurs
n'utilisent le RFC 7911 mais ce n'est pas
toujours le cas). Et pendant ce temps, les paquets continuent à
arriver à des routeurs qui ne savent plus les traiter (section 3
du RFC). Ces paquets seront jetés, et devront être réémis (pour le
cas de TCP). Ce n'est pas
satisfaisant. Bien sûr, quand la coupure est imprévue, il n'y a
pas le choix. Mais quand elle est planifiée, on devrait pouvoir
faire mieux, avertir les routeurs qu'ils devraient cesser
d'utiliser cette route. C'est justement ce que permet la nouvelle
communauté GRACEFUL_SHUTDOWN. (Les
communautés BGP sont décrites dans le RFC 1997.) Elle s'utilise avant la
coupure, indiquant aux pairs qu'ils devraient commencer le
recalcul des routes, mais qu'ils peuvent continuer à utiliser les
anciennes routes pendant ce temps. (Notez qu'un cahier des charges
avait été établi pour ce problème, le RFC 6198. Et que ce projet d'une communauté pour les arrêts
planifiés est ancien, au moins dix ans.)
Ce RFC décrit donc deux choses, la
nouvelle communauté normalisée,
GRACEFUL_SHUTDOWN (section 5), et la procédure à utiliser
pour s'en servir proprement (section 4). L'idée est que les routes
qui vont bientôt être coupées pour maintenance restent utilisées,
mais avec une préférence locale très faible (la valeur 0 est
recommandée, la plus petite valeur possible). La notion de
préférence locale est décrite dans le RFC 4271, section 5.1.5. Comme son nom l'indique, elle est
locale à un AS, et représente sa préférence
(décidée unilatéralement) pour une route plutôt que pour une
autre. Lors du choix d'une route par BGP, c'est le premier critère
consulté.
Pour mettre en œuvre cette idée, chaque routeur au bord des
AS (ASBR, pour Autonomous System
Border Router) doit avoir une règle qui, lorsqu'une
annonce de route arrive avec la communauté
GRACEFUL_SHUTDOWN, applique une préférence
locale de 0. Notez que cela peut se faire avec les routeurs
actuels, aucun code nouveau n'est nécessaire, ce RFC ne décrit
qu'une procédure. Une fois que cette règle est en place, tout le
reste sera automatique, chez les pairs de l'AS qui coupe un lien
ou un routeur.
Et l'AS qui procéde à une opération de maintenance, que doit-il faire ? Dans l'ordre :
- Sur la·es session·s BGP qui va·ont être coupée·s,
appliquer la communauté
GRACEFUL_SHUTDOWNaux routes qu'on annonce (outbound policy), - Sur la·es session·s BGP qui va·ont être coupée·s, appliquer la communauté
GRACEFUL_SHUTDOWNaux routes qu'on reçoit (inbound policy), et mettre leur préférence locale à zéro, - Attendre patiemment que tout le monde ait convergé (propagation des annonces),
- Procéder à l'opération de maintenance, qui va couper BGP (et c'est plus joli si on utilise le RFC 9003).
J'ai dit plus haut qu'il n'était pas nécessaire de modifier le
logiciel des routeurs BGP mais évidemment tout est plus simple
s'ils connaissent la communauté
GRACEFUL_SHUTDOWN et simplifient ainsi la
tâche de l'administrateur réseaux. Cette communauté est « bien
connue » (elle n'est pas spécifique à un
AS), décrite
dans la section 5 du RFC, enregistrée à
l'IANA et sa valeur est 0xFFFF0000 (qui peut aussi s'écrire
65535:0, dans la notation habituelle des communautés).
La section 6 du RFC fait le tour de la sécurité de ce
système. Comme il permet d'influencer le routage chez les pairs
(on annonce une route avec la communauté
GRACEFUL_SHUTDOWN et paf, le pair met une
très faible préférence à ces routes), il ouvre la porte à de
l'ingénierie du trafic pas toujours
bienveillante. Il est donc prudent de regarder ce qu'annoncent ses
pairs, et d'engueuler ou de dépairer ceux et celles qui abusent de
ce mécanisme.
Pour les amateurs de solutions alternatives, l'annexe A
explique les autres techniques qui auraient pu être utilisées lors
de la réception des routes marquées avec GRACEFUL_SHUTDOWN. Au
lieu d'influencer la préférence locale, on aurait par exemple pu utiliser le
MED (multi-exit discriminator, RFC 4271, section 5.1.4) mais il n'est considéré par les
pairs qu'après d'autres critères, et il ne garantit donc pas que
le lien bientôt coupé ne sera plus utilisé.
L'annexe B donne des exemples de configuration pour différents types de routeurs. (Configurations pour l'AS qui reçoit la notification d'un arrêt proche, pas pour ceux qui émettent.) Ainsi, pour IOS XR :
! 65535:0 = 0xFFFF0000
community-set comm-graceful-shutdown
65535:0
end-set
route-policy AS64497-ebgp-inbound
! Règles appliquées aux annonces reçues du pair, l'AS 64497. Bien
! sûr, en vrai, il y aurait plein d'autres règles, par exemple de filtrage.
if community matches-any comm-graceful-shutdown then
set local-preference 0
endif
! On a appliqué la règle du RFC : mettre la plus faible
! préférence locale possible
end-policy
! La configuration de la session BGP avec le pair
router bgp 64496
neighbor 2001:db8:1:2::1
remote-as 64497
address-family ipv6 unicast
send-community-ebgp
route-policy AS64497-ebgp-inbound in
Pour BIRD, cela sera :
# (65535, 0) = 0xFFFF0000
function honor_graceful_shutdown() {
if (65535, 0) ~ bgp_community then {
bgp_local_pref = 0;
}
}
filter AS64497_ebgp_inbound
{
# Règles appliquées aux annonces reçues du pair, l'AS 64497. Bien
# sûr, en vrai, il y aurait plein d'autres règles, par
# exemple de filtrage.
honor_graceful_shutdown();
}
protocol bgp peer_64497_1 {
neighbor 2001:db8:1:2::1 as 64497;
local as 64496;
import keep filtered;
import filter AS64497_ebgp_inbound;
}
Et sur OpenBGPD (on voit qu'il connait
GRACEFUL_SHUTDOWN, il n'y a pas besoin de
donner sa valeur) :
AS 64496
router-id 192.0.2.1
neighbor 2001:db8:1:2::1 {
remote-as 64497
}
# Règles appliquées aux annonces reçues du pair, l'AS 64497. Bien
# sûr, en vrai, il y aurait plein d'autres règles, par exemple de filtrage.
match from any community GRACEFUL_SHUTDOWN set { localpref 0 }
Enfin, l'annexe C du RFC décrit quelques détails supplémentaires, par exemple pour IBGP (BGP interne à un AS).
Notez que ce nouveau RFC est prévu pour le cas où la transmission des paquets (forwarding plane) est affectée. Si c'est uniquement la session BGP (control plane) qui est touchée, la solution du RFC 4724, Graceful Restart, est plus appropriée.
L'article seul
RFC 8334: Launch Phase Mapping for the Extensible Provisioning Protocol (EPP)
Date de publication du RFC : Mars 2018
Auteur(s) du RFC : J. Gould (VeriSign), W. Tan (Cloud Registry), G. Brown (CentralNic)
Chemin des normes
Réalisé dans le cadre du groupe de travail IETF regext
Première rédaction de cet article le 5 mars 2018
Les registres de noms de domaine ont parfois des périodes d'enregistrement spéciales, par exemple lors de la phase de lancement d'un nouveau domaine d'enregistrement, ou bien lorsque les règles d'enregistrement changent. Pendant ces périodes, les conditions d'enregistrement ne sont pas les mêmes que pendant les périodes « standards ». Les registres qui utilisent le protocole EPP pour l'enregistrement peuvent alors utiliser les extensions EPP de ce nouveau RFC pour gérer ces périodes spéciales.
Un exemple de période spéciale est l'ouverture d'un tout nouveau TLD à l'enregistrement. Un autre exemple est une libéralisation de l'enregistrement, passant par exemple de vérifications a priori strictes à un modèle plus ouvert. Dans les deux cas, on peut voir des conflits se faire jour, par exemple entre le titulaire le plus rapide à enregistrer un nom, et un détenteur de propriété intellectuelle qui voudrait reprendre le nom. Les périodes spéciales sont donc définies par des privilèges particuliers pour certains utilisateurs, permettant par exemple aux titulaires d'une marque déposée d'avoir un avantage pour le nom de domaine correspondant à cette marque. La période spéciale est qualifiée de « phase de lancement » (launch phase). Les extensions à EPP décrites dans ce nouveau RFC permettent de mettre en œuvre ces privilèges.
La classe (mapping) décrivant les domaines en EPP figure dans le RFC 5731. Elle est prévue pour le fonctionnement standard du registre, sans intégrer les périodes spéciales. Par exemple, en fonctionnement standard, une fois que quelqu'un a enregistré un nom, c'est fini, personne d'autre ne peut le faire. Mais dans les phases de lancement, il arrive qu'on accepte plusieurs candidatures pour un même nom, qui sera ensuite attribué en fonction de divers critères (y compris parfois une mise aux enchères). Ou bien il peut y avoir des vérifications supplémentaires pendant une phase de lancement. Par exemple, certaines phases peuvent être réservées aux titulaires de propriété intellectuelle, et cela est vérifié via un organisme de validation, comme la TMCH (RFC 7848).
D'où ce RFC qui étend la classe domain
du RFC 5731. La section 2 du RFC décrit les
nouveaux attributs et éléments des domaines, la section 3 la façon de les
utiliser dans les commandes EPP et la
section 4 donne le schéma XML. Voyons
d'abord les nouveaux éléments et attributs.
D'abord, comme il peut y avoir plusieurs candidatures pour un
même nom, il faut un moyen de les distinguer. C'est le but de
l'identificateur de candidature (application
identifier). Lorsque le serveur EPP reçoit une commande
<domain:create> pour un nom, il attribue un
identificateur de candidature, qu'il renvoie au client, dans un
élément <launch:applicationID>, tout en
indiquant que le domaine est en état
pendingCreate (RFC 5731, section 2.3) puisque le domaine n'a pas encore été
créé.
Au passage, launch dans
<launch:applicationID> est une
abréviation pour l'espace de noms XML
urn:ietf:params:xml:ns:launch-1.0. Un
processeur XML correct ne doit évidemment pas tenir compte de
l'abréviation (qui peut être ce qu'on veut) mais uniquement de
l'espace de noms associé. Cet espace est désormais enregistré
à l'IANA (cf. RFC 3688).
Autre nouveauté, comme un serveur peut utiliser plusieurs
organismes de validation d'une marque
déposée, il existe désormais un attribut
validatorID qui indique l'organisme. Par
défaut, c'est la TMCH (identificateur
tmch). On pourra utiliser cet attribut
lorsqu'on indiquera un identificateur de marque, par exemple
lorsqu'on se sert de l'élément
<mark:mark> du RFC 7848.
Les périodes spéciales ont souvent plusieurs phases, et notre
RFC en définit plusieurs (dans une ouverture réelle, toutes ne
sont pas forcément utilisées), qui seront utilisées dans l'élément
<launch:phase> :
- Lever de soleil (sunrise), phase où les titulaires de marques (le RFC ne mentionne pas d'autres cas, comme le nom de l'entreprise ou d'une ville) peuvent seuls soumettre des candidatures, la marque étant validée par exemple via la TMCH,
- Prétentions (claims), où on peut
enregistrer si on n'a pas de marque, mais on reçoit alors une
notice disant qu'une marque similaire existe (elle est décrite
plus en détail dans
l'Internet-Draft
draft-ietf-regext-tmch-func-spec), et on peut alors renoncer ou continuer (si on est d'humeur à affronter les avocats de la propriété intellectuelle), en annonçant, si on continue « oui, j'ai vu, j'y vais quand même », - Ruée (landrush), phase immédiatement après l'ouverture, quand tout le monde et son chien peuvent se précipiter pour enregistrer,
- État ouvert (open), une fois qu'on a atteint le régime de croisière.
La section 2 définit aussi les états d'une candidature. Notamment :
pendingValidation(validation en attente),validated(c'est bon, mais voyez plus loin),invalid(raté, vous n'avez pas de droits sur ce nom),pendingAllocation(une fois qu'on est validé, tout n'est pas fini, il peut y avoir plusieurs candidatures, avec un mécanisme de sélection, par exemple fondé sur une enchère),allocated(c'est vraiment bon),rejected(c'est fichu…)
Les changements d'état ne sont pas forcément synchrones. Parfois, il faut attendre une validation manuelle, par exemple. Dans cas, il faut notifier le client EPP, ce qui se fait avec le mécanisme des messages asynchrones (poll message) du RFC 5730, section 2.9.2.3.
Comme toutes les extensions EPP, elle n'est utilisée par le client que si le serveur l'indique à l'ouverture de la session, en listant les espaces de noms XML des extensions qu'il accepte, par exemple :
<?xml version="1.0" encoding="UTF-8" standalone="no"?>
<epp xmlns="urn:ietf:params:xml:ns:epp-1.0">
<greeting><svID>EPP beautiful server for .example</svID>
<svDate>2018-02-20T15:37:20.0Z</svDate>
<svcMenu><version>1.0</version><lang>en</lang>
<objURI>urn:ietf:params:xml:ns:domain-1.0</objURI>
<objURI>urn:ietf:params:xml:ns:contact-1.0</objURI>
<svcExtension>
<extURI>urn:ietf:params:xml:ns:rgp-1.0</extURI>
<extURI>urn:ietf:params:xml:ns:secDNS-1.1</extURI>
<extURI>urn:ietf:params:xml:ns:launch-1.0</extURI>
</svcExtension>
</svcMenu>
</greeting>
</epp>
Maintenant qu'on a défini les données, la section 3 du RFC
explique comment les utiliser. (Dans tous les exemples ci-dessous,
C: identifie ce qui est envoyé par le client
EPP et S: ce que le serveur répond.) Par exemple, la commande EPP
<check> (RFC 5730,
section 2.9.2.1) sert à vérifier si on peut enregistrer un objet
(ici, un nom de domaine). Elle prend ici des éléments
supplémentaires, par exemple pour tester si un nom correspond à
une marque. Ici, on demande si une marque existe (notez
l'extension <launch:check>) :
C:<epp xmlns="urn:ietf:params:xml:ns:epp-1.0">
C: <command>
C: <check>
C: <domain:check
C: xmlns:domain="urn:ietf:params:xml:ns:domain-1.0">
C: <domain:name>domain1.example</domain:name>
C: </domain:check>
C: </check>
C: <extension>
C: <launch:check
C: xmlns:launch="urn:ietf:params:xml:ns:launch-1.0"
C: type="trademark"/>
C: </extension>
C: </command>
C:</epp>
Et on a la réponse (oui, la marque existe dans la TMCH) :
S:<epp xmlns="urn:ietf:params:xml:ns:epp-1.0">
S: <response>
S: <result code="1000">
S: <msg>Command completed successfully</msg>
S: </result>
S: <extension>
S: <launch:chkData
S: xmlns:launch="urn:ietf:params:xml:ns:launch-1.0">
S: <launch:cd>
S: <launch:name exists="1">domain1.example</launch:name>
S: <launch:claimKey validatorID="tmch">
S: 2013041500/2/6/9/rJ1NrDO92vDsAzf7EQzgjX4R0000000001
S: </launch:claimKey>
S: </launch:cd>
S: </launch:chkData>
S: </extension>
S: </response>
S:</epp>
Avec la commande EPP <info>, qui
sert à récupérer des informations sur un nom, on voit ici qu'un
nom est en attente (pendingCreate), et on a
l'affichage de la phase actuelle du lancement, dans l'élément
<launch:phase> :
C:<epp xmlns="urn:ietf:params:xml:ns:epp-1.0">
C: <command>
C: <info>
C: <domain:info
C: xmlns:domain="urn:ietf:params:xml:ns:domain-1.0">
C: <domain:name>domain.example</domain:name>
C: </domain:info>
C: </info>
C: <extension>
C: <launch:info
C: xmlns:launch="urn:ietf:params:xml:ns:launch-1.0"
C: includeMark="true">
C: <launch:phase>sunrise</launch:phase>
C: </launch:info>
C: </extension>
C: </command>
C:</epp>
Et le résultat, avec entre autre l'identificateur de candidature :
S:<epp xmlns="urn:ietf:params:xml:ns:epp-1.0">
S: <response>
S: <result code="1000">
S: <msg>Command completed successfully</msg>
S: </result>
S: <resData>
S: <domain:infData
S: xmlns:domain="urn:ietf:params:xml:ns:domain-1.0">
S: <domain:name>domain.example</domain:name>
S: <domain:status s="pendingCreate"/>
S: <domain:registrant>jd1234</domain:registrant>
S: <domain:contact type="admin">sh8013</domain:contact>
S: <domain:crDate>2012-04-03T22:00:00.0Z</domain:crDate>
...
S: </domain:infData>
S: </resData>
S: <extension>
S: <launch:infData
S: xmlns:launch="urn:ietf:params:xml:ns:launch-1.0">
S: <launch:phase>sunrise</launch:phase>
S: <launch:applicationID>abc123</launch:applicationID>
S: <launch:status s="pendingValidation"/>
S: <mark:mark
S: xmlns:mark="urn:ietf:params:xml:ns:mark-1.0">
S: ...
S: </mark:mark>
S: </launch:infData>
S: </extension>
S: </response>
S:</epp>
C'est bien joli d'avoir des informations mais, maintenant, on
voudrait créer des noms de domaine. La commande EPP
<create> (RFC 5730, section 2.9.3.1) sert à cela. Selon la phase de
lancement, il faut lui passer des extensions différentes. Pendant
le lever de soleil (sunrise), il faut indiquer
la marque déposée sur laquelle on s'appuie, dans
<launch:codeMark> (il y a d'autres
moyens de l'indiquer, cf. section 2.6) :
C:<epp xmlns="urn:ietf:params:xml:ns:epp-1.0">
C: <command>
C: <create>
C: <domain:create
C: xmlns:domain="urn:ietf:params:xml:ns:domain-1.0">
C: <domain:name>domain.example</domain:name>
C: <domain:registrant>jd1234</domain:registrant>
...
C: </domain:create>
C: </create>
C: <extension>
C: <launch:create
C: xmlns:launch="urn:ietf:params:xml:ns:launch-1.0">
C: <launch:phase>sunrise</launch:phase>
C: <launch:codeMark>
C: <launch:code validatorID="sample1">
C: 49FD46E6C4B45C55D4AC</launch:code>
C: </launch:codeMark>
C: </launch:create>
C: </extension>
C: </command>
C:</epp>
On reçoit une réponse qui dit que le domaine n'est pas encore
créé, mais on a un identificateur de candidature (un numéro de
ticket, quoi) en <launch:applicationID>. Notez le code de retour 1001 (j'ai
compris mais je ne vais pas le faire tout de suite) et non pas
1000, comme ce serait le cas en régime de croisière :
S:<epp xmlns="urn:ietf:params:xml:ns:epp-1.0">
S: <response>
S: <result code="1001">
S: <msg>Command completed successfully; action pending</msg>
S: </result>
S: <resData>
S: <domain:creData
S: xmlns:domain="urn:ietf:params:xml:ns:domain-1.0">
S: <domain:name>domain.example</domain:name>
S: <domain:crDate>2010-08-10T15:38:26.623854Z</domain:crDate>
S: </domain:creData>
S: </resData>
S: <extension>
S: <launch:creData
S: xmlns:launch="urn:ietf:params:xml:ns:launch-1.0">
S: <launch:phase>sunrise</launch:phase>
S: <launch:applicationID>2393-9323-E08C-03B1
S: </launch:applicationID>
S: </launch:creData>
S: </extension>
S: </response>
S:</epp>
De même, des extensions permettent de créer un domaine pendant la phase où il faut indiquer qu'on a vu les prétentions qu'avait un titulaire de marque sur ce nom. Le RFC décrit aussi l'extension à utiliser dans la phase de ruée (landrush), mais j'avoue n'avoir pas compris son usage (puisque, pendant la ruée, les règles habituelles s'appliquent).
On peut également retirer une candidature, avec la commande EPP
<delete> qui, en mode standard, sert à
supprimer un domaine. Il faut alors indiquer l'identifiant de la
candidature qu'on retire :
C:<epp xmlns="urn:ietf:params:xml:ns:epp-1.0">
C: <command>
C: <delete>
C: <domain:delete
C: xmlns:domain="urn:ietf:params:xml:ns:domain-1.0">
C: <domain:name>domain.example</domain:name>
C: </domain:delete>
C: </delete>
C: <extension>
C: <launch:delete
C: xmlns:launch="urn:ietf:params:xml:ns:launch-1.0">
C: <launch:phase>sunrise</launch:phase>
C: <launch:applicationID>abc123</launch:applicationID>
C: </launch:delete>
C: </extension>
C: </command>
C:</epp>
Et les messages non sollicités (poll), envoyés de manière asynchrone par le serveur ? Voici un exemple, où le serveur indique que la candidature a été jugée valide (le mécanisme par lequel on passe d'un état à un autre dépend de la politique du serveur) :
S:<epp xmlns="urn:ietf:params:xml:ns:epp-1.0">
S: <response>
S: <result code="1301">
S: <msg>Command completed successfully; ack to dequeue</msg>
S: </result>
S: <msgQ count="5" id="12345">
S: <qDate>2013-04-04T22:01:00.0Z</qDate>
S: <msg>Application pendingAllocation.</msg>
S: </msgQ>
S: <resData>
S: <domain:infData
S: xmlns:domain="urn:ietf:params:xml:ns:domain-1.0">
S: <domain:name>domain.example</domain:name>
S: ...
S: </domain:infData>
S: </resData>
S: <extension>
S: <launch:infData
S: xmlns:launch="urn:ietf:params:xml:ns:launch-1.0">
S: <launch:phase>sunrise</launch:phase>
S: <launch:applicationID>abc123</launch:applicationID>
S: <launch:status s="pendingAllocation"/>
S: </launch:infData>
S: </extension>
S: </response>
S:</epp>
Voilà, vous savez l'essentiel, si vous voulez tous les détails, il faudra lire la section 3 complète, ainsi que la section 4, qui contient le schéma XML des extensions pour les phases de lancement. Comme toutes les extensions à EPP, celle de ce RFC est désormais dans le registre des extensions EPP, décrit dans le RFC 7451.
Notez que ce RFC ne fournit pas de moyen pour indiquer au client EPP quelle est la politique d'enregistrement pendant la période spéciale. Cela doit être fait par un mécanisme externe (page Web du registre, par exemple).
Quelles sont les mises en œuvre de ce RFC ? L'extension pour les phases de lancement est ancienne (première description en 2011) et de nombreux registres offrent désormais cette possibilité. C'est d'autant plus vrai que l'ICANN impose aux registres de ses nouveaux TLD de gérer les phases de lancement avec cette extension. Ainsi :
- Le kit de développement de clients EPP de Verisign a cette extension, sous une licence libre.
- Logiquement, le système d'enregistrement de Verisign,
utilisé notamment pour
.comet.net(mais également pour bien d'autres TLD) gère cette extension (code non libre et non public, cette fois). - Le serveur REngin (non libre),
utilisé pour
.zaa aussi cette extension. - Le serveur de CentralNIC, pareil.
- Le client EPP distribué par Neustar est sous licence libre et sait gérer les phases de lancement.
- Le serveur (non libre) de SIDN (qui
gère le domaine national
.nl) fait partie de ceux qui ont mis en œuvre ce RFC. - Et côté client, il y a le logiciel libre Net::DRI
(extension ajoutée dans une scission nommée
tdw, pas dans le logiciel originel de Patrick Mevzek), cf.LaunchPhase.pm.
L'article seul
RFC 8324: DNS Privacy, Authorization, Special Uses, Encoding, Characters, Matching, and Root Structure: Time for Another Look?
Date de publication du RFC : Février 2018
Auteur(s) du RFC : J. Klensin
Pour information
Première rédaction de cet article le 28 février 2018
Le DNS est une infrastructure essentielle
de l'Internet. S'il est en panne, rien ne marche (sauf si vous
faites partie de la minorité qui fait uniquement des ping
-n et des traceroute -n). S'il est
lent, tout rame. Comme le DNS, heureusement, marche très bien, et
s'est montré efficace, fiable et rapide, il souffre aujourd'hui de
la malédiction des techniques à succès : on essaie de charger la
barque, de lui faire faire plein de choses pour lesquelles il
n'était pas prévu. D'un côté, c'est un signe de succès. De l'autre,
c'est parfois fragilisant. Dans ce RFC
individuel (qui exprime juste le point de vue d'un individu, et
n'est pas du tout une norme
IETF), John Klensin, qui ne participe plus
activement au développement du DNS depuis des années, revient sur
certaines de ces choses qu'on essaie de faire faire au DNS et se
demande si ce n'est pas trop, et à partir de quel point il faudrait
arrêter de « perfectionner » le DNS et plutôt passer à « autre
chose » (« quand le seul outil qu'on a est un marteau, tous les
problèmes ressemblent à des clous… »). Une bonne lecture pour
celleszetceux qui ne veulent pas seulement faire marcher le DNS mais
aussi se demander « pourquoi c'est comme ça ? » et « est-ce que ça
pourrait être différent ? »
Améliorer le système petit à petit ou bien le remplacer complètement ? C'est une question que se posent régulièrement les ingénieurs, à propos d'un logiciel, d'un langage de programmation, d'un protocole réseau. À l'extrême, il y a l'ultra-conservateur qui ne voit que des inconvénients aux solutions radicales, à l'autre il y a l'ultra-optimiste qui en a marre des rustines et qui voudrait jeter le vieux système, pour le remplacer par un système forcément meilleur, car plus récent. Entre les deux, beaucoup d'informaticiens hésitent. L'ultra-conservateur oublie que les rustines successives ont transformé l'ancien système en un monstre ingérable et difficile à maintenir, l'ultra-optimiste croit naïvement qu'un système nouveau, rationnellement conçu (par lui…) sera à coup sûr plus efficace et moins bogué. Mais les deux camps, et tout celleszetceux qui sont entre les deux peuvent tirer profit de ce RFC, pour approfondir leur réflexion.
Klensin note d'abord que le DNS est vieux. La première réflexion à ce sujet était le RFC 799 en 1981, et le premier RFC décrivant le DNS est le RFC 882, en novembre 1983. (Paul Mockapetris a raconté le développement du DNS dans « Development of the Domain Name System », j'ai fait un résumé des articles d'histoire du DNS.) Le DNS remplaçait l'ancien système fondé sur un fichier centralisé de noms de machines (RFC 810, RFC 952, et peut-être aussi RFC 953). Tout n'est pas écrit : le DNS n'a pas aujourd'hui une spécification unique et à jour, aux RFC de base (RFC 1034 et RFC 1035, il faut ajouter des dizaines de RFC qui complètent ou modifient ces deux-ci, ainsi que pas mal de culture orale. (Un exemple de cette difficulté était que, pendant le développement du RFC 7816, son auteur s'est aperçu que personne ne se souvenait pourquoi les résolveurs envoyaient le FQDN complet dans les requêtes.) Plusieurs techniques ont même été supprimées comme les requêtes inverses (RFC 3425) ou comme les types d'enregistrement WKS, MD, MF et MG.
D'autres auraient dû être supprimées, car inutilisables en pratique, comme les classes (que prétendait utiliser le projet Net4D), et qui ont fait l'objet de l'Internet-Draft « The DNS Is Not Classy: DNS Classes Considered Useless », malheureusement jamais adopté dans une IETF parfois paralysée par la règle du consensus.
D'autres évolutions ont eu lieu : le DNS original ne proposait aucun mécanisme d'options, tous les clients et tous les serveurs avaient exactement les mêmes capacités. Cela a changé avec l'introduction d'EDNS, dans le RFC 2671 en 1999.
Beaucoup d'articles ont été écrits sur les systèmes de nommage. (Le RFC recommande l'article de V. Cerf, « Desirable Properties of Internet Identifiers », ou bien le livre « Signposts in Cyberspace: The Domain Name System and Internet Navigation ». Je me permets de rajouter mes articles, « Inventer un meilleur système de nommage : pas si facile », « Un DNS en pair-à-pair ? » et « Mon premier nom Namecoin enregistré ».)
Pourquoi est-ce que les gens ne sont pas contents du DNS actuel et veulent le changer (section 4 du RFC, la plus longue du RFC) ? Il y a des tas de raisons. Certaines, dit l'auteur, peuvent mener à des évolutions raisonnables du DNS actuel. Certaines nécessiteraient un protocole complètement nouveau, incompatible avec le DNS. D'autres enfin seraient irréalistes, quel que soit le système utilisé. La section 4 les passe en revue (rappelez-vous que ce RFC est une initiative individuelle, pas une opinion consensuelle à l'IETF).
Premier problème, les requêtes « multi-types ». À l'heure actuelle, une requête DNS est essentiellement composée d'un nom (QNAME, Query Name) et d'un type (QTYPE, Query Type, par exemple AAAA pour une adresse IP, TLSA pour une clé publique, etc). Or, on aurait parfois besoin de plusieurs types. L'exemple classique est celui d'une machine double-pile (IPv6 et le vieil IPv4), qui ne sait pas quelle version d'IP est acceptée en face et qui demande donc l'adresse IPv6 et l'adresse IPv4 du pair. Il n'y a actuellement pas de solution pour ce problème, il faut faire deux requêtes DNS. (Et, non, ANY ne résout pas ce problème, notamment en raison de l'interaction avec les caches : que doit faire un cache qui ne connait qu'une seule des deux adresses ?)
Deuxième problème, la sensibilité à la casse. La norme originale prévoyait des requêtes insensibles à la casse (RFC 1034, section 3.1), ce qui semble logique aux utilisateurs de l'alphabet latin. Mais c'est plutôt une source d'ennuis pour les autres écritures (et c'est une des raisons pour lesquelles accepter l'Unicode dans les noms de domaine nécessite des méthodes particulières). Avec ASCII, l'insensibilité à la casse est facile (juste un bit à changer pour passer de majuscule en minuscule et réciproquement) mais ce n'est pas le cas pour le reste d'Unicode. En outre, il n'est pas toujours évident de connaitre la correspondance majuscule-minuscule (cf. les débats entre germanophones sur la majuscule de ß). Actuellement, les noms de domaine en ASCII sont insensibles à la casse et ceux dans le reste du jeu de caractères Unicode sont forcément en minuscules (cf. RFC 5890), libre à l'application de mettre ses propres règles d'insensibilité à la casse si elle veut, lorsque l'utilisateur utilise un nom en majuscules comme RÉUSSIR-EN.FR. On referait le DNS en partant de zéro, peut-être adopterait-on UTF-8 comme encodage obligatoire, avec normalisation NFC dans les serveurs de noms, mais c'est trop tard pour le faire.
En parlant d'IDN, d'ailleurs, ce sujet a été à l'origine de nombreuses discussions, incluant pas mal de malentendus (pour lesquels, à mon humble avis, l'auteur de RFC a une sérieuse responsabilité). Unicode a une particularité que n'a pas ASCII : le même caractère peut être représenté de plusieurs façons. L'exemple classique est le É qui peut être représenté par un point de code, U+00C9 (LATIN CAPITAL LETTER E WITH ACUTE), ou par deux, U+0045 (LATIN CAPITAL LETTER E) et U+0301 (COMBINING ACUTE ACCENT). Je parle bien de la représentation en points de code, pas de celle en bits sur le réseau, qui est une autre affaire ; notez que la plupart des gens qui s'expriment à propos d'Unicode sur les forums ne connaissent pas Unicode. La normalisation Unicode vise justement à n'avoir qu'une forme (celle à un point de code si on utilise NFC) mais elle ne traite pas tous les cas gênants. Par exemple, dans certains cas, la fonction de changement de casse dépend de la langue (que le DNS ne connait évidemment pas). Le cas le plus célèbre est celui du i sans point U+0131, qui a une règle spécifique en turc. Il ne sert à rien de râler contre les langues humaines (elles sont comme ça, point), ou contre Unicode (dont la complexité ne fait que refléter celles des langues humaines et de leurs écritures). Le point important est qu'on n'arrivera pas à faire en sorte que le DNS se comporte comme M. Toutlemonde s'y attend, sauf si on se limite à un M. Toutlemonde étatsunien (et encore).
Les IDN ont souvent été accusés, y compris dans ce RFC, de
permettre, ou en tout cas de faciliter, le
hameçonnage par la confusion possible entre
deux caractères visuellement proches. En fait, le problème n'est pas
spécifique aux IDN (regardez google.com et
goog1e.com) et les études montrent que les
utilisateurs ne vérifient pas les noms, de toute façon. Bref,
il s'agit de simple propagande de la part de ceux qui n'ont jamais
vraiment accepté Unicode.
Les IDN nous amènent à un problème proche,
celui des synonymes. Les noms de domaine
color.example et
colour.example sont différents alors que, pour
tout anglophone, color
et colour
sont « équivalents ». J'ai mis le mot « équivalent » entre
guillemets car sa définition même est floue. Est-ce que
« Saint-Martin » est équivalent à « St-Martin » ? Et est-ce que
« Dupont » est équivalent à « Dupond » ? Sans même aller chercher des
exemples comme l'équivalence entre sinogrammes simplifiés et sinogrammes
traditionnels, on voit que l'équivalence est un concept
difficile à cerner. Souvent, M. Michu s'agace « je tape
st-quentin.fr, pourquoi est-ce que ça n'est pas
la même chose que
saint-quentin-en-yvelines.fr ? »
Fondamentalement, la réponse est que le DNS ne gère pas les requêtes
approximatives, et qu'il n'est pas évident que tout le monde soit
d'accord sur l'équivalence de deux noms. Les humains se débrouillent
avec des requêtes floues car ils ont un
contexte. Si on est dans les
Yvelines, je sais que « St-Quentin » est
celui-ci
alors que, si on est dans l'Aisne, mon interlocuteur parle
probablement de celui-là. Mais le DNS n'a pas ce
contexte.
Plusieurs RFC ont été écrit à ce sujet, RFC 3743, RFC 4290, RFC 6927 ou RFC 7940, sans résultats convaincants. Le DNS a bien sûr des mécanismes permettant de dire que deux noms sont équivalents, comme les alias (enregistrements CNAME) ou comme les DNAME du RFC 6672. Mais :
- Aucun d'entre eux n'a exactement la sémantique que les utilisateurs voudraient (d'où des propositions régulières d'un nouveau mécanisme comme les BNAME),
- Et ils supposent que quelqu'un ait configuré les correspondances, ce qui suscitera des conflits, et ne satisfera jamais tout le monde.
Même écrire un cahier des charges des « variantes » n'a jamais été possible. (C'est également un sujet sur lequel j'avais écrit un article.)
Passons maintenant aux questions de protection de la vie privée. L'auteur du RFC note que la question suscite davantage de préoccupations aujourd'hui mais ne rappelle pas que ces préoccupations ne sont pas irrationnnelles, elles viennent en grande partie de la révélation de programmes de surveillance massive comme MoreCowBell. Et il « oublie » d'ailleurs de citer le RFC 7626, qui décrit en détail le problème de la vie privée lors de l'utilisation du DNS.
J'ai parlé plus haut du problème des classes dans le DNS, ce
paramètre supplémentaire des enregistrements DNS (un enregistrement
est identifié par trois choses, le nom, la classe et le
type). L'idée au début (RFC 1034, section 3.6)
était de gérer depuis le DNS plusieurs protocoles très différents
(IP, bien sûr, mais aussi
CHAOS et d'autres futurs), à l'époque où le
débat faisait rage entre partisans d'un réseau à protocole unique
(le futur Internet) et ceux et celles qui
préféraient un catenet, fondé sur
l'interconnexion de réseaux techniquement différents. Mais,
aujourd'hui, la seule classe qui sert réellement est IN (Internet)
et, en pratique, il y a peu de chances que les autres soient jamais
utilisées. Il a parfois été suggéré d'utiliser les classes pour
partitionner l'espace de noms (une classe IN pour
l'ICANN et créer une classe UN afin de la donner à
l'UIT pour qu'elle puisse jouer à la gouvernance ?) mais le fait que les
classes aient été
très mal normalisées laisse peu d'espoir. (Est-ce que IN
example, CH example et UN example sont la même
zone ? Ont-ils les mêmes serveurs de noms ? Cela n'a jamais été
précisé.)
Une particularité du DNS qui déroute souvent les nouveaux administrateurs système est le fait que les données ne soient que faiblement synchronisées : à un moment donné, il est parfaitement normal que plusieurs valeurs coexistent dans l'Internet. Cela est dû à plusieurs choix, notamment :
- Celui d'avoir plusieurs serveurs faisant autorité pour une zone, et sans mécanisme assurant leur synchronisation forte. Lorsque le serveur maître (ou primaire) est mis à jour, il sert immédiatement les nouvelles données, sans attendre que les esclaves (ou secondaires) se mettent à jour.
- Et le choix d'utiliser intensivement les caches, la mémoire des résolveurs. Si un serveur faisant autorité sert un enregistrement avec un TTL de 7 200 secondes (deux heures) et que, cinq minutes après qu'un résolveur ait récupéré cet enregistrement, le serveur faisant autorité modifie l'enregistrement, les clients du résolveur verront encore l'ancienne valeur pendant 7 200 - 300 = 6 900 secondes.
Cela a donné naissance à la légende de la propagation du DNS et aux chiffres fantaisistes qui accompagnent cette légende comme « il faut 24 h pour que le DNS se propage ».
Ces choix ont assuré le succès du DNS, en lui permettant de passer à l'échelle, vers un Internet bien plus grand que prévu à l'origine. Un modèle à synchronisation forte aurait été plus compliqué, plus fragile et moins performant.
Mais tout choix en ingéniérie a des bonnes conséquences et des mauvaises : la synchronisation faible empêche d'utiliser le DNS pour des données changeant souvent. Des perfectionnements ont eu lieu (comme la notification non sollicitée du RFC 1996, qui permet aux serveurs secondaires d'être au courant rapidement d'un changement, mais qui ne marche que dans le cas où on connait tous les secondaires) mais n'ont pas fondamentalement changé le tableau. Bien sûr, les serveurs faisant autorité qui désireraient une réjuvénation plus rapide peuvent toujours abaisser le TTL mais, en dessous d'une certaine valeur (typiquement 30 à 60 minutes), les TTL trop bas sont parfois ignorés.
Un autre point où les demandes de beaucoup d'utilisateurs
rentrent en friction avec les concepts du DNS est celui des noms
privés, des noms qui n'existeraient qu'à l'intérieur d'une
organisation particulière, et qui ne nécessiteraient pas
d'enregistrement auprès d'un tiers. La bonne méthode pour avoir des
noms privés est d'utiliser un sous-domaine d'un domaine qu'on a
enregistré (aujourd'hui, tout le monde peut avoir son domaine assez
facilement, voir gratuitement), et de le déléguer à
des serveurs de noms qui ne sont accessibles qu'en interne. Si on
est l'association Example et qu'on est titulaire de
example.org, on crée
priv.example.org et on y met ensuite les noms
« privés » (je mets privé entre guillemets car, en pratique, comme
le montrent les statistiques des serveurs de noms publics, de tels
noms fuitent souvent à l'extérieur, par exemple quand un ordinateur
portable passe du réseau interne à celui d'un
FAI public).
Il faut noter que beaucoup d'organisations, au lieu d'utiliser la
bonne méthode citée ci-dessus, repèrent un
TLD actuellement inutilisé
(.home, .lan,
.private…) et s'en servent. C'est une très
mauvaise idée, car, un jour, ces TLD seront peut-être délégués, avec
les risques de confusion que cela entrainera (cf. le
cas de .box et celui
de .dev).
Les administrateurs système demandent souvent « mais quel est le
TLD réservé pour les usages internes » et sont surpris d'apprendre
qu'il n'en existe pas. C'est en partie pour de bonnes raisons
(imaginez deux entreprises utilisant ce TLD et fusionnant… Ou
simplement s'interconnectant via un VPN… Un
problème qu'on voit souvent avec le RFC 1918.)
Mais c'est aussi en partie parce que les tentatives d'en créer un se
sont toujours enlisées dans les sables de la bureaucratie (personne
n'a envie de passer dix ans de sa vie professionnelle à faire du
lobbying auprès de l'ICANN pour réserver un
tel TLD). La dernière tentative était celle de .internal
mais elle n'a pas marché.
Il y a bien un registre des noms de domaines (pas uniquement des
TLD) « à usage spécial », créé par le RFC 6761. Il a malheureusement été gelé par
l'IESG et fait l'objet de contestations (RFC 8244). Aucun des noms qu'il contient ne convient vraiment
au besoin de ceux qui voudraient des noms de domaine internes (à part
.test qui devrait logiquement être utilisé pour
les bancs de test, de développement, etc). Le RFC note qu'un des
principaux problèmes d'un tel registre est qu'il est impossible de
garder à jour tous les résolveurs de la planète quand ce registre
est modifié. On ne peut donc pas garantir qu'un nouveau TLD réservé
sera bien traité de manière spéciale par tous les résolveurs.
Une caractéristique du DNS qui a suscité beaucoup de débats, pas toujours bien informés et pas toujours honnêtes, est l'existence de la racine du DNS, et des serveurs qui la servent. Lors de la mise au point du DNS, la question s'était déjà posée, certains faisant remarquer que cette racine allait focaliser les problèmes, aussi bien techniques que politiques. L'expérience a montré qu'en fait la racine marchait bien, mais cela n'a pas évité les polémiques. Le RFC note que le sujet est très chaud : qui doit gérer un serveur racine ? Où faut-il les placer physiquement ? Si l'anycast a largement résolu la seconde question (RFC 7094), la première reste ouverte. Le RFC n'en parle pas mais, si la liste des onze (ou douze, ça dépend comment on compte) organisations qui gèrent un serveur racine n'a pas évolué depuis vingt ans, ce n'est pas pour des raisons techniques, ni parce qu'aucune organisation n'est capable de faire mieux que les gérants actuels, mais tout simplement parce qu'il n'existe aucun processus pour supprimer ou ajouter un serveur racine. Comme pour les membres permanents du Conseil de Sécurité de l'ONU, on en reste au statu quo, aussi inacceptable soit-il, simplement parce qu'on ne sait pas faire autrement.
Le problème de la gestion de la racine n'est pas uniquement celui
de la gestion des serveurs racine. Le contenu de la zone racine est
tout aussi discuté. Si les serveurs racine sont les imprimeurs du
DNS, le gérant de la zone racine en est l'éditeur. Par exemple,
combien faut-il de TLD ? Si quelqu'un veut
créer .pizza, faut-il le permettre ? Et
.xxx ? Et .vin, que le
gouvernement français avait vigoureusement
combattu ? Ou encore .home, déjà
largement utilisé informellement dans beaucoup de réseaux locaux,
mais pour lequel il y avait trois candidatures à l'ICANN (rejetées peu de
temps avant la publication du RFC). Ces
questions, qui se prêtent bien aux jeux politiciens, occupent
actuellement un bon bout des réunions
ICANN.
La base technique à ces discussions est qu'il n'y a qu'une seule racine (RFC 2826). Son contrôle va donc forcément susciter des conflits. Un autre système de nommage que le DNS, si on le concevait de nos jours, pourrait éviter le problème en évitant ces points de contrôle. Les techniques à base de chaînes de blocs comme Namecoin sont évidemment des candidates possibles. Outre les problèmes pratiques (avec Namecoin, quand on perd sa clé privée, on perd son domaine), la question de fond est « quelle gouvernance souhaite-t-on ? »
La question de la sémantique dans les noms de domaines est
également délicate. L'auteur affirme que les noms de domaines sont
(ou en tout cas devraient être) de purs identificateurs techniques,
sans sémantique. Cela permet de justifier les limites des noms (RFC 1034, section 3.5) : s'ils sont de purs
identificateurs techniques, il n'est pas nécessaire de permettre les
IDN, par exemple. On peut se contenter des
lettres ASCII, des chiffres et du
tiret, la règle dite LDH, qui vient du RFC 952. Cette règle
« Letters-Digits-Hyphen » a été une première fois
remise en cause vers 1986
lorsque 3Com a voulu son nom de domaine
3com.com (à l'époque, un nom devait commencer
par une lettre, ce qui a été changé par la norme actuelle, RFC 1123). Mais cela laisse d'autres marques sans
nom de domaine adapté, par exemple C&A
ne peut pas avoir c&a.fr. Sans parler des
cas de ceux et celles qui n'utilisent pas l'alphabet latin.
L'argument de Klensin est que ce n'est pas grave : on demande juste aux noms de domaine d'être des identificateurs uniques et non ambigus. Qu'ils ne soient pas très « conviviaux » n'est pas un problème. Inutile de dire que ce point de vue personnel ne fait pas l'unanimité.
Bien sûr, il y a aussi un aspect technique. Si on voulait, dit l'auteur ironiquement, permettre l'utilisation de la langue naturelle dans les noms de domaine, il faudrait aussi supprimer la limite de 63 caractères par composant (255 caractères pour le nom complet). Il est certain qu'il est difficile d'avoir des identificateurs qui soient à la fois utiles pour les programmes (simples, non ambigus) et pour les humains.
Le DNS n'est pas figé, et a évolué depuis ses débuts. Notamment, beaucoup de nouveaux types (RRTYPE, pour Resource Record Type) ont été créés avec le temps (cf. RFC 6895). Ce sont, par exemple :
- NAPTR (RFC 3403), système que je trouve fort compliqué et qui n'a pas eu de succès,
- URI (RFC 7553) qui permet de stocker
des URI dans le DNS (par exemple,
dig +short URI 78100.cp.bortzmeyer.frva vous donner un URI OpenStreetMap correspondant au code postal 78100), - SRV (RFC 2782), qui généralise le vieux MX en permettant une indirection depuis le nom de domaine vers un nom de serveur (hélas, HTTP est le seul protocole Internet qui, stupidement, ne l'utilise pas).
Une observation à partir de l'étude du déploiement de tous les nouveaux types d'enregistrement est que ça se passe mal : pare-feux débiles qui bloquent les types qu'ils ne connaissent pas, interfaces de gestion du contenu des zones qui ne sont jamais mises à jour (bien des hébergeurs DNS ne permettent pas d'éditer URI ou TLSA, voir simplement SRV), bibliothèques qui ne permettent pas de manipuler ces types… Cela a entrainé bien des concepteurs de protocole à utiliser le type « fourre-tout » TXT. Le RFC 5507 explique ses avantages et (nombreux) inconvénients. (Le RFC 6686 raconte comment le type générique TXT a vaincu le type spécifique SPF.)
Aujourd'hui, tout le monde et son chien a un nom de domaine. Des
noms se créent en quantité industrielle, ce qui est facilité par
l'automatisation des procédures, et le choix de certains registres
de faire des promotions commerciales. Il n'est pas exagéré de dire
que, surtout dans les nouveaux TLD ICANN, la
majorité des noms sont créés à des fins malveillantes. Il est donc
important de pouvoir évaluer la réputation d'un nom : si
mail.enlargeyourzob.xyz veut m'envoyer du
courrier, puis-je utiliser la réputation de ce domaine (ce qu'il a
fait précédemment) pour décider de rejeter le message ou pas ? Et si
un utilisateur clique sur
http://www.bitcoinspaschers.town/, le
navigateur Web doit-il l'avertir que ce domaine a mauvaise
réputation ? Le RFC, souvent nostalgique, rappelle que le modèle original du DNS,
formalisé dans le RFC 1591, était que chaque
administrateur de zone était compétent, responsable et
honnête. Aujourd'hui, chacune de ces qualités est rare et leur
combinaison est encore plus rare. L'auteur du RFC regrette que les
registres ne soient pas davantage comptables du contenu des zones
qu'ils gèrent, ce qui est un point de vue personnel et très
contestable : pour un TLD qui est un service public, ce serait une
violation du principe de neutralité.
Bref, en pratique, il est clair aujourd'hui qu'on
trouve de tout dans le DNS. Il serait donc souhaitable qu'on puisse
trier le bon grain de l'ivraie mais cela présuppose qu'on connaisse
les frontières administratives. Elles ne coïncident pas forcément
avec les frontières techniques
(.fr et
gouv.fr sont actuellement dans la même zone
alors que le premier est sous la responsabilité de
l'AFNIC et le second sous celle du
gouvernement français). Rien dans le DNS ne les indique (le
point dans un nom de domaine indique une
frontière de domaine, pas forcément une frontière de zone, encore
moins une frontière de responsabilité). Beaucoup de légendes
circulent à ce sujet, par exemple beaucoup de gens croient à tort
que tout ce qui se trouve avant les deux derniers composants d'un
nom est sous la même autorité que le nom de deuxième niveau
(cf. mon article sur l'analyse
d'un nom). Il n'y a pas actuellement de mécanisme standard et
sérieux pour déterminer les frontières de responsabilité dans un nom
de domaine. Plusieurs efforts avaient été tentés à l'IETF mais ont
toujours échoué. La moins mauvaise
solution, aujourd'hui, est la Public Suffix
List.
Beaucoup plus technique, parmi les problèmes du DNS, est celui de la taille des paquets. Car la taille compte. Il y a très très longtemps, la taille d'une réponse DNS était limitée à 512 octets. Cette limite a été supprimée en 1999 avec le RFC 2671 (c'est d'ailleurs une excellente question pour un entretien d'embauche lorsque le candidat a mis « DNS » dans la liste de ses compétences : « quelle est la taille maximale d'une réponse DNS ? »). En théorie, les réponses peuvent désormais être plus grandes (la plupart des serveurs sont configurés pour 4 096 octets) mais on se heurte à une autre limite : la MTU de 1 500 octets tend à devenir une valeur sacrée, et les réponses plus grandes que cette taille ont du mal à passer, par exemple parce qu'un pare-feu idiot bloque les fragments IP, ou parce qu'un pare-feu tout aussi crétin bloque l'ICMP, empêchant les messages Packet Too Big de passer (cf. RFC 7872).
Bref, on ne peut plus trop compter sur la fragmentation, et les serveurs limitent parfois leur réponse en UDP (TCP n'a pas de problème) à moins de 1 500 octets pour cela.
Une section entière du RFC, la 5, est consacrée au problème de la
requête inverse, c'est-à-dire comment trouver un nom de domaine en
connaissant le contenu d'un enregistrement lié à ce nom. La norme
historique prévoyait une requête spécifique pour cela, IQUERY (RFC 1035, sections 4.1.1 et 6.4). Mais elle n'a
jamais réellement marché (essentiellement parce qu'elle suppose
qu'on connaisse déjà le serveur faisant autorité… pour un nom de
domaine qu'on ne connait pas encore) et a été retirée dans le RFC 3425. Pour permettre quand même des « requêtes
inverses » pour le cas le plus demandé, la résolution d'une adresse
IP en un nom de domaine, un truc spécifique a été développé,
l'« arbre inverse »
in-addr.arpa (puis plus
tard ip6.arpa pour
IPv6). Ce truc n'utilise pas les IQUERY mais
des requêtes normales, avec le type
PTR. Ainsi, l'option -x de
dig permet à la fois de fabriquer le nom en
in-addr.arpa ou ip6.arpa
et de faire une requête de type PTR pour lui :
% dig -x 2001:678:c::1 ... ;; ANSWER SECTION: 1.0.0.0.0.0.0.0.0.0.0.0.0.0.0.0.0.0.0.0.c.0.0.0.8.7.6.0.1.0.0.2.ip6.arpa. 172796 IN PTR d.nic.fr.
Cette technique pose des problèmes dans le cas de préfixes
IPv4 ne tenant pas sur une frontière d'octets
(cas traité par le RFC 2317). Globalement,
c'est toujours resté un truc, parfois utile, souvent surestimé, mais
ne fournissant jamais un service général. Une tentative avait été
faite à l'IETF pour décrire ce truc et son
utilisation, mais elle n'a jamais abouti (draft-ietf-dnsop-reverse-mapping-considerations),
la question étant trop sensible (même écrire « des gens trouvent que
les enregistrements PTR sont utiles, d'autres personnes ne sont pas
d'accord », même une phrase comme cela ne rencontrait pas de
consensus).
Enfin, la section 7 du RFC est consacrée à un problème
difficile : le DNS ne permet pas de recherche floue. Il faut
connaitre le nom exact pour avoir les données. Beaucoup
d'utilisateurs voudraient quelque chose qui ressemble davantage à un
moteur de recherche. Ils n'ont pas d'idée
très précise sur comment ça devrait fonctionner mais ils voudraient
pouvoir taper « st quentin » et que ça arrive sur
www.saint-quentin-en-yvelines.fr. Le fait qu'il
existe plusieurs villes nommées Saint-Quentin
ne les arrête pas ; ils voudraient que ça marche « tout seul ». Le
DNS a un objectif très différent : fournir une réponse exacte à une
question non ambigüe.
Peut-être aurait-on pu développer un service de recherche floue au dessus du DNS. Il y a eu quelques réflexions à ce sujet (comme le projet IRNSS ou comme le RFC 2345) mais ce n'est jamais allé très loin. En pratique, les moteurs de recherche jouent ce rôle, sans que l'utilisateur comprenne la différence. Peu d'entre eux savent qu'un nom de domaine, ce n'est pas comme un terme tapé dans un moteur de recherche. On voit aussi bien des gens taper un nom de domaine dans la boîte de saisie du terme de recherche, que des gens utiliser le moteur de recherche comme fournisseurs d'identificateurs (« pour voir notre site Web, tapez "trucmachin" dans Google »). Le dernier clou dans le cercueil de la compréhension de la différence entre identificateur et moteur de recherche a été planté quand les navigateurs ont commencé à fusionner barre d'adresses et boite de saisie de la recherche.
L'article seul
RFC 8335: PROBE: A Utility For Probing Interfaces
Date de publication du RFC : Février 2018
Auteur(s) du RFC : R. Bonica (Juniper), R. Thomas (Juniper), J. Linkova (Google), C. Lenart (Verizon), M. Boucadair (Orange)
Chemin des normes
Réalisé dans le cadre du groupe de travail IETF intarea
Première rédaction de cet article le 23 février 2018
Pour tester qu'une machine est bien joignable, vous utilisez
ping ou, plus rigoureusement, vous envoyez
un message ICMP de type
echo, auquel la machine visée va répondre
avec un message ICMP echo reply. Ce test
convient souvent mais il a plusieurs limites. L'une des
limites de ce test est qu'il ne teste qu'une seule interface
réseau de la machine, celle par laquelle vous lui parlez (deux
interfaces, dans certains cas de routage asymétrique). Si la
machine visée est un gros routeur avec
plein d'interfaces réseau, le test ne vous dira pas si toutes
fonctionnent. D'où cette extension aux messages ICMP permettant de
spécifier l'interface qu'on veut vérifier.
A priori, ce RFC ne s'intéresse qu'aux
routeurs, les serveurs
n'ayant souvent qu'une seule interface réseau. La nouvelle
technique, nommée PROBE, n'a pas de vocation
générale, contrairement à ping, et
concernera surtout les administrateurs réseau. D'autant plus que,
comme elle est assez indiscrète, elle ne sera a priori pas ouverte
au public. Notez qu'elle permet non seulement de tester une autre
interface du routeur, mais également une interface d'une machine
directement connectée au routeur. Les scénarios d'usage proposés
sont exposés dans la section 5, une liste non limitative de cas où
ping ne suffit pas :
- Interface réseau non numérotée (pas d'adresse, ce qui est relativement courant sur les routeurs),
- Interface réseau numérotée de manière purement locale (par exemple adresse IPv6 link-local),
- Absence de route vers l'interface testée (si on veut tester l'interface d'un routeur qui fait face à un point d'échange, et que le préfixe du point d'échange n'est pas annoncé par le protocole de routage, ce qui est fréquent).
En théorie, SNMP pourrait servir au moins partiellement à ces tests mais, en pratique, c'est compliqué.
ping, la technique classique, est
très sommairement décrit dans le RFC 2151,
section 3.2, mais sans indiquer comment il fonctionne. La
méthodologie est simple : la machine de test envoie un message
ICMP Echo (type 8
en IPv4 et 128 en
IPv6) à la machine visée (l'amer). L'amer répond avec un Echo
Reply (type 0 en IPv4 et 129 en IPv6). La réception
de cet Echo Reply indique que la liaison
marche bien dans les deux sens. La non-réception indique d'un
problème s'est produit, mais on n'en sait pas plus (notamment, on
ne sait pas si le problème était à l'aller ou bien au
retour). Ici, on voit le test effectué par une sonde Atlas sur l'amer
2605:4500:2:245b::42 (l'un des serveurs hébergeant ce blog), vu par tshark :
13.013422 2a02:1811:c13:1902:1ad6:c7ff:fe2a:6ac → 2605:4500:2:245b::42 ICMPv6 126 Echo (ping) request id=0x0545, seq=1, hop limit=56
13.013500 2605:4500:2:245b::42 → 2a02:1811:c13:1902:1ad6:c7ff:fe2a:6ac ICMPv6 126 Echo (ping) reply id=0x0545, seq=1, hop limit=64 (request in 11)
ICMP est normalisé dans les RFC 792 pour IPv4 et RFC 4443 pour IPv6. L'exemple ci-dessus montre un test classique, avec une requête et une réponse.
Notre RFC parle d'« interface testée » (probed interface) et d'« interface testante » (probing interface). Dans l'exemple ci-dessus, l'interface Ethernet de l'Atlas était la testante et celle du serveur était la testée. Le succès du test montre que les deux interfaces sont actives et peuvent se parler.
Au contraire de ping, PROBE va envoyer le
message, non pas à l'interface testée mais à une interface
« relais » (proxy). Celle-ci répondra si
l'interface testée fonctionne bien (état
oper-status, cf. RFC 7223). Si l'interface testée n'est pas sur le nœud qui
sert de relais, ce dernier détermine l'état de cette interface en
regardant la table ARP (RFC 826) ou NDP (RFC 4861). Aucun test actif n'est effectué, l'interface est
considérée comme active si on lui a parlé récemment (et donc si
l'adresse IP est dans un cache). PROBE utilise, comme ping,
ICMP. Il se sert des messages ICMP structurés du RFC 4884. Une des parties du message structuré sert à
identifier l'interface testée.
L'extension à ICMP Extended Echo est décrite en section 2 du RFC. Le type de la requête est 42 pour IPv4 et 160 pour IPv6 (enregistré à l'IANA, pour IPv4 et IPv6). Parmi les champs qu'elle comprend (les deux premiers existent aussi pour l'ICMP Echo traditionnel) :
- Un identificateur qui peut servir à faire correspondre une réponse à une requête (ICMP, comme IP, n'a pas de connexion ou de session, chaque paquet est indépendant), 0x0545 dans l'exemple vu plus haut avec tshark,
- Un numéro de séquence, qui peut indiquer les paquets successifs d'un même test, 1 dans l'exemple vu plus haut avec tshark
- Un bit nommé L (local) qui indique si l'interface testée est sur le nœud visé par le test ou non,
- Une structure qui indique l'interface testée.
Cette structure suit la forme décrite dans la section 7 du RFC 4884. Elle contient un objet d'identification de l'interface. L'interface qu'on teste peut être désignée par son adresse IP (si elle n'est pas locale - bit L à zéro, c'est la seule méthode acceptée), son nom ou son index. Notez que l'adresse IP identifiant l'adresse testée n'est pas forcément de la même famille que celle du message ICMP. On peut envoyer en IPv4 un message ICMP demandant à la machine distante de tester une interface IPv6.
Plus précisément, l'objet d'identification de l'interface est composé, comme tous les objets du RFC 4884, d'un en-tête et d'une charge utile. L'en-tête contient les champs :
- Un numéro de classe, 3, stocké à l'IANA,
- Un numéro indiquant comment l'interface testée est désignée (1 =
par nom, cf. RFC 7223, 2 = par index, le même qu'en
SNMP, voir aussi le RFC 7223, section 3, le concept de
if-index, et enfin 3 = par adresse), - La longueur des données.
L'adresse est représentée elle-même par une structure à trois champs, la famille (4 pour IPv4 et 6 pour IPv6), la longueur et la valeur de l'adresse. Notez que le RFC 5837 a un mécanisme de description de l'interface, portant le numéro de classe 2, et utilisé dans un contexte proche.
La réponse à ces requêtes a le type 43 en IPv4 et 161 en IPv6 (section 3 du RFC). Elle comprend :
- Un code (il valait toujours 0 pour la requête) qui indique le résultat du test : 0 est un succès, 1 signale que la requête était malformée, 2 que l'interface à tester n'existe pas, 3 qu'il n'y a pas de telle entrée dans la table des interfaces, et 4 que plusieurs interfaces correspondent à la demande (liste complète dans un registre IANA),
- Un identificateur, copié depuis la requête,
- Un numéro de séquence, copié depuis la requête,
- Un état qui donne des détails en cas de code 0 (autrement, pas besoin de détails) : si l'interface testée n'est pas locale, l'état vaut 2 si l'entrée dans le cache ARP ou NDP est active, 1 si elle est incomplète (ce qui indique typiquement que l'interface testée n'a pas répondu), 3 si elle n'est plus à jour, etc,
- Un bit A (active) qui est mis à un si l'interface testée est locale et fonctionne,
- Un bit nommé 4 (pour IPv4) qui indique si IPv4 tourne sur l'interface testée,
- Un bit nommé 6 (pour IPv6) qui indique si IPv6 tourne sur l'interface testée.
La section 4 du RFC détaille le traitement que doit faire la machine qui reçoit l'ICMP Extended Echo. D'abord, elle doit jeter le paquet (sans répondre) si ICMP Extended Echo n'est pas explicitement activé (rappelez-vous que ce service est assez indiscret, cf. section 8 du RFC) ou bien si l'adresse IP de la machine testante n'est pas autorisée (même remarque). Si les tests sont passés et que la requête est acceptée, la machine réceptrice fabrique une réponse : le code est mis à 1 si la requête est anormale (pas de partie structurée par exemple), 2 si l'interface testée n'existe pas, 3 si elle n'est pas locale et n'apparait pas dans les tables (caches) ARP ou NDP. Si on trouve l'interface, on la teste et on remplit les bits A, 4, 6 et l'état, en fonction de ce qu'on trouve sur l'interface testée.
Reste la question de la sécurité (section 8 du RFC). Comme
beaucoup de mécanismes, PROBE peut être utilisé pour le bien
(l'administrateur réseaux qui détermine
l'état d'une interface d'un routeur dont il s'occupe), mais aussi
pour le mal (chercher à récolter des informations sur un réseau
avant une attaque, par exemple, d'autant plus que les noms
d'interfaces dans les routeurs peuvent être assez parlants,
révélant le type de réseau, le modèle de routeur…) Le RFC exige
donc que le mécanisme ICMP Extended Echo ne
soit pas activé par défaut, et soit configurable (liste blanche
d'adresses IP autorisées, permission - ou non - de tester des
interfaces non locales, protection des différents réseaux les uns
contre les autres, si on y accueille des clients différents…) Et, bien sûr, il faut pouvoir
limiter le nombre de messages.
Ne comptez pas utilise PROBE tout de suite. Il n'existe
apparemment pas de mise en œuvre de ce mécanisme
publiée. Juniper en a réalisé une mais elle
n'apparait encore dans aucune version de JunOS.
L'article seul
RFC 8315: Cancel-Locks in Netnews articles
Date de publication du RFC : Février 2018
Auteur(s) du RFC : M. Bäuerle (STZ Elektronik)
Chemin des normes
Première rédaction de cet article le 14 février 2018
Cela peut sembler étonnant, mais le service des News fonctionne toujours. Et il est régulièrement perfectionné. Ce nouveau RFC normalise une extension au format des articles qui permettra de sécuriser un petit peu l'opération d'annulation d'articles.
Une fois qu'un article est lancé sur un réseau social décentralisé,
comme Usenet (RFC 5537), que faire si on le regrette ? Dans un système
centralisé comme Twitter, c'est simple, on
s'authentifie, on le supprime et plus personne ne le voit. Mais
dans un réseau décentralisé, il faut encore propager la demande de
suppression (d'annulation, sur les News). Et cela pose évidemment
des questions de sécurité : il ne faut pas permettre aux méchants
de fabriquer trop facilement une demande d'annulation. Notre RFC
propose donc une mesure de sécurité, l'en-tête
Cancel-Lock:.
Cette mesure de sécurité est simple, et ne fournit certainement
pas une sécurité de niveau militaire. Pour la comprendre, il faut
revenir au mécanisme d'annulation d'un article
d'Usenet. Un article de contrôle est un
article comme les autres, envoyé sur
Usenet, mais il ne vise pas à être lu par les
humains, mais à être interprété par le logiciel. Un exemple
d'article de contrôle est l'article de contrôle
d'annulation, défini dans le RFC 5337, section 5.3. Comme son nom l'indique, il demande
la suppression d'un article, identifié par son Message
ID. Au début d'Usenet, ces messages de contrôle
n'avaient aucune forme d'authentification. On a donc vu apparaitre
des faux messages de contrôle, par exemple à des fins de censure
(supprimer un article qu'on n'aimait pas). Notre nouveau RFC
propose donc qu'un logiciel proche de la source du message mette
un en-tête Cancel-Lock: qui indique la clé
qui aura le droit d'annuler le message.
Évidemment, ce Cancel-Lock:
n'apporte pas beaucoup de sécurité, entre autre parce qu'un
serveur peut toujours le retirer et mettre le sien, avant de
redistribuer (c'est évidemment explicitement interdit par le RFC
mais il y a des méchants). Mais cela ne change de toute façon pas grand'chose à la situation
actuelle, un serveur peut toujours jeter un article, de toute
façon. Si on veut quand même une solution de sécurité
« sérieuse », il faut utiliser PGP, comme
mentionné en passant par le RFC 5537 (mais
jamais normalisé dans un RFC).
La section 2 du RFC décrit en détail le mécanisme de
sécurité. La valeur de l'en-tête Cancel-Lock:
est l'encodage en base64 d'une
condensation d'une clé secrète (en fait, on
devrait plutôt l'appeler mot de passe). Pour authentifier une
annulation, le message de contrôle comportera un autre en-tête,
Cancel-Key:, qui révélera la clé (qui ne
devra donc être utilisée qu'une fois).
Voici un exemple. On indique explicitement l'algorithme de condensation (ici, SHA-256, la liste est dans un registre IANA). D'abord, le message original aura :
Cancel-Lock: sha256:s/pmK/3grrz++29ce2/mQydzJuc7iqHn1nqcJiQTPMc=
Et voici le message de contrôle, authentifié :
Cancel-Key: sha256:qv1VXHYiCGjkX/N1nhfYKcAeUn8bCVhrWhoKuBSnpMA=
La section 3 du RFC détaille comment on utilise ces
en-têtes. Le Cancel-Lock: peut être mis par
l'auteur originel de l'article, ou bien par un intermédiaire (par
exemple le modérateur qui a approuvé
l'article). Plusieurs Cancel-Lock: peuvent
donc être présents. Notez qu'il n'y a aucun moyen de savoir si le
Cancel-Lock: est « authentique ». Ce
mécanisme est une solution de sécurité faible.
Pour annuler un message, on envoie un message de contrôle avec
un Cancel-Key: correspondant à un des
Cancel-Lock:. Les serveurs recevant ce
message de contrôle condenseront la clé (le
mot de passe) et vérifieront s'ils retombent bien sur le condensat
contenu dans un des Cancel-Lock:.
La section 4 donne les détails sur le choix de la clé (du mot
de passe). Évidemment, elle doit être difficile à deviner, donc
plutôt choisie par un algorithme pseudo-aléatoire (et pas "azerty123"). Et elle doit être à
usage unique puisque, une fois révélée par un
Cancel-Key:, elle n'est plus
secrète. L'algorithme recommandé par le RFC est d'utiliser un
HMAC (RFC 2104) d'un
secret et de la concaténation du Message ID du message
avec le nom de l'utilisateur. Comme cela, générer un
Cancel-Key: pour un message donné peut se
faire avec juste le message, sans avoir besoin de mémoriser les
clés. Voici un exemple, tiré de la section 5, et utilisant OpenSSL. Le secret est
frobnicateZ32. Le message est le
<12345@example.net> et l'utilisateur est
stephane :
% printf "%s" "<12345@example.net>stephane" \
| openssl dgst -sha256 -hmac "frobnicateZ32" -binary \
| openssl enc -base64
f0rHwfZXp5iKFjTbX/I5bQXh9Dta33nWBzLi8f9oaoM=
Voilà, nous avons notre clé,
f0rHwfZXp5iKFjTbX/I5bQXh9Dta33nWBzLi8f9oaoM=. Pour
le condensat, nous nous servirons de
SHA-256 :
% printf "%s" "f0rHwfZXp5iKFjTbX/I5bQXh9Dta33nWBzLi8f9oaoM=" \
| openssl dgst -sha256 -binary \
| openssl enc -base64
RBJ8ZsgqBnW/tYT/qu1JcXK8SA2O9g+qJLDzRY5h1cg=
Nous pouvons alors former le Cancel-Lock: :
Cancel-Lock: sha256:RBJ8ZsgqBnW/tYT/qu1JcXK8SA2O9g+qJLDzRY5h1cg=
Et, si nous voulons annuler ce message, le
Cancel-Key: dans le message de contrôle
d'annulation aura l'air :
Control: cancel <12345@example.net>
Cancel-Key: sha256:f0rHwfZXp5iKFjTbX/I5bQXh9Dta33nWBzLi8f9oaoM=
Pour vérifier ce message de contrôle, le logiciel calculera le
condensat de la clé et vérifiera s'il retombe bien sur RBJ8ZsgqBnW/tYT/qu1JcXK8SA2O9g+qJLDzRY5h1cg=.
Enfin, la section 7 du RFC détaille la sécurité de ce mécanisme. Cette sécurité est plutôt faible :
- Aucune protection de
l'intégrité. Un intermédiaire a pu
modifier, ajouter ou supprimer le
Control-Lock:. Si cela vous défrise, vous devez utiliser PGP. - Lors d'une annulation, la clé est visible par tous, donc elle peut être copiée et utilisée dans un message de contrôle de remplacement (au lieu de l'annulation). Mais, de toute façon, un attaquant peut aussi bien faire un nouveau message faux (Usenet ne vérifie pas grand'chose).
- Avant ce RFC, ce mécanisme était déjà largement utilisé, depuis longtemps, et souvent en utilisant SHA-1 comme fonction de condensation. Contrairement à ce qu'on lit parfois, SHA-1 n'est pas complètement cassé : il n'y a pas encore eu de publication d'une attaque pré-image pour SHA-1 (seulement des collisions). Néanmoins, SHA-1 ne peut plus être considéré comme sûr, d'autant plus que Usenet évolue très lentement : un logiciel fait aujourd'hui va rester en production longtemps et, avec le temps, d'autres attaques contre SHA-1 apparaitront. D'où la recommandation du RFC de n'utiliser que SHA-2.
Les deux nouveaux en-têtes ont été ajoutés au registre des en-têtes.
À noter que, comme il n'y a pas de groupe de travail IETF sur les
News, ce RFC a été surtout discuté… sur les
News, en l'occurrence les groupes
news.software.nntp et
de.comm.software.newsserver. Comme ce RFC
décrit une technique ancienne, il y a déjà de nombreuses mises en
œuvre comme celle de
gegeweb, la bibliothèque
canlock (paquetage Debian
libcanlock2), dans le
serveur INN, ou les clients News
Gnus (regardez cet
article sur son usage), flnews,
slrn ou tin. Vous pouvez aussi lire l'article
de Brad Templeton comparant
Cancel-Lock: aux signatures.
Merci à Julien Élie pour sa relecture.
L'article seul
Meltdown & Spectre
First publication of this article on 10 February 2018
I didn't write about the hardware security vulnerabilities Meltdown and Spectre but André Sintzoff did and he asked for a place to put this online so, I host it here.
L'article seul
RFC 8304: Transport Features of the User Datagram Protocol (UDP) and Lightweight UDP (UDP-Lite)
Date de publication du RFC : Février 2018
Auteur(s) du RFC : G. Fairhurst, T. Jones (University of Aberdeen)
Pour information
Réalisé dans le cadre du groupe de travail IETF taps
Première rédaction de cet article le 8 février 2018
Le RFC 8303, du groupe de travail TAPS, décrit les fonctions et services rendus par les protocoles de transport aux applications. Ce RFC 8304 se focalise sur deux protocoles sans connexion, UDP et UDP-Lite. Quels services fournissent-ils ?
UDP est normalisé dans le RFC 768 et UDP-Lite dans le RFC 3828. Tous les deux permettent l'envoi et la réception de datagrammes, sans connexion préalable, sans garantie d'être prévenu en cas de perte du datagramme, sans garantie qu'ils soient distribués dans l'ordre. Une application qui utilise UDP va donc devoir connaitre les services exacts que ce protocole fournit. Aujourd'hui, de nombreuses applications utilisent UDP, l'une des plus connues étant sans doute le DNS, sans compter celles qui utilisent un autre protocole de transport mais qui l'encapsulent dans UDP pour passer les boitiers intermédiaires (cf. par exemple RFC 8261). UDP-Lite est très proche d'UDP et ajoute juste la possibilité de distribuer à l'application des paquets potentiellement endommagés. Pour utiliser UDP intelligement, les programmeurs ont tout intérêt à consulter le RFC 8085.
L'API la plus courante est
l'API dite « socket », normalisée par
POSIX, et dont la meilleure documentation
est évidemment le livre de
Stevens. Les applications peuvent envoyer des données avec
send(),
sendto() et
sendmsg(), en recevoir avec
recvfrom() et
recvmsg(). Elles peuvent être
dans l'obligation de configurer certaines informations de bas
niveau comme la permission de fragmenter ou
pas, alors que TCP gère cela tout seul.
Des options existent dans l'API socket pour
définir ces options.
Notre RFC 8304 suit la démarche du RFC 8303 pour la description d'un protocole de transport. Plus précisement, il suite la première passe, celle de description de ce que sait faire le protocole.
Donc, pour résumer (section 3 du RFC), UDP est décrit dans le RFC 768, et UDP-Lite dans le RFC 3828. Tous les deux fournissent un service de datagramme, non connecté, et qui préserve les frontières de message (contrairement à TCP, qui envoie un flot d'octets). Le RFC 768 donne quelques idées sur l'API d'UDP, il faut notamment que l'application puisse écouter sur un port donné, et puisse choisir le port source d'envoi.
UDP marche évidemment également sur IPv6, et une extension à l'API socket pour IPv6 est décrite dans le RFC 3493.
UDP est très basique : aucun contrôle de congestion (le RFC 8085 détaille ce point), pas de retransmission des paquets perdus, pas de notification des pertes, etc. Tout doit être fait par l'application. On voit que, dans la grande majorité des cas, il vaut mieux utiliser TCP. Certains développeurs utilisent UDP parce qu'ils ont lu quelque part que c'était « plus rapide » mais c'est presque toujours une mauvaise idée.
Notre RFC décrit ensuite les primitives UDP utilisables par les applications :
CONNECTest très différent de celui de TCP. C'est une opération purement locale (aucun paquet n'est envoyé sur le réseau), qui associe des ports source et destination à une prise (socket), c'est tout. Une fois cette opération faite, on pourra envoyer ou recevoir des paquets. CommeCONNECT,CLOSEn'a d'effet que local (pas de connexion, donc pas de fermeture de connexion).SENDetRECEIVE, dont le nom indique bien ce qu'elles font.SET_IP_OPTIONSqui permet d'indiquer des options IP, chose qui n'est en général pas nécessaire en TCP mais peut être utile en UDP.SET_DFest important car il permet de contrôler la fragmentation des paquets. TCP n'en a pas besoin car la MSS est négociée au début de la connexion. Avec UDP, c'est le programmeur de l'application qui doit choisir s'il laissera le système d'exploitation et les routeurs (en IPv4 seulement, pour les routeurs) fragmenter, ce qui est risqué, car pas mal de pare-feux mal configurés bloquent les fragments, ou bien s'il refusera la fragmentation (DF = Don't Fragment) et devra donc faire attention à ne pas envoyer des paquets trop gros. (Voir aussi les RFC 1191 et RFC 8201 pour une troisième possibilité.)SET_TTL(IPv4) etSET_IPV6_UNICAST_HOPSpermettent de définir le TTL des paquets IP envoyés. (Le terme de TTL est objectivement incorrect, et est devenu hops en IPv6, mais c'est le plus utilisé.)SET_DSCPpermet de définir la qualité de service souhaitée (RFC 2474).SET_ECNpermet de dire qu'on va utiliser ECN (RFC 3168). Comme les précédentes, elle n'a pas de sens en TCP, où le protocole de transport gère cela seul.- Enfin, dernière primitive citée par le RFC, la demande de notification des erreurs. Elle sert à réclamer qu'on soit prévenu de l'arrivée des messages ICMP.
Certaines primitives ont été exclues de la liste car n'étant plus d'actualité (cf. le RFC 6633).
Avec ça, on n'a parlé que d'UDP et pas d'UDP-Lite. Rappelons
qu'UDP-Lite (RFC 3828) est à 95 % de l'UDP
avec un seul changement, la possibilité que la somme de
contrôle ne couvre qu'une partie du paquet. Il faut
donc une primtive SET_CHECKSUM_COVERAGE qui
indique jusqu'à quel octet le paquet est couvert par la somme de
contrôle.
Notez enfin que le RFC se concentre sur l'unicast mais, si cela vous intéresse, l'annexe A décrit le cas du multicast.
L'article seul
RFC 8303: On the Usage of Transport Features Provided by IETF Transport Protocols
Date de publication du RFC : Février 2018
Auteur(s) du RFC : M. Welzl (University of Oslo), M. Tuexen (Muenster Univ. of Appl. Sciences), N. Khademi (University of Oslo)
Pour information
Réalisé dans le cadre du groupe de travail IETF taps
Première rédaction de cet article le 8 février 2018
La famille de protocoles TCP/IP dispose d'un grand nombre de protocoles de transport. On connait bien sûr TCP mais il y en a d'autres comme UDP et SCTP et d'autres encore moins connus. Cette diversité peut compliquer la tâche des développeurs d'application, qui ne savent pas toujours bien lequel choisir. Et elle pose également problème pour les développements futurs à l'IETF, par exemple la réflexion en cours sur les API. On a besoin d'une description claire des services que chaque protocole fournit effectivement. C'est le but du groupe de travail TAPS dont voici le deuxième RFC : une description de haut niveau des services que fournit la couche transport. À faire lire à tous les développeurs d'applications réseau, à tous les participants à la normalisation, et aux étudiants en réseaux informatiques.
Ce RFC parle de TCP, MPTCP, SCTP, UDP et UDP-Lite, sous l'angle « quels services rendent-ils aux applications ? » (QUIC, pas encore normalisé à l'époque, n'y figure pas. LEDBAT, qui n'est pas vraiment un protocole de transport, est par contre présent.) L'idée est de lister un ensemble d'opérations abstraites, qui pourront ensuite être exportées dans une API. J'en profite pour recommander la lecture du RFC 8095, premier RFC du groupe TAPS.
La section 1 de notre RFC décrit la terminologie employée. Il faut notamment distinguer trois termes :
- La fonction (Transport Feature) qui désigne une fonction particulière que le protocole de transport va effectuer, par exemple la confidentialité, la fiabilité de la distribution des données, le découpage des données en messages, etc.
- Le service (Transport Service) qui est un ensemble cohérent de fonctions. C'est ce que demande l'application.
- Le protocole (Transport Protocol) qui est une réalisation concrète d'un ou plusieurs services.
Un exemple de programme qui permet d'essayer différents types
de prises (sockets) est socket-types.c. Vous pouvez le compiler et le lancer en
indiquant le type de service souhaité. STREAM
va donner du TCP, SEQPACKET du SCTP,
DATAGRAM de l'UDP :
% make socket-types
cc -Wall -Wextra socket-types.c -o socket-types
% ./socket-types -v -p 853 9.9.9.9 STREAM
9.9.9.9 is an IP address
"Connection" STREAM successful to 9.9.9.9
% ./socket-types -v -p 443 -h dns.bortzmeyer.org STREAM
Address(es) of dns.bortzmeyer.org is(are): 2605:4500:2:245b::42 204.62.14.153
"Connection" STREAM successful to 2605:4500:2:245b::42
256 response bytes read
À première vue, l'API sockets nous permet
de sélectionner le service, indépendamment du protocole qui le
fournira. Mais ce n'est pas vraiment le cas. Si on veut juste un
flot de données, cela pourrait être fait avec TCP ou SCTP, mais
seul TCP sera sélectionné si on demande
STREAM. En fait, les noms de services dns
l'appel à socket() sont toujours
en correspondance univoque avec les protocoles de transport.
Autres termes importants :
- Adresse (Transport Address) qui est un tuple regroupant adresse IP, nom de protocole et numéro de port. Le projet TAPS considère uniquement des protocoles ayant la notion de ports, et fournissant donc la fonction de démultiplexage (différencier les données destinées à telle ou telle application).
- Primitive (Primitive), un moyen pour l'application de demander quelque chose au protocole de transport.
- Événement (Event), généré par le protocole de transport, et transmis à l'application pour l'informer.
La section 2 décrit le problème général. Actuellement, les applications sont liées à un protocole, même quand elles ne le souhaitent pas. Si une application veut que ses octets soient distribués dans l'ordre, et sans pertes, plusieurs protocoles peuvent convenir, et il n'est pas forcément utile de se limiter à seulement TCP, par exemple. Pour avancer vers un moindre couplage entre application et protocole, ce RFC décrit les fonctions et les services, un futur RFC définira des services minimaux, un autre peut-être une API.
Le RFC essaie de s'en tenir au minimum, des options utiles mais pas indispensables (comme le fait pour l'application de demander à être prévenue de certains changements réseau, cf. RFC 6458) ne sont pas étudiées.
Le RFC procède en trois passes : la première (section 3 du RFC)
analyse et explique ce que chaque protocole permet, la seconde (section 4) liste les
primitives et événements possibles, la troisième (section 5) donne
pour chaque fonction les protocoles qui la mettent en œuvre. Par
exemple, la passe 1 note que TCP fournit à l'application un moyen
de fermer une connexion en cours, la passe 2 liste une primitive
CLOSE.TCP, la passe 3 note que TCP et SCTP
(mais pas UDP) fournissent cette opération de fermeture (qui fait
partie des fonctions de base d'un protocole orienté connexion,
comme TCP). Bon, d'accord, cette méthode est un peu longue et elle rend le RFC pas
amusant à lire mais cela permet de s'assurer que rien n'a été
oublié.
Donc, section 3 du RFC, la passe 1. Si vous connaissez bien tous ces
protocoles, vous pouvez sauter cette section. Commençons par le
protocole le plus connu, TCP (RFC 793). Tout le monde sait que c'est un
protocole à connexion, fournissant un transport fiable et ordonné
des données. Notez que la section 3.8 de la norme TCP décrit,
sinon une API, du moins l'interface (les primitives) offertes aux
applications. Vous verrez que les noms ne correspondent pas du
tout à celle de l'API sockets
(OPEN au lieu de
connect/listen, SEND au lieu de
write, etc).
TCP permet donc à l'application d'ouvrir une connexion (activement - TCP se connecte à un TCP distant - ou passivement - TCP attend les connexions), d'envoyer des données, d'en recevoir, de fermer la connexion (gentiment - TCP attend encore les données de l'autre - ou méchamment - on part en claquant la porte). Il y a aussi des événements, par exemple la fermeture d'une connexion déclenchée par le pair, ou bien une expiration d'un délai de garde. TCP permet également de spécifier la qualité de service attendue (cf. RFC 2474, et la section 4.2.4.2 du RFC 1123). Comme envoyer un paquet IP par caractère tapé serait peu efficace, TCP permet, pour les sessions interactives, genre SSH, d'attendre un peu pour voir si d'autres caractères n'arrivent pas (algorithme de Nagle, section 4.2.3.4 du RFC 1123). Et il y a encore d'autres possibilités moins connues, comme le User Timeout du RFC 5482. Je vous passe des détails, n'hésitez pas à lire le RFC pour approfondir, TCP a d'autres possibilités à offrir aux applications.
Après TCP, notre RFC se penche sur MPTCP. MPTCP crée plusieurs connexions TCP vers le pair, utilisant des adresses IP différentes, et répartit le trafic sur ces différents chemins (cf. RFC 6182). Le modèle qu'il présente aux applications est très proche de celui de TCP. MPTCP est décrit dans les RFC 6824 et son API est dans le RFC 6897. Ses primitives sont logiquement celles de TCP, plus quelques extensions. Parmi les variations par rapport à TCP, la primitive d'ouverture de connexion a évidemment une option pour activer ou pas MPTCP (sinon, on fait du TCP normal). Les extensions permettent de mieux contrôler quelles adresses IP on va utiliser pour la machine locale.
SCTP est le principal concurrent de TCP sur le créneau « protocole de transfert avec fiabilité de la distribution des données ». Il est normalisé dans le RFC 9260. Du point de vue de l'application, SCTP a trois différences importantes par rapport à TCP :
- Au lieu d'un flot continu d'octets, SCTP présent une suite de messages, avec des délimitations entre eux,
- Il a un mode où la distribution fiable n'est pas garantie,
- Et il permet de tirer profit du multi-homing.
Il a aussi une terminologie différente, par exemple on parle d'associations et plus de connexions.
Certaines primitives sont donc différentes : par exemple,
Associate au lieu du
Open TCP. D'autres sont identiques, comme
Send et Receive. SCTP
fournit beaucoup de primitives, bien plus que TCP.
Et UDP ? Ce protocole sans connexion, et sans fiabilité, ainsi que sa variante UDP-Lite, est analysé dans un RFC séparé, le RFC 8304.
Nous passons ensuite à LEDBAT (RFC 6817). Ce n'est pas vraiment un protocole de transport, mais plutôt un système de contrôle de la congestion bâti sur l'idée « décroissante » de « on n'utilise le réseau que si personne d'autre ne s'en sert ». LEDBAT est pour les protocoles économes, qui veulent transférer des grandes quantités de données sans gêner personne. Un flot LEDBAT cédera donc toujours la place à un flot TCP ou compatible (RFC 5681). N'étant pas un protocole de transport, LEDBAT peut, en théorie, être utilisé sur les protocoles existants comme TCP ou SCTP (mais les extensions nécessaires n'ont hélas jamais été spécifiées). Pour l'instant, les applications n'ont pas vraiment de moyen propre d'activer ou de désactiver LEDBAT.
Bien, maintenant, passons à la deuxième passe (section 4 du RFC). Après la description des protocoles lors de la première passe, cette deuxième passe liste explicitement les primitives, rapidement décrites en première passe, et les met dans différentes catégories (alors que la première passe classait par protocole). Notons que certaines primitives, ou certaines options sont exclues. Ainsi, TCP a un mécanisme pour les données urgentes (RFC 793, section 3.7). Il était utilisé pour telnet (cf. RFC 854) mais n'a jamais vraiment fonctionné de manière satisfaisante et le RFC 6093 l'a officiellement exclu pour les nouvelles applications de TCP. Ce paramètre n'apparait donc pas dans notre RFC, puisque celui-ci vise le futur.
La première catégorie de primitives concerne la gestion de connexion. On y trouve d'abord les primitives d'établissement de connexion :
CONNECT.TCP: établit une connexion TCP,CONNECT.SCTP: idem pour SCTP,CONNECT.MPTCP: établit une connexion MPTCP,CONNECT.UDP: établit une « connexion » UDP sauf, que, UDP étant sans connexion, il s'agit cette fois d'une opération purement locale, sans communication avec une autre machine.
Cette catégorie comprend aussi les primitives permettant de
signaler qu'on est prêt à recevoir une connexion,
LISTEN.TCP, celles de maintenance de la
connexion, qui sont bien plus variées, et celles permettant de
mettre fin à la connexion (comme CLOSE.TCP et
CLOSE.SCTP, ou comme le signal qu'un délai de
garde a été dépassé, TIMEOUT.TCP).
Dans les primitives de maintenance, on trouve aussi bien les
changements du délai de garde
(CHANGE_TIMEOUT.TCP et
SCTP), le débrayage de
l'algorithme de Nagle, pour TCP et SCTP,
l'ajout d'une adresse IP locale à l'ensemble des adresses
utilisables (ADD_PATH.MPTCP et
ADD_PATH.SCTP), la notification d'erreurs,
l'activation ou la désactivation de la somme de
contrôle (UDP seulement, la somme de contrôle étant
obligatoire pour les autres)… La plupart sont spécifiques à SCTP,
le protocole le plus riche.
La deuxième catégorie rassemble les primitives liées à la
transmission de données. On y trouve donc
SEND.TCP (idem pour SCTP et UDP),
RECEIVE.TCP (avec ses équivalents SCTP et
UDP), mais aussi les signalements d'échec comme
SEND_FAILURE.UDP par exemple quand on a reçu
un message ICMP d'erreur.
Venons-en maintenant à la troisième passe (section 5 du RFC). On va cette fois lister les primitives sous forme d'un concept de haut niveau, en notant les protocoles auxquels elles s'appliquent. Ainsi, pour la gestion des connexions, on aura de quoi se connecter : une primitive Connect, qui s'applique à plusieurs protocoles (TCP, SCTP et UDP, même si Connect ne se réalise pas de la même façon pour tous ces protocoles). Et de quoi écouter passivement : une primitive Listen. Pour la maintenance, on aura une primitive Change timeout, qui s'applique à TCP et SCTP, une Disable Nagle qui s'applique à TCP et SCTP, une Add path qui a un sens pour MPTCP et SCTP, une Disable checksum qui ne marche que pour UDP, etc.
Pour l'envoi de données, on ne fusionne pas les opérations
d'envoi (SEND.PROTOCOL) de la passe
précédente car elles ont une sémantique trop différente. Il y a
Reliably transfer data pour TCP, et
Reliably transfer a message pour SCTP. (Et bien
sûr Unreliably transfer a message avec UDP.)
Voilà, tout ça a l'air un peu abstrait mais ça acquerra davantage de sens quand on passera aux futures descriptions d'API (voir le RFC 8923).
L'annexe B du RFC explique la méthodologie suivie pour l'élaboration de ce document : coller au texte des RFC, exclure les primitives optionnelles, puis les trois passes dont j'ai parlé plus tôt. C'est cette annexe, écrite avant le RFC, qui avait servi de guide aux auteurs des différentes parties (il fallait des spécialistes SCTP pour ne pas faire d'erreurs lors de la description de ce protocole complexe…)
Notez (surtout si vous avez lu le RFC 8095) que TLS n'a pas été inclus, pas parce que ce ne serait pas un vrai protocole de transport (ça se discute) mais car il aurait été plus difficile à traiter (il aurait fallu des experts en sécurité).
L'article seul
RFC 8312: CUBIC for Fast Long-Distance Networks
Date de publication du RFC : Février 2018
Auteur(s) du RFC : I. Rhee (NCSU), L. Xu (UNL), S. Ha (Colorado), A. Zimmermann, L. Eggert (NetApp), R. Scheffenegger
Pour information
Réalisé dans le cadre du groupe de travail IETF tcpm
Première rédaction de cet article le 8 février 2018
Longtemps après sa mise au point et son déploiement massif sur Linux, voici la description officielle de l'algorithme CUBIC, un algorithme de contrôle de la congestion dans TCP. (Cette description a depuis été remplacée par celle du RFC 9438.)
CUBIC doit son nom au fait que la fonction de calcul de la fenêtre d'envoi des données est une fonction cubique (elle a un terme du troisième degré) et non pas linéaire. CUBIC est l'algorithme utilisé par défaut dans Linux depuis pas mal d'années :
% sudo sysctl net.ipv4.tcp_congestion_control
net.ipv4.tcp_congestion_control = cubic
CUBIC est plus énergique lorsqu'il s'agit d'agrandir la fenêtre d'envoi de données, lorsque le réseau a une grande capacité mais un RTT important. Dans le cas de ces réseaux « éléphants » (terme issu de la prononciation en anglais de LFN, Long and Fat Network, voir RFC 7323, section 1.1), le RTT élevé fait que l'émetteur TCP met du temps à recevoir les accusés de réception, et donc à comprendre que tout va bien et qu'il peut envoyer davantage de données, pour remplir le long tuyau. CUBIC permet d'accélérer cette phase.
Notez que CUBIC ne contrôle que l'émetteur, le récepteur est inchangé. Cela facilite le déploiement : un émetteur CUBIC peut parfaitement communiquer avec un récepteur traditionnel.
Avant de lire la suite du RFC, il est recommandé de (re)lire le RFC 5681, la bible sur le contrôle de congestion TCP, et notamment sur cette notion de fenêtre d'envoi (ou fenêtre de congestion).
TCP (RFC 793) a évidemment une mission difficile. L'intérêt de l'émetteur est d'envoyer le plus de données le plus vite possible. Mais à condition qu'elles arrivent sinon, s'il y a de la congestion, les données seront perdues et il faudra recommencer (ré-émettre). Et on n'est pas tout seul sur le réseau : il faut aussi tenir compte des autres, et chercher à partager équitablement l'Internet. L'algorithme doit donc être énergique (chercher à utiliser les ressources au maximum) mais pas bourrin (il ne faut pas dépasser le maximum), tout en étant juste (on n'est pas dans la startup nation, il ne faut pas écraser les autres, mais partager avec eux).
Le problème des éléphants, des réseaux à fort BDP, est connu depuis longtemps (article de T. Kelly, « Scalable TCP: Improving Performance in HighSpeed Wide Area Networks », et RFC 3649.) Dans ces réseaux, TCP tend à être trop prudent, à ouvrir sa fenêtre (les données qu'on peut envoyer tout de suite) trop lentement. Cette prudence l'honore, mais peut mener à des réseaux qui ne sont pas utilisés à fond. L'article de Ha, S., Kim, Y., Le, L., Rhee, I., et L. Xu, « A Step toward Realistic Performance Evaluation of High-Speed TCP Variants » expose ce problème. Il touche toutes les variantes de TCP depuis le TCP Reno décrit dans le RFC 5681 : le New Reno des RFC 6582 et RFC 6675, et même des protocoles non-TCP mais ayant le même algorithme, comme UDP (TFRC, RFC 5348) ou SCTP (RFC 9260).
CUBIC a été originellement documenté dans l'article de S. Ha, Injong Rhee, et Lisong Xu, « CUBIC: A New TCP-Friendly High-Speed TCP Variant », en 2008. Sur Linux, il a remplacé BIC pour les réseaux à haut BDP.
La section 3 du RFC rappelle les principes de conception de CUBIC, notamment :
- Utilisation de la partie concave (la fenêtre s'agrandit rapidement au début puis plus lentement ensuite) et de la partie convexe de la fonction, et pas seulement la partie convexe (on ouvre la fenêtre calmement puis on accélère), comme l'ont tenté la plupart des propositions alternatives. Si vous avez du mal avec les termes concave et convexe, la figure 2 de cet article de comparaison de CUBIC et BIC illustre bien, graphiquement, ces concepts. La courbe est d'abord concave, puis convexe.
- Comportement identique à celui de ses prédécesseurs pour les liaisons à faible RTT (ou faible BDP). Les algorithmes TCP traditionnels n'ont en effet pas de problème dans ce secteur (cf. section 4.2, et Floyd, S., Handley, M., et J. Padhye, « A Comparison of Equation-Based and AIMD Congestion Control »). « Si ce n'est pas cassé, ne le réparez pas. » CUBIC ne se différencie donc des autres algorithmes que pour les réseaux à RTT élevé, ce que rappelle le titre de notre RFC.
- Juste partage de la capacité entre des flots ayant des RTT différents.
- CUBIC mène à un agrandissement plus rapide de la fenêtre d'envoi, mais également à une réduction moins rapide lorsqu'il détecte de la congestion (paramètre « beta_cubic », le facteur de réduction de la fenêtre, voir aussi le RFC 3649.)
La section 4 du RFC spécifie précisement l'algorithme, après beaucoup de discussion avec les développeurs du noyau Linux (puisque le code a été écrit avant le RFC). Cette section est à lire si vous voulez comprendre tous les détails. Notez l'importance du point d'inflexion entre la partie concave et la partie convexe de la courbe qui décrit la fonction de changement de taille de la fenêtre. Ce point d'inflexion est mis à la valeur de la fenêtre d'envoi juste avant la dernière fois où TCP avait détecté de la congestion.
Notez que Linux met en outre en œuvre l'algorithme HyStart, décrit dans « Taming the Elephants: New TCP Slow Start ». Hystart mesure le RTT entre émetteur et récepteur pour détecter (par l'augmentation du RTT) un début de congestion avant que des pertes de paquets se produisent. (Merci à Lucas Nussbaum pour l'information.)
La section 5 analyse le comportement CUBIC selon les critères de comparaison des algorithmes de contrôle de la congestion décrits dans le RFC 5033.
Pour finir, voici une intéressante comparaison des algorithmes de contrôle de congestion.
L'article seul
Les fake news n'existent pas (et c'est vrai)
Première rédaction de cet article le 2 février 2018
Le terme de fake news est à la mode en ce moment. Des sociologues en parlent, les médias s'inquiètent, les politiciens proposent des lois répressives. Pourtant, il n'y a aucun phénomène nouveau, juste le bon vieux mensonge, qui est pratiqué par beaucoup, y compris ceux qui dénoncent vertueusement les fake news.
Déjà, pourquoi en parler en anglais ? Utiliser l'anglais quand des termes parfaits existent en français (selon le cas : mensonge, désinformation, tromperie, propagande), c'est toujours pour brouiller les pistes, pour gêner la réflexion. Ici, le but de ceux qui utilisent cet anglicisme est clair : faire croire qu'il s'agit d'un phénomène nouveau (alors que le mensonge est aussi ancien que la communication), et laisser entendre qu'il est spécifique à l'Internet. Ceux qui brandissent le terme de fake news à tout bout de champ sont en général ceux qui n'ont jamais digéré que l'Internet permette l'accès à d'autres sources d'information.
Les médias qui se veulent officiels ont en effet une classification simple : ce qu'ils écrivent, c'est la vérité, le reste, ce sont des fake news. Regardez par exemple ce titre incroyable sur les « médias légitimes » (les autres sont-ils « illégitimes » ?). Et le reste de l'article est à l'avenant, considérant qu'il n'y a rien entre « médias traditionnels » et « rumeurs ».
Les GAFA, régulièrement accusés par les politistes et par les médias traditionnels, veulent également montrer que la sélection des faits, ils connaissent. Facebook se propose donc de faire la police. Il y a un large accord pour demander un filtrage des informations par les GAFA, et tant pis pour la liberté d'expression.
La diabolisation des fake news pose d'autres problèmes. Par exemple, le problème est souvent présenté de manière binaire : il y a le vrai (les discours du Président de la République, les éditoriaux du Point, les communiqués de la Préfecture de Police) et le faux (le reste). En réalité, entre les mensonges les plus énormes (les armes de destruction massive de Saddam Hussein, par exemple) et les vérités les plus incontestables (le Soleil se lève à l'Est), il y a de la place pour beaucoup de choses, qu'on ne peut pas ranger dans deux catégories bien distinctes. Il y a les faits dont on n'est réellement pas sûrs, ceux où l'analyse est complexe (le « trou de la Sécu »), et des opinions, qui sont variables, sans que certaines soient vraies et d'autres fausses. C'est pour cela que réguler les fake news par la loi (comme exigé par Macron) est dangereux : on passe vite de la lutte contre les fake news à celle contre les opinions qu'on n'aime pas (sans compter le travers bien français de faire une énième loi alors qu'il existe déjà des lois réprimant les fausses nouvelles, comme la loi sur la presse, qui inclut entre autres la protection contre la diffamation).
Mais les mensonges et la désinformation, ça existe bien, non ? Oui, cela existe, et cela existait bien avant l'Internet, Facebook et RT. Mais, d'abord, c'est pratiqué par tous les « camps ». Voir les hommes politiques réclamer une lutte contre les fake news, c'est amusant. Si on interdit les mensonges, les campagnes électorales vont être bien silencieuses. De même, demander qu'on ne croie que l'information officielle n'est pas une solution : les gouvernements peuvent également mentir ou se tromper, et c'est la même chose pour les médias traditionnels. (Le nombre d'énormités qu'on lit dans ces médias dès qu'il s'agit d'un sujet qu'on connaît bien…)
Ensuite, le fait qu'il y ait des mensonges (Sputnik et Breitbart les alignent en quantité impressionnante) ne signifie pas que toute révélation d'un média non-officiel soit un mensonge. De même que l'existence de ridicules complotistes ne veut pas dire qu'il n'existe pas de vrais complots. (Mon exemple favori est l'Iran-Contra Gate.)
Il y a bien sûr de bonnes idées qui circulent dans ce débat, par exemple qu'il est crucial d'avoir une analyse critique de l'information (de toute information, y compris de celle qui vient des médias officiels). L'infographie de l'IFLA est plutôt bien faite. (Notez que la traduction française comportait une énorme erreur, fact-checking traduit par « vérification rapide ». Erreur amusante lorsqu'il s'agit de lutter contre les faux. L'IFLA a modifié cette traduction après la publication de cet article.)
L'important, plutôt que les mouvements de menton (« il faut une loi contre les fake news ») ou que les avis dangereux (« il ne faut croire que l'information officielle ») est de développer les capacités d'analyse critique (« critique » au sens de « penser par soi-même », pas au sens de « jamais d'accord »). Cette capacité d'analyse critique doit s'exercer contre tous les médias et toutes les sources d'information, pas uniquement Internet, habituel grand méchant dans les discours des gens au pouvoir.
Mais en ce qui concerne spécifiquement Internet, il y a aussi des progrès à faire, rentrant dans le cadre général de la littératie numérique. La plus importante me semble la capacité à juger de la provenance de l'information. Si quelqu'un dit « j'ai trouvé cette information sur le Web », c'est clairement un problème (il n'a même pas identifié le site sur lequel il était). Il y a déjà un gros travail à faire en ce sens (lire un URL, comprendre un nom de domaine, distinguer le Web et Facebook…) avant d'espérer un progrès.
Deux jours après la publication de cet article, la ministre de la Culture Officielle a donné un interview où elle confirme que le gouvernement compte bien pouvoir censurer plus rapidement les contenus qui lui déplaisent, et se sert de la censure effectuée par Facebook pour justifier une censure décidée par l'État.
Next Inpact a fait au même moment un bon article sur le sujet des mensonges. Et Johann Savalle a fait un bon résumé en anglais de mon article, sous la forme d'un fil Twitter.
Depuis l'écriture de cet article, je me suis aperçu que, dans le numéro 1329 de Charlie Hebdo, daté du 10 janvier 2018, Guillaume Erner, sous le titre « Jupiter veut foudroyer les fake news » avait dit exactement la même chose, et en mieux. Je promets que je n'ai pas copié (je n'avais pas lu cet article) mais je vous informe que vous pouvez arrêter de lire ce blog et vous abonner à Charlie Hebdo à la place. (Le même Guillaume Erner a fait une excellente démolition du ridicule sondage IFOP « 79 % des Français adhèrent à une théorie complotiste » dans le numéro suivant. Lecture très recommandée, et qui montre bien que « complotisme » fait partie de ces termes flous qui servent essentiellement un but rhétorique.)
D'autre part, la Quadrature du Net a fait une excellente réponse à la consultation (pourtant biaisée et malhonnête) de la Commission européenne. Je vous en recommande très fortement la lecture.
L'article seul
RFC 8318: IAB, IESG, and IAOC Selection, Confirmation, and Recall Process: IAOC Advisor for the Nominating Committee
Date de publication du RFC : Janvier 2018
Auteur(s) du RFC : S. Dawkins (Wonder Hamster)
Première rédaction de cet article le 1 février 2018
Un petit RFC bureaucratique pour traiter un manque du RFC 7437, qui ne disait pas que l'IAOC devait envoyer quelqu'un au NomCom, le comité de nomination. (Mais de toute façon, l'IAOC ayant été supprimée depuis, ce RFC n'est plus pertinent, voir le RFC 8713.)
En effet, le NomCom, le comité chargé d'étudier les personnes qui pourront occuper des postes dans divers organismes de l'IETF (cf. RFC 7437), ce NomCom s'occupe entre autres des postes à l'IAOC (RFC 4071), mais ne disait pas que l'IAOC pouvait envoyer un membre au NomCom, comme le faisaient les autres organes. A priori, ce n'était pas grave puisque le NomCom pouvait toujours ajouter qui il voulait comme observateur mais, en 2017, le NomCom a travaillé sur un poste à l'IAOC sans avoir de représentant de l'IAOC à ses réunions.
Ce n'est pas la fin du monde mais cela a justifié ce RFC, qui ajoute juste aux règles existantes que le NomCom devrait veiller à avoir quelqu'un de l'IAOC, ou qui connait l'IAOC.
Les discussions qui ont eu lieu autour de ce minuscule changement sont résumées dans l'annexe A. Par exemple, après un long débat, ce « représentant » de l'IAOC sera qualifié d'« advisor » et pas de « liaison » (en gros, un « liaison » a un boulot plus formel et plus sérieux.)
L'article seul
RFC 8314: Cleartext Considered Obsolete: Use of TLS for Email Submission and Access
Date de publication du RFC : Janvier 2018
Auteur(s) du RFC : K. Moore (Windrock), C. Newman (Oracle)
Chemin des normes
Réalisé dans le cadre du groupe de travail IETF uta
Première rédaction de cet article le 31 janvier 2018
Ce RFC s'inscrit dans le cadre des efforts de sécurisation de l'Internet contre la surveillance massive, efforts notablement accélérés depuis les révélations Snowden. Désormais, l'usage de texte en clair (non chiffré) pour le courrier électronique est officiellement abandonné : POP, IMAP et SMTP doivent être chiffrés.
Plus précisément, ce nouveau RFC du groupe de travail UTA vise l'accès au courrier (POP - RFC 1939 et IMAP - RFC 9051), ainsi que la soumission de messages par SMTP - RFC 6409 (entre le MUA et le premier MTA). Les messages de ces protocoles doivent désormais être systématiquement chiffrés avec TLS - RFC 5246. Le but est d'assurer la confidentialité des échanges. Le cas de la transmission de messages entre MTA est couvert par des RFC précédents, RFC 3207 et RFC 7672 (voir aussi le RFC 8461).
Pour résumer les recommandations concrètes de ce RFC :
- TLS 1.2 au minimum (on croise encore souvent SSL malgré le RFC 7568).
- Migrer le plus vite possible vers le tout-chiffré si ce n'est pas déjà fait.
- Utiliser le « TLS implicite » sur un port dédié, où on démarre TLS immédiatement (par opposition au vieux système STARTTLS, où on demandait explicitement le démarrage de la cryptographie, cf. sections 2 et 3 du RFC).
Ce RFC ne traite pas le cas du chiffrement de bout en bout, par
exemple avec PGP (RFC 4880 et RFC 3156). Ce chiffrement
de bout en bout est certainement la meilleure solution mais il est
insuffisamment déployé aujourd'hui. En attendant qu'il se
généralise, il faut bien faire ce qu'on peut pour protéger les
communications. En outre, PGP ne protège pas certaines métadonnées
comme les en-têtes (From:,
Subject:, etc), alors qu'un chiffrement TLS
du transport le fait. Bref, on a besoin des deux.
La section 3 du RFC rappelle ce qu'est le « TLS implicite », qui est désormais recommandé. Le client TLS se connecte à un serveur TLS sur un port dédié, où tout se fait en TLS, et il démarre la négociation TLS immédiatement. Le TLS implicite s'oppose au « TLS explicite » qui était l'approche initiale pour le courrier. Avec le TLS explicite (RFC 2595 et RFC 3207), le serveur devait annoncer sa capacité à faire du TLS :
% telnet smtpagt1.ext.cnamts.fr. smtp
Trying 93.174.145.55...
Connected to smtpagt1.ext.cnamts.fr.
Escape character is '^]'.
220 smtpagt1.ext.cnamts.fr ESMTP CNAMTS (ain1)
EHLO mail.example.com
250-smtpagt1.ext.cnamts.fr Hello mail.example.com [192.0.2.187], pleased to meet you
250-ENHANCEDSTATUSCODES
250-PIPELINING
250-8BITMIME
250 STARTTLS
Et le client devait dire qu'il allait démarrer la session TLS avec la commande STARTTLS. L'inconvénient principal de STARTTLS est qu'il est vulnérable à l'attaque « SSL stripping » où un attaquant actif modifie la communication avant que TLS ne démarre, pour faire croire que le partenaire ne sait pas faire de TLS. (Et il y a aussi la vulnérabilité CERT #555316.) Bien sûr, les serveurs peuvent se protéger en refusant les connexions sans STARTTLS mais peu le font. L'approche STARTTLS était conçue pour gérer un monde où certains logiciels savaient faire du TLS et d'autres pas, mais, à l'heure où la recommandation est de faire du TLS systématiquement, elle n'a plus guère d'utilité. (La question est discutée plus en détail dans l'annexe A. Notez qu'un des auteurs de notre nouveau RFC, Chris Newman, était l'un des auteurs du RFC 2595, qui introduisait l'idée de STARTTLS.)
Avec le TLS implicite, cela donne :
% openssl s_client -connect mail.example.com:465
...
subject=/CN=mail.example.com
issuer=/O=CAcert Inc./OU=http://www.CAcert.org/CN=CAcert Class 3 Root
...
Peer signing digest: SHA512
Server Temp Key: ECDH, P-256, 256 bits
...
New, TLSv1.2, Cipher is ECDHE-RSA-AES256-GCM-SHA384
Server public key is 2048 bit
...
220 mail.example.com ESMTP Postfix
EHLO toto
250-mail.example.com
250-AUTH DIGEST-MD5 NTLM CRAM-MD5
250-ENHANCEDSTATUSCODES
250-8BITMIME
250-DSN
250 SMTPUTF8
Donc, concrètement, pour POP, cela veut dire établir la connexion sur le port du TLS implicite, le 995 (et non pas sur le port 110, prévu pour le texte en clair), lancer TLS et authentifier avec le RFC 7817. Puis on fait du POP classique. Pour IMAP, c'est le port 993. Dans les deux cas, cette recommandation de notre RFC ne sera pas trop dure à suivre, le TLS implicite est déjà courant pour ces deux protocoles.
Pour la soumission SMTP (RFC 6409), c'est le port 465 (utilisé auparavant pour du SMTP classique, non-soumission, cf. le registre IANA et les section 7.3 et annexe A du RFC qui justifient cette réaffectation). Le mécanisme avec STARTTLS sur le port 587 (TLS explicite) est très répandu, contrairement à ce qui se passe pour POP et IMAP. La transition sera donc plus longue, et il faudra donc maintenir les deux services, TLS implicite et explicite, pendant un certain temps.
Voici les serveurs IMAP (pour récupérer le courrier) et SMTP
(pour soumettre du courrier) conformes aux recommandations de ce
RFC (TLS implicite), tels qu'affichés par
Thunderbird : 
Et voici la configuration du MTA Postfix pour accepter du TLS implicite sur le port 465 :
submissions inet n - - - - smtpd
-o syslog_name=postfix/submissions
-o smtpd_tls_wrappermode=yes
-o smtpd_sasl_auth_enable=yes
-o smtpd_client_restrictions=permit_sasl_authenticated,reject
-o smtpd_etrn_restrictions=reject
-o smtpd_sasl_authenticated_header=yes
(À mettre dans le master.cf.) Cette
configuration active TLS et exige une authentification du client
(ce qui est normal pour soumettre du courrier.) Pensez aussi à
vérifier que le port est bien défini dans
/etc/services (smtps 465/tcp ssmtp submissions).
La section 4 du RFC fournit des détails sur l'utilisation de TLS, du côté des fournisseurs de service de courrier. Le point essentiel est « chiffrement partout, tout le temps » (section 4.1). L'objectif ne pourra pas forcément être atteint immédiatement par tout le monde mais il faut commencer. Par exemple, on peut interdire tout accès en texte clair à certains utilisateurs, puis généraliser à tous. Et, dans ce cas, le message envoyé doit être indépendant de si le mot de passe était valide ou pas (pour ne pas donner d'indication à un éventuel écoutant). Le RFC conseille aussi de traiter les accès avec les vieilles versions de TLS (ou, pire, avec SSL) de la même façon que les accès en clair. Une fois l'accès en clair coupé, il est recommandé de forcer un changement de mot de passe, si l'ancien avait été utilisé en clair.
Et les autres points ? Les fournisseurs de services de
courrier électronique doivent annoncer les
services POP, IMAP et soumission SMTP en utilisant les
enregistrements SRV du RFC 6186, afin de faciliter la tâche des
MUA. Un nouvel enregistrement SRV arrive
avec ce RFC, d'ailleurs, le _submissions._tcp,
pour la soumission SMTP sur TLS. Le RFC demande que ces enregistrements
SRV (ainsi que les
enregistrements MX utilisés pour le
courrier entrant, donc a priori pas le sujet de ce RFC) soient
signés avec DNSSEC. Et, à propos du
DNS, le RFC demande également la
publication d'enregistrements TLSA (RFC 6698).
La cryptographie, c'est bien, mais il est également souhaitable
de signaler qu'elle a été utilisée, et dans quelles conditions,
pour informer les utilisateurs de la sécurité dont ils ont pu
bénéficier. Par exemple, le RFC demande que les algorithmes de
cryptographie utilisées soient mis dans l'en-tête
Received: du courrier (cf. aussi le RFC 3848), via une clause
tls (dans registre
IANA). Notez que beaucoup de serveurs SMTP le font déjà,
avec une syntaxe différente :
Received: from mail4.protonmail.ch (mail4.protonmail.ch [185.70.40.27])
(using TLSv1.2 with cipher ECDHE-RSA-AES256-GCM-SHA384 (256/256 bits))
(No client certificate requested)
by mail.bortzmeyer.org (Postfix) with ESMTPS id 38DAF31D16
for <stephane@bortzmeyer.org>; Sat, 20 Jan 2018 16:56:59 +0100 (CET)
La section 5 décrit les exigences pour l'autre côté, le client,
cette fois, et non plus le serveur de la section 4. D'abord, comme
les MUA sont en contact direct avec
l'utilisateur humain, ils doivent lui indiquer clairement le
niveau de confidentialité qui a été obtenu (par exemple par une
jolie icône, différente si on a utilisé TLS ou pas). Notez que
cette indication de la confidentialité est un des points du projet
Caliopen. Gmail, par
exemple, peut
afficher ces informations et cela donne :
Comment est-ce qu'un MUA doit trouver s·on·es serveur·s, au
fait ? La méthode recommandée est d'utiliser les
enregistements SRV du RFC 6186. Aux _imap._tcp et
_pop3._tcp du RFC précédent s'ajoute
_submissions._tcp pour le SMTP de soumission
d'un message, avec TLS implicite. Attention, le but étant la
confidentialité, le MUA ne devrait pas utiliser les serveurs
annoncés via les SRV s'ils ne satisfont pas à des exigences
minimales de sécurité TLS. Le MUA raisonnable devrait vérifier que
le SRV est signé avec DNSSEC, ou, sinon,
que le serveur indiqué est dans le même domaine que le domaine de
l'adresse de courrier. La section 5.2 donne d'autres idées de
choses à vérifier (validation du certificat
du serveur suivant le RFC 7817, de la version de TLS…) D'une
manière générale, le MUA ne doit pas envoyer d'informations
sensibles comme un mot de passe si la session n'est pas sûre. La
tentation pourrait être d'afficher à l'utilisateur un dialogue du
genre « Nous n'avons pas réussi à établir une connexion TLS
satisfaisante car la version de TLS n'est que la 1.1 et le groupe Diffie-Hellman ne fait que 512
bits, voulez-vous continuer quand même ? » Mais le RFC s'oppose à
cette approche, faisant remarquer qu'il est alors trop facile pour
l'utilisateur de cliquer OK et de prendre ainsi des risques qu'il
ne maitrise pas.
Autre question de sécurité délicate, l'épinglage du certificat. Il s'agit de garder un certificat qui a marché autrefois, même s'il ne marche plus, par exemple parce qu'expiré. (Ce n'est donc pas le même épinglage que celui qui est proposé pour HTTP par le RFC 7469.) Le RFC autorise cette pratique, ce qui est du bon sens : un certificat expiré, ce n'est pas la même chose qu'un certificat faux. Et ces certificats expirés sont fréquents car, hélas, bien des administrateurs système ne supervisent pas l'expiration des certificats. Voici la configuration d'Icinga pour superviser un service de soumission via SMTP :
apply Service "submissions" {
import "generic-service"
check_command = "ssmtp"
vars.ssmtp_port = 465
assign where (host.address || host.address6) && host.vars.submissions
vars.ssmtp_certificate_age = "7,3"
}
Et, une fois ce service défini, on peut ajouter à la
définition d'un serveur vars.submissions =
true et il sera alors supervisé :
Notre RFC recommande également aux auteurs de MUA de faire en sorte que les utilisateurs soient informés du niveau de sécurité de la communication entre le client et le serveur. Tâche délicate, comme souvent quand on veut communiquer avec les humains. Il ne faut pas faire de fausses promesses (« votre connection est cryptée avec des techniques military-grade, vous êtes en parfaite sécurité ») tout en donnant quand même des informations, en insistant non pas sur la technique (« votre connexion utilise ECDHE-RSA-AES256-GCM-SHA384, je vous mets un A+ ») mais sur les conséquences (« Ce serveur de courrier ne propose pas de chiffrement de la communication, des dizaines d'employés de la NSA, de votre FAI, et de la Fsociety sont en train de lire le message où vous parlez de ce que vous avez fait hier soir. »).
Voilà, vous avez l'essentiel de ce RFC. Quelques détails, maintenant. D'abord, l'interaction de ces règles avec les antivirus et antispam. Il y a plusieurs façons de connecter un serveur de messagerie à un logiciel antivirus et·ou antispam (par exemple l'interface Milter, très répandue). Parfois, c'est via SMTP, avec l'antivirus et·ou antispam qui se place sur le trajet, intercepte les messages et les analyse avant de les retransmettre. C'est en général une mauvaise idée (RFC 2979). Dès qu'il y a du TLS dans la communication, c'est encore pire. Puisque le but de TLS est de garantir l'authenticité et l'intégrité de la communication, tout « intercepteur » va forcément être très sale. (Et les logiciels qui font cela sont d'abominables daubes.)
Ah, et un avertissement lié à la vie privée (section 8 du RFC) : si on présente un certificat client, on révèle son identité à tout écoutant. Le futur TLS 1.3 aidera peut-être à limiter ce risque mais, pour l'instant, attention à l'authentification par certificat client.
Si vous aimez connaitre les raisons d'un choix technique, l'annexe A couvre en détail les avantages et inconvénients respectifs du TLS implicite sur un port séparé et du TLS explicite sur le port habituel. La section 7 du RFC 2595 donnait des arguments en faveur du TLS explicite. Certaines des critiques que ce vieux RFC exprimait contre le TLS implicite n'ont plus de sens aujourd'hui (le RFC 6186 permet que le choix soit désormais fait par le logiciel et plus par l'utilisateur, et les algorithmes export sont normalement abandonnés). D'autres critiques ont toujours été mauvaises (par exemple, celle qui dit que le choix entre TLS et pas de TLS est binaire : un MUA peut essayer les deux.) Outre la sécurité, un avantage du port séparé pour TLS est qu'il permet de déployer des frontaux - répartiteurs de charge, par exemple - TLS génériques.
Et pour terminer, d'autres exemples de configuration. D'abord avec mutt, par Keltounet :
smtp_url=smtps://USER@SERVER:465
Et le courrier est bien envoyé en TLS au port de soumission à TLS implicite.
Avec Dovecot, pour indiquer les
protocoles utilisés dans la session TLS, Shaft suggère, dans conf.d/10-logging.conf :
login_log_format_elements = user=<%u> method=%m rip=%r lip=%l mpid=%e %c %k
(Notez le %k à la fin, qui n'est pas dans le
fichier de configuration d'exemple.)
Et pour OpenSMTPd ? n05f3ra1u propose :
pki smtp.monserveur.example key "/etc/letsencrypt/live/monserveur.example/privkey.pem"
pki smtp.monserveur.example certificate "/etc/letsencrypt/live/monserveur.example/cert.pem"
...
listen on eno1 port 465 hostname smtp.monserveur.example smtps pki smtp.monserveur.example auth mask-source
L'article seul
RFC 2818: HTTP Over TLS
Date de publication du RFC : Mai 2000
Auteur(s) du RFC : E. Rescorla (RTFM)
Pour information
Première rédaction de cet article le 27 janvier 2018
C'est un RFC très ancien que ce RFC 2818, et qui décrit une technologie qui ne s'est pourtant imposée presque partout que récemment, HTTPS (HTTP sur TLS). Le RFC a depuis été remplacé par le RFC 9110.
Remettons-nous dans le contexte de l'époque : en 2000, la NSA espionnait déjà massivement, mais on n'avait pas encore eu les révélations Snowden. Les pays comme la Russie et la Chine n'avaient sans doute pas encore d'activités d'espionnage sur l'Internet et la France… espionnait le trafic Minitel. L'inquiétude à l'époque n'était pas tellement tournée vers les services secrets officiels mais plutôt vers le méchant pirate qui allait copier les numéros de carte bleue quand on allait les utiliser pour le e-commerce (concept relativement récent à l'époque). HTTPS, le HTTP sécurisé par la cryptographie semblait à l'époque réservé aux formulaires où on tapait un numéro de carte de crédit. Ce n'est qu'à partir des révélations de Snowden que HTTPS a commencé à être déployé systématiquement, et qu'il forme sans doute aujourd'hui la majorité du trafic, malgré les indiscrets de tout bord qui auraient voulu continuer à surveiller le trafic, et qui répétaient « M. Michu n'a pas besoin de chiffrement ». (Au FIC en 2016, dans une réunion publique, un représentant d'un grand FAI se désolait que le déploiement massif de HTTPS empêchait d'étudier ce que faisaient ses clients…) Ce succès est en partie dû à des campagnes de sensibilisation (menées par exemple par l'EFF) et à des outils comme HTTPS Everywhere.
Revenons au RFC. Il est très court (sept pages) ce qui est logique puisque le gros du travail est fait dans le RFC 5246, qui normalise TLS (c'était le RFC 2246, à l'époque). Car, HTTPS, c'est juste HTTP sur TLS, il n'y a pas grand'chose à spécifier. Notons que le titre du RFC est « HTTP sur TLS », que le texte ne parle que de TLS comme protocole de cryptographie et pourtant, dix-huit ans plus tard, des gens ignorants parlent encore de SSL, le prédécesseur, abandonné depuis longtemps, de TLS.
Ironie des processus internes de l'IETF, notre RFC n'est pas sur le chemin des normes Internet, il a seulement la qualité « pour information ».
La section 1 résume le RFC : HTTPS, comme TLS, protège le canal et non pas les données. Cela veut dire notamment que HTTPS ne protège pas si on a des sites miroir et que l'un d'eux se fait pirater. (En 2018, on n'a toujours pas de moyen standard de sécuriser les données envoyées sur le Web, malgré quelques briques possiblement utilisables comme XML Signature - RFC 3275 et JOSE.)
La section 2 décrit le protocole en une phrase : « Utilisez HTTP
sur TLS, comme vous utiliseriez HTTP sur TCP. »
Bon, j'exagère, il y a quelques détails. Le client HTTPS doit être un
client TLS, donc un client TCP. Il se connecte au serveur en TCP puis
lance TLS puis fait des requêtes HTTP par dessus la session TLS,
elle-même tournant sur la connexion TCP. Cela se voit bien avec
l'option -v de
curl. D'abord du TCP :
% curl -v https://www.bortzmeyer.org/crypto-protection.html * Trying 2605:4500:2:245b::42... * TCP_NODELAY set * Connected to www.bortzmeyer.org (2605:4500:2:245b::42) port 443 (#0)
Puis TLS démarre :
* ALPN, offering h2 * ALPN, offering http/1.1 * Cipher selection: ALL:!EXPORT:!EXPORT40:!EXPORT56:!aNULL:!LOW:!RC4:@STRENGTH * successfully set certificate verify locations: * CAfile: /etc/ssl/certs/ca-certificates.crt CApath: /etc/ssl/certs * TLSv1.2 (OUT), TLS header, Certificate Status (22): * TLSv1.2 (OUT), TLS handshake, Client hello (1): * TLSv1.2 (IN), TLS handshake, Server hello (2): * TLSv1.2 (IN), TLS handshake, Certificate (11): * TLSv1.2 (IN), TLS handshake, Server key exchange (12): * TLSv1.2 (IN), TLS handshake, Server finished (14): * TLSv1.2 (OUT), TLS handshake, Client key exchange (16): * TLSv1.2 (OUT), TLS change cipher, Client hello (1): * TLSv1.2 (OUT), TLS handshake, Finished (20): * TLSv1.2 (IN), TLS change cipher, Client hello (1): * TLSv1.2 (IN), TLS handshake, Finished (20): * SSL connection using TLSv1.2 / ECDHE-RSA-AES256-GCM-SHA384 * ALPN, server accepted to use http/1.1 * Server certificate: * subject: CN=www.bortzmeyer.org * start date: Sep 21 06:34:08 2016 GMT * expire date: Sep 21 06:34:08 2018 GMT * subjectAltName: host "www.bortzmeyer.org" matched cert's "www.bortzmeyer.org" * issuer: O=CAcert Inc.; OU=http://www.CAcert.org; CN=CAcert Class 3 Root * SSL certificate verify ok.
Et enfin on peut faire de l'HTTP :
> GET /crypto-protection.html HTTP/1.1 > Host: www.bortzmeyer.org > User-Agent: curl/7.52.1 > Accept: */* > < HTTP/1.1 200 OK < Server: Apache/2.4.25 (Debian) < ETag: "8ba9-56281c23dd308" < Content-Length: 35753 < Content-Type: text/html < <?xml version="1.0" ?> <!DOCTYPE html PUBLIC "-//W3C//DTD XHTML 1.0 Strict//EN" "http://www.w3.org/TR/xhtml1/DTD/xhtml1-strict.dtd"> <html xml:lang="fr" lang="fr" xmlns="http://www.w3.org/1999/xhtml"> <head> ... <title>Blog Stéphane Bortzmeyer: La cryptographie nous protège t-elle vraiment de l'espionnage par la NSA ou la DGSE ?</title> ... </body> </html>
Et on termine :
* Curl_http_done: called premature == 0 * Connection #0 to host www.bortzmeyer.org left intact
Si on n'aime pas curl, on peut le faire avec le client en ligne de commande de GnuTLS, puis taper les requêtes HTTP à la main :
% echo -n "GET /who-buys-porn.html HTTP/1.1\r\nHost: www.bortzmeyer.org\r\nUser-Agent: à la main\r\n\r\n" | \ gnutls-cli www.bortzmeyer.org Processed 167 CA certificate(s). Resolving 'www.bortzmeyer.org:443'... Connecting to '2605:4500:2:245b::42:443'... - Certificate type: X.509 - Got a certificate list of 2 certificates. - Certificate[0] info: - subject `CN=www.bortzmeyer.org', issuer `CN=CAcert Class 3 Root,OU=http://www.CAcert.org,O=CAcert Inc.', serial 0x029ba3, RSA key 2048 bits, signed using RSA-SHA256, activated `2016-09-21 06:34:08 UTC', expires `2018-09-21 06:34:08 UTC', key-ID `sha256:141954e99b9c88a33af6ffc00db09f5d8b66185a7325f45cbd45ca3cb47d63ce' Public Key ID: sha1:82500582b33c12ada8891e9a36192131094bed22 sha256:141954e99b9c88a33af6ffc00db09f5d8b66185a7325f45cbd45ca3cb47d63ce Public key's random art: +--[ RSA 2048]----+ |o=o oo. | |O..+ | |+Bo | |E= o . | |*.+ . . S | |+o . | |o.+ | |o= | |. . | +-----------------+ - Certificate[1] info: - subject `CN=CAcert Class 3 Root,OU=http://www.CAcert.org,O=CAcert Inc.', issuer `EMAIL=support@cacert.org,CN=CA Cert Signing Authority,OU=http://www.cacert.org,O=Root CA', serial 0x0a418a, RSA key 4096 bits, signed using RSA-SHA256, activated `2011-05-23 17:48:02 UTC', expires `2021-05-20 17:48:02 UTC', key-ID `sha256:bd0d07296b43fae03b64e650cbd18f5e26714252035189d3e1263e4814b4da5a' - Status: The certificate is trusted. - Description: (TLS1.2)-(ECDHE-RSA-SECP256R1)-(AES-256-GCM) - Session ID: A6:A6:CE:32:08:9D:B8:D2:EF:D6:C7:D4:85:B4:39:D7:0D:04:83:72:6F:87:02:50:44:B7:29:64:E5:69:0B:07 - Ephemeral EC Diffie-Hellman parameters - Using curve: SECP256R1 - Curve size: 256 bits - Version: TLS1.2 - Key Exchange: ECDHE-RSA - Server Signature: RSA-SHA256 - Cipher: AES-256-GCM - MAC: AEAD - Compression: NULL - Options: safe renegotiation, - Handshake was completed - Simple Client Mode: HTTP/1.1 200 OK Server: Apache/2.4.25 (Debian) Content-Length: 8926 Content-Type: text/html
Et, vu par tshark, ça donne d'abord TCP :
1 0.000000000 2a01:e35:8bd9:8bb0:dd2c:41a5:337f:a21f → 2605:4500:2:245b::42 TCP 94 45502 → 443 [SYN] Seq=0 Win=28400 Len=0 MSS=1420 SACK_PERM=1 TSval=26014765 TSecr=0 WS=128 2 0.080848074 2605:4500:2:245b::42 → 2a01:e35:8bd9:8bb0:dd2c:41a5:337f:a21f TCP 94 443 → 45502 [SYN, ACK] Seq=0 Ack=1 Win=28560 Len=0 MSS=1440 SACK_PERM=1 TSval=476675178 TSecr=26014765 WS=64 3 0.080902511 2a01:e35:8bd9:8bb0:dd2c:41a5:337f:a21f → 2605:4500:2:245b::42 TCP 86 45502 → 443 [ACK] Seq=1 Ack=1 Win=28416 Len=0 TSval=26014785 TSecr=476675178
Puis TLS :
4 0.084839464 2001:db8:57aa:8bb0:dd2c:9af:222f:a21f → 2605:4500:2:245b::42 SSL 351 Client Hello 5 0.170845913 2605:4500:2:245b::42 → 2001:db8:57aa:8bb0:dd2c:9af:222f:a21f TCP 86 443 → 45502 [ACK] Seq=1 Ack=266 Win=29632 Len=0 TSval=476675200 TSecr=26014786 6 0.187457346 2605:4500:2:245b::42 → 2001:db8:57aa:8bb0:dd2c:9af:222f:a21f TLSv1.2 1494 Server Hello 7 0.187471721 2001:db8:57aa:8bb0:dd2c:9af:222f:a21f → 2605:4500:2:245b::42 TCP 86 45502 → 443 [ACK] Seq=266 Ack=1409 Win=31232 Len=0 TSval=26014812 TSecr=476675202 8 0.187583400 2605:4500:2:245b::42 → 2001:db8:57aa:8bb0:dd2c:9af:222f:a21f TLSv1.2 2320 Certificate, Server Key Exchange, Server Hello Done 9 0.187600261 2001:db8:57aa:8bb0:dd2c:9af:222f:a21f → 2605:4500:2:245b::42 TCP 86 45502 → 443 [ACK] Seq=266 Ack=3643 Win=35712 Len=0 TSval=26014812 TSecr=476675202 10 0.199416730 2001:db8:57aa:8bb0:dd2c:9af:222f:a21f → 2605:4500:2:245b::42 TLSv1.2 212 Client Key Exchange, Change Cipher Spec, Hello Request, Hello Request 11 0.283191938 2605:4500:2:245b::42 → 2001:db8:57aa:8bb0:dd2c:9af:222f:a21f TLSv1.2 360 New Session Ticket, Change Cipher Spec, Encrypted Handshake Message
C'est fait, TLS a démarré (notez le nombre de paquets qu'il a fallu échanger pour cela : TLS accroit la latence, et beaucoup de travaux actuellement à l'IETF visent à améliorer ce point). On peut maintenant faire du HTTP :
12 0.283752212 2001:db8:57aa:8bb0:dd2c:9af:222f:a21f → 2605:4500:2:245b::42 TLSv1.2 201 Application Data 13 0.365992864 2605:4500:2:245b::42 → 2001:db8:57aa:8bb0:dd2c:9af:222f:a21f TLSv1.2 1494 Application Data
Comment, on ne voit pas le HTTP, juste le Application Data générique de TLS ? Oui, c'est exprès, c'est bien à ça que sert TLS.
Bon, ce n'est pas tout d'ouvrir une session, il faut aussi la
fermer. Le RFC précise qu'il faut utiliser la fermeture TLS avant la
fermeture TCP, pour être sûr que toutes les données ont été
transmises. Le cas des fermetures de session trop brutales forme
d'ailleurs l'essentiel du RFC (que faire si la connexion TCP est
rompue avant la session TLS ? Cela peut avoir des conséquences de
sécurité, par exemple s'il n'y a pas d'en-tête HTTP
Conent-Length: et que la connexion TCP est
coupée, on ne peut pas savoir si on a tout reçu ou bien si un
attaquant a généré une fausse coupure de connexion TCP qui,
contrairement à la fermeture TLS, n'est pas authentifiée, cf. RFC 5961.
Reste la question du port à utiliser. Comme vous le savez sans
doute, HTTPS utilise le port 443. Il est enregistré
à cet effet à l'IANA. Notez que
gnutls-cli, utilisé plus haut, utilise ce port
par défaut.
Et le plan d'URI à utiliser pour HTTPS ?
Là aussi, vous le connaissez, c'est https://
donc par exemple, https://www.afnic.fr/https://www.ietf.org/blog/codel-improved-networking-through-adaptively-managed-router-queues/https://lad.wikipedia.org/wiki/Gefilte_fishhttps:// pour les URI est désormais dans le
RFC 7230, et plus détaillée que la description
informelle du vieux RFC.
Mais ça n'est pas tout d'avoir une connexion chiffrée… Comme le
notent plusieurs auteurs « TLS permet d'avoir une session sécurisée
avec un ennemi ». En effet, si vous n'authentifiez pas la machine à
l'autre bout, TLS ne sera pas très utile. Vous risquerez d'être
victime de l'attaque de l'homme du milieu où
Mallory se place entre Alice et Bob,
prétendant être Bob pour Alice et Alice pour Bob. Il est donc très
important d'authentifier le partenaire, et c'est là la principale
faiblesse de HTTPS. On utilise en général un
certificat X.509 (ou,
plus rigoureusement, un certificat PKIX,
cf. RFC 5280). Comme HTTPS part en général d'un
URI, le client a dans cet URI le
nom de domaine du serveur. C'est ce nom qu'il
doit comparer avec ce qu'il trouve dans le certificat (plus
exactement, on regarde le subjectAltName si
présent, puis le Common Name, CN, mais
rappelez-vous que le RFC est vieux, les règles ont évolué
depuis). D'autres
techniques d'authentification sont possibles, comme l'épinglage de la clé (RFC 7469), qu'on peut combiner avec les clés nues
du RFC 7250.
Si quelque chose ne va pas dans l'authentification, on se récupère un avertissement du navigateur, proposant parfois de passer outre le problème. Le RFC notait déjà, il y a dix-huit ans, que c'était dangereux car cela laisserait la session potentiellement sans protection. Globalement, depuis la sortie du RFC, les navigateurs sont devenus de plus en plus stricts, rendant ce débrayage de la sécurité plus difficile.
Voici un exemple de problème d'authentification. Le Centre
Hospitalier de Bois-Petit redirige automatiquement les
visiteurs vers la version HTTPS de son site, qui n'a pas le bon nom
dans le certificat. Ici, la protestation de
Firefox (notez la possibilité d'ajouter une
exception manuellement) :
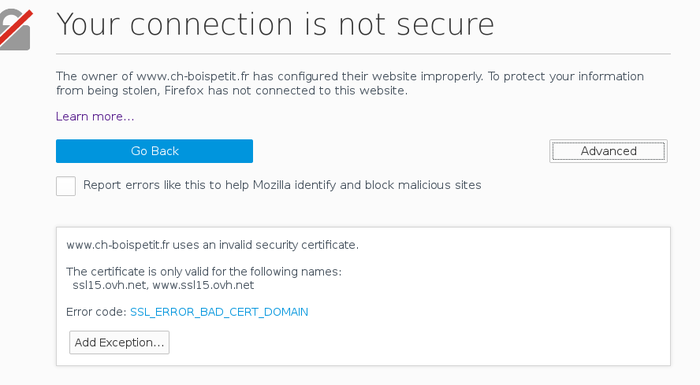
curl râle également, bien sûr :
% curl https://www.ch-boispetit.fr/ curl: (51) SSL: no alternative certificate subject name matches target host name 'www.ch-boispetit.fr'
Une variante de cette erreur se produit lorsque le site est
accessible par plusieurs noms en HTTP mais que tous ne sont pas
authentifiables en HTTPS. Par exemple, pour le quotidien
Le Monde, http://lemonde.frhttp://www.lemonde.frwww.lemonde.fr est dans le
certificat. (Même chose, aujourd'hui, pour https://wikipedia.fr/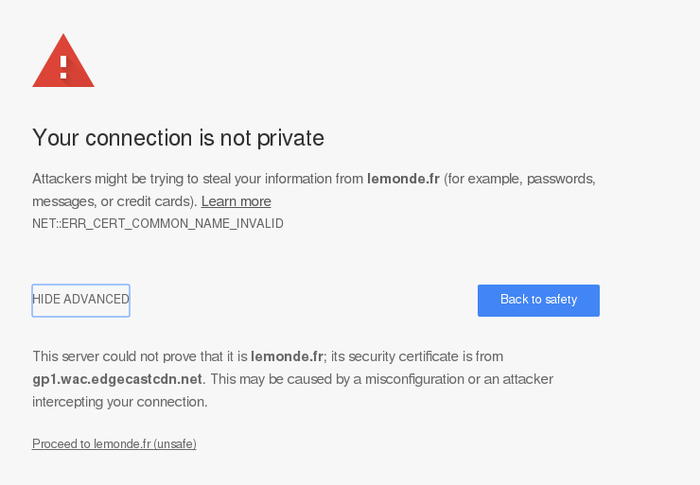
D'autres erreurs sont possibles avec la gestion des certificats, la
plus fréquente étant sans doute le certificat expiré. Si vous
voulez regarder avec votre navigateur Web des exemples d'erreurs,
l'excellent site https://badssl.com/
Le RFC note à juste titre que l'URI de départ vient souvent d'une
source qui n'est pas digne de confiance. Si vous suivez un lien qui
est dans vos signets, ou que vous le tapez
vous-même en faisant attention, l'URI est digne de confiance, et la
vérification du certificat vous protégera. Mais si vous cliquez sur
un lien dans un message envoyé par une nommée
natacha@viagra-pharmacy.ru annonçant
« Agrandissez votre pénis », ou même un lien dans un message
prétendant venir de votre patron et annonçant
« dossier très urgent à lire » (rappelez-vous que le
courrier électronique n'est pas authentifié,
sauf si on utilise PGP ou équivalent),
alors, l'URI n'est pas sûr et HTTPS ne vous protégera pas (sauf si
vous scrutez avec soin l'URI dans la barre d'adresses du navigateur,
ce que personne ne fait et, de toute façon, c'est parfois trop
tard). C'est ce qu'on appelle le hameçonnage
et c'est une attaque fréquente, contre laquelle toute la
cryptographie du monde ne vous protège pas. (Ceci dit, à l'heure
actuelle, spammeurs et hameçonneurs ne se sont pas mis massivement à
HTTPS, la plupart du temps, ils en restent au bon vieil HTTP.)
Notez qu'on n'a parlé que de la vérification par le client de l'identité du serveur (qui utilise le fait que le client connait le nom de domaine du serveur). La vérification par le serveur de l'identité du client est également possible (envoi d'un certificat par le client) mais elle nécessite que le serveur ait une base des clients connus (ou qu'il accepte tous les certificats d'une AC donnée).
Après cet article, et compte tenu du fait que HTTPS existe
formellement depuis si longtemps, vous devez vous dire que ce blog
que vous lisez est accessible en HTTPS, non ? Eh bien, il l'est mais je ne publie
pas les URI en https:// et je ne fais pas de
redirection automatique vers la version HTTPS. En effet, j'utilise
une AC gratuite et facile d'usage mais que la plupart des vendeurs n'incluent
pas dans leur magasin des AC (ce qui est une décision arbitraire :
regardez le magasin des AC via votre navigateur Web, et voyez si
vous faites confiance aux gouvernements chinois et turcs, ainsi
qu'aux entreprises privées qui ne pensent qu'au profit). Tant que ce
problème durera, je ne pourrais pas faire de HTTPS par défaut. En
attendant, si vous voulez voir ce blog sur HTTPS, sur une
Debian, faites juste sudo aptitude
install ca-cacert (puis redémarrez le navigateur), sur les
autres systèmes, allez en https://www.cacert.org/index.php?id=3
Au fait, si quelqu'un a des références de bonnes études quantitatives sur le déploiement de HTTPS entre 2000 et aujourd'hui, je suis preneur. Je connais pour l'instant la télémétrie de Firefox. Elle est affichée ici (mais malheureusement uniquement depuis 2014) et montre aujourd'hui 70 % de pages Web en HTTPS.
L'article seul
Les spammeurs ne sont même pas compétents en standards du courrier
Première rédaction de cet article le 20 janvier 2018
Comme vous, je reçois du spam via le courrier électronique. J'en reçois peut-être davantage car mon adresse publiée sur ce blog a manifestement été mise sur des listes d'« influenceurs » et autres blogueurs mode. Ces spams, plus orientés « professionnels » sont souvent en deux parties, une en texte seul et l'autre en HTML. Mais ce qui est amusant est que les deux parties sont parfois désynchronisées.
[Si vous connaissez bien MIME, vous
pouvez sauter l'essentiel de cet article, et aller directement aux
observations de la fin. J'explique d'abord MIME
pour les gens qui ne connaissent pas.]
Cette possibilité d'envoyer un message en plusieurs parties est
normalisée dans le standard dit MIME,
spécifié dans le RFC 2045. Il existe de
nombreuses possibilités de message en plusieurs parties dans MIME
dont les deux plus connues sont les parties
différentes
(multipart/mixed dans les étiquettes MIME) et
les parties alternatives
(multipart/alternative pour MIME). Bien sûr,
la plupart des gens qui envoient des
newsletter et
CP ne savent pas cela. Ils ignorent que les
messages ont une forme normalisée dans le RFC 5322 et qui est assez différente de ce qu'ils voient sur
leur écran. Ainsi, prenons un message qui ressemble à ceci avec
Thunderbird :
Sur le réseau, il sera très différent. Ce qui passe, et qui est interprété par Thunderbird, sera :
Date: Sat, 20 Jan 2018 17:07:29 +0100
From: Stephane Bortzmeyer <stephane@bortzmeyer.org>
To: johndoe@example.com
Subject: Les roux, c'est sympa
Message-ID: <20180120160727.ehuvwpqhrhbzpv26@bortzmeyer.org>
MIME-Version: 1.0
Content-Type: multipart/mixed; boundary="gr5ck6jng3husyqz"
User-Agent: NeoMutt/20170113 (1.7.2)
--gr5ck6jng3husyqz
Content-Type: text/plain; charset=utf-8
Content-Disposition: inline
Content-Transfer-Encoding: 8bit
Un potamochère roux au ZooParc de Beauval.
Date 15 May 2016, 16:03:54
Source Own work
Author Thesupermat
--gr5ck6jng3husyqz
Content-Type: image/jpeg
Content-Disposition: attachment; filename*=utf-8''Zooparc_de_Beauval_-_Potamoch%C3%A8re_roux_-_2016_-_002%2Ejpg
Content-Transfer-Encoding: base64
/9j/4AAQSkZJRgABAgEBLAEsAAD/4UnURXhpZgAASUkqAAgAAAAMAA8BAgAGAAAAngAAABAB
AgAVAAAApAAAABIBAwABAAAAAQAAABoBBQABAAAAugAAABsBBQABAAAAwgAAACgBAwABAAAA
AgAAADEBAgAVAAAAygAAADIBAgAUAAAA4AAAADsBAgAMAAAA9AAAAJiCAgAJAAAAAAEAAGmH
...
Les parties différentes sont utilisées pour le cas où on envoie, par exemple, un texte et une image d'illustration (ce qui est le cas de l'exemple ci-dessus). Elles sont décrites dans le RFC 2046, section 5.1.3. Le message a un en-tête du genre (regardez l'exemple plus haut) :
Content-Type: multipart/mixed; boundary="------------514DC64B3521BD0334B199AA"
Une autre possibilité courante de message en plusieurs parties
est le cas des parties alternatives (RFC 2046, section 5.1.4). Prenons ce spam typique :

Sur le réseau, le contenu avait en fait deux parties, une en
texte brut et une en
HTML. Normalement, les deux sont
équivalentes, et le MUA va choisir laquelle
afficher. Dans l'image ci-dessus, Thunderbird affichait le
HTML. Ici, un autre MUA, mutt fait un autre
choix et affiche le texte seul :
Quant à ce qui circulait sur le câble, cela ressemble à :
MIME-Version: 1.0
To: bortzmeyer+ietf@nic.fr
Content-Type: multipart/alternative;
boundary="----=_NextPart_001_322D_019C6BD8.657D49B2"
X-Mailer: Smart_Send_2_0_138
Date: Thu, 18 Jan 2018 08:49:31 -0500
Message-ID: <5860441356088315066310@Ankur>
X-SMTPCOM-Tracking-Number: f5f27516-49b6-40ee-848b-62cb2597a453
X-SMTPCOM-Sender-ID: 6008902
Feedback-ID: 6008902:SMTPCOM
Subject: The SDN, NFV & Network Virtualization Ecosystem: 2017 - 2030 - Opportunities, Challenges, Strategies & Forecasts (Report
)
From: "Andy Silva" <andy.silva@snsreports.com>
------=_NextPart_001_322D_019C6BD8.657D49B2
Content-Type: text/plain; charset="iso-8859-1"
Content-Transfer-Encoding: quoted-printable
The SDN, NFV & Network Virtualization Ecosystem: 2017 =96 2030 =96 Opportun=
ities, Challenges, Strategies & Forecasts
...
------=_NextPart_001_322D_019C6BD8.657D49B2
Content-Type: text/html; charset="iso-8859-1"
Content-Transfer-Encoding: quoted-printable
<HTML xmlns:o><HEAD>
<META content=3D"text/html; charset=3Diso-8859-1" http-equiv=3DContent-Type>
<META name=3DGENERATOR content=3D"MSHTML 11.00.10570.1001"></HEAD>
<BODY>
<P><SPAN><FONT color=3D#000000><FONT color=3D#000000><FONT color=3D#000000>=
...
Enfin, il existe d'autres types de messages en plusieurs parties, comme les possibilités multilingues du RFC 8255.
Voilà, tout cela est ancien (le RFC 2046
date de 1996 !)
Maintenant, passons aux observations récentes. J'ai reçu le 15
janvier 2018 un spam de l'agence Maatch annonçant un « Voyage de
presse Roanne Tout & Simplement » (un voyage de presse est un
événement où une enterprise nourrit et abreuve des
« influenceurs » pour qu'ils écrivent ensuite des articles
favorables). Bizarrement, le voyage est annoncé pour le 9
septembre 2016. Et le message est « signé » d'un nom différent de
celui utilisé dans le champ From:. Il se
trouve que je lis mon courrier avec mutt et
l'option alternative_order text/plain qui lui
indique de préférer, dans les messages composés de plusieurs
parties alternatives,
le texte seul. Si je regarde la partie HTML du message, je vois la
bonne date (31 janvier 2018), le bon programme (« invitation au restaurant gastronomique Le Central, en compagnie de l'équipe de Roanne Tout
& Simplement et de chefs d'entreprises numériques ») et la
bonne « signature ». La personne qui a préparé le message n'a sans
doute pas directement écrit au format IMF (Internet
Message Format, RFC 5322) mais a
utilisé un logiciel qui n'affichait que la partie HTML, la seule
qu'elle met à jour quand elle prépare un nouvel envoi. Toutes les
occurrences futures de ce voyage de presse seront donc envoyés
avec une partie en texte brut restée figée en 2016. Et personne ne
s'en est aperçu car l'agence ne teste pas ses messages avec divers
MUA et que les destinataires, soit sont mariés avec les logiciels
« HTML seulement », soit envoient automatiquement ce genre de
messages dans le dossier Spam.
Le choix de l'utilisateur, présenté par mutt :

Est-ce un cas isolé dû à une agence de communication particulièrement incompétente ? Non, j'ai regardé d'autres spams et le phénomène ne semble pas exceptionnel. Par exemple, le 18 janvier, je reçois un spam de l'agence Srvsaas/Sellinity intitulé « Invitation personnelle: Dîner privilégié » et c'est encore plus amusant. La partie texte décrit un diner avec les commerciaux d'un fabricant de matériel réseau bien connu, la partie HTML un diner avec les commerciaux d'une autre entreprise, une entreprise de sécurité informatique importante. L'agence a repris un message conçu pour un client, a modifié la partie HTML pour un autre client et a oublié la partie texte !
D'autres accidents sont possibles avec ces deux parties pas toujours synchronisées. Par exemple, on me signale que les messages de confirmation de Ryanair ont une partie texte et une partie HTML et que la partie texte contient… du HTML. Bref, regarder la partie texte et la partie HTML des spams peut être une distraction intéressante.
L'article seul
Noms de domaine, DNS et vie privée
Première rédaction de cet article le 14 janvier 2018
Le 13 janvier 2018, à Fontenay-le-Fleury, à l'invitation de l'association de libristes Root66, j'ai fait un exposé sur les noms de domaine, le DNS et la vie privée. Presque trois heures, ouf (mais une galette après).
Voici les transparents de l'exposé :
- Version adaptée à l'écran,
- Version adaptée à l'impression,
- Source en LaTeX/Beamer.
Désolé, pas de vidéo, ça n'a pas été filmé. Mais vous pouvez lire mes articles sur les RFC 7626 (description du problème), RFC 7858 (chiffrement du DNS) et RFC 7816 (minimisation des données envoyées). Et bien sûr l'excellent portail « DNS privacy ».
Merci beaucoup à Zenzla زنزلا pour la proposition et l'organisation.
L'article seul
RFC 8300: Network Service Header (NSH)
Date de publication du RFC : Janvier 2018
Auteur(s) du RFC : P. Quinn (Cisco), U. Elzur
(Intel), C. Pignataro (Cisco)
Chemin des normes
Réalisé dans le cadre du groupe de travail IETF sfc
Première rédaction de cet article le 14 janvier 2018
Ce Network Service Header est un mécanisme concret pour faire passer sur le réseau les paquets destinés à une SF (Service Function, voir RFC 7665 pour l'architecture et les définitions). On colle un NSH, stockant plusieurs métadonnées, au paquet à traiter, on encapsule ce paquet à traiter et on l'envoie au dispositif de traitement via un réseau overlay. Et on fait l'opération inverse au retour. L'encapsulation peut se faire dans IP (par exemple avec GRE) ou dans un autre protocole.
Les métadonnées mises dans le NSH sont le résultat d'un processus de classification où le réseau décide ce qu'on va faire au paquet. Par exemple, en cas de dDoS, le classificateur décide de faire passer tous les paquets ayant telle adresse source par un équipement de filtrage plus fin, et met donc cette décision dans le NSH (section 7.1). Le NSH contient les informations nécessaires pour le SFC (Service Function Chain, RFC 7665). Sa lecture est donc très utile pour l'opérateur du réseau (elle contient la liste des traitements choisis, et cette liste peut permettre de déduire des informations sur le trafic en cours) et c'est donc une information plutôt sensible (voir aussi le RFC 8165).
Le NSH ne s'utilise qu'à l'intérieur de votre propre réseau (il n'offre, par défaut, aucune authentification et aucune confidentialité, voir section 8 du RFC). C'est à l'opérateur de prendre les mesures nécessaires, par exemple en chiffrant tout son trafic interne. Cette limitation à un seul domaine permet également de régler le problème de la fragmentation, si ennuyeux dès qu'on encapsule, ajoutant donc des octets. Au sein d'un même réseau, on peut contrôler tous les équipements et donc s'assurer que la MTU sera suffisante, ou, sinon, que la fragmentation se passera bien (section 5 du RFC).
Tout le projet SFC (dont c'est le troisième RFC) repose sur une vision de l'Internet comme étant un ensemble de middleboxes tripotant les paquets au passage, plutôt qu'étant un ensemble de machines terminales se parlant suivant le principe de bout en bout. C'est un point important à noter pour comprendre les débats au sein de l'IETF.
L'article seul
Cours BGP au CNAM
Première rédaction de cet article le 10 janvier 2018
Dernière mise à jour le 9 juillet 2018
Le 9 janvier 2018, c'était la première édition de mon cours BGP de trois heures au CNAM. Pour l'anecdote, c'était dans le bâtiment où il y avait eu la première connexion UUCP/Usenet, et le premier serveur HTTP public, en France.
Voici les supports de l'exposé :
- Version adaptée à l'écran,
- Version adaptée à l'impression,
- Source LaTeX.
Le cours a été filmé et la vidéo est en ligne.
J'ai fait aussi un cours DNS au même endroit.
Merci à Éric Gressier pour l'idée et l'organisation, et aux élèves pour avoir posé plein de questions pas toujours faciles.
L'article seul
RFC 8289: Controlled Delay Active Queue Management
Date de publication du RFC : Janvier 2018
Auteur(s) du RFC : K. Nichols (Pollere), V. Jacobson, A. McGregor, J. Iyengar (Google)
Expérimental
Réalisé dans le cadre du groupe de travail IETF aqm
Première rédaction de cet article le 6 janvier 2018
Ah, la gestion des files d'attentes… Le cauchemar de plein d'étudiants en informatique. Et cela ne cesse pas quand ils deviennent ingénieurs et qu'il faut construire un routeur pour connecter des réseaux de capacités différentes, et qui aura donc besoin de files d'attente. Bref, dès qu'on n'a pas assez de ressources (et on n'en aura jamais assez), il faut optimiser ses files d'attente. Ce nouveau RFC décrit le mécanisme CoDel (mis en œuvre depuis un certain temps dans le noyau Linux) qui permet notamment de limiter le terrible, l'épouvantable bufferbloat.
L'algorithme naïf pour gérer une file d'attente est le suivant (on prend le cas simple d'un routeur qui n'a que deux interfaces et une seule file d'attente dans chaque direction) : les paquets arrivent au routeur et sont mis dans la file gérée en FIFO. Dès que des ressources suffisantes sont disponibles pour envoyer un paquet (dès que l'interface de sortie est libre), on envoie le paquet et on le retire donc de la file. Si un paquet arrive quand la file est pleine, on le jette : TCP détectera cette perte, réduira son rythme d'envoi, et réémettra les données manquantes.
Avec cet algorithme simpliste, il y a une décision importante à prendre, la taille de la file. Le trafic sur l'Internet est tout sauf constant : des périodes de grand calme succèdent à des pics de trafic impressionnants. Si la file d'attente est trop petite, on ne pourra pas écluser ces pics, et on jettera des paquets. Ça tombe bien, le prix des mémoires baisse, on va pouvoir mettre des files plus grandes, non ? Eh bien non car arrive le fameux bufferbloat. Si la file est trop grande, les paquets y séjourneront très longtemps, et on augmentera ainsi la latence, au grand dam des applications sensibles comme SSH ou les jeux en ligne. Bref, on est coincés, il n'y a pas de solution idéale. Pire, si on ne jette des paquets que lorsque la file est pleine, on risque de tomber dans le cas où l'équilibre se fait avec une file d'attente toujours pleine, et donc avec une mauvaise latence.
Bien sûr, il y a longtemps que les routeurs n'utilisent plus d'algorithme aussi naïf que celui présenté ici. Tout un travail a été fait sur l'AQM : voir par exemple les RFC 7567 et RFC 8033. Mais le problème de la file d'attente toujours pleine est toujours là. Sa première description est dans le RFC 896 en 1984. Plus récemment, on le trouve mentionné dans une présentation de Jim Gettys à l'IETF 80 (« Bufferbloat: Dark Buffers in the Internet ») développé dans un article dans Communications of the ACM (Gettys a beaucoup fait pour la prise de conscience des dangers du bufferbloat.).
Résoudre le problème de l'« obésité du
tampon » (bufferbloat) en
réduisant la taille des files d'attentes ne serait pas une
solution : les tampons sont là pour une bonne raison, pour absorber
les problèmes brefs, lorsque, temporairement,
on reçoit davantage de paquets que ce que l'on peut transmettre. Le
fait que des files plus petites ne sont pas une solution a déjà été
exposé dans le RFC 2309, dans
« A Rant on
Queues » de Van Jacobson,
dans le rapport « RED
in a Different Light » et dans l'article fondateur
de CoDel, « Controlling
Queue Delay » (article complet sur
Sci-Hub, cherchez
10.1145/2209249.2209264). Le problème n'est
pas tant la taille de la file en soi (ce n'est pas la taille qui
compte), mais si c'est une « bonne » file ou une « mauvaise » file
(au passage, si vous ne connaissez pas la différence entre le bon
chasseur et le mauvais chasseur, ne ratez pas
l'indispensable sketch des
Inconnus).
CoDel est donc une vieille idée. Elle veut répondre, entre autres, aux critères suivants (section 1 du RFC) :
- Être « zéro-configuration » (parameterless), ce qui avait été un problème fréquent de solutions comme RED. (Mon opinion personnelle est que CoDel n'est pas réellement sans configuration, comme on le voit plus loin dans le RFC, mais il est certainement « configuration minimale ».) CoDel s'ajuste tout seul, une fois défini l'ordre de grandeur du RTT des paquets qui passeront par le routeur.
- Capable de différencier le mauvais chasseur du bon chasseur, euh, pardon, la mauvaise file d'attente de la bonne.
- Être simple à programmer, pour fonctionner aussi bien dans les processeurs limités des routeurs low cost que dans les ASIC (rapides, mais pas très souples) des routeurs haut de gamme.
Lorsque CoDel estime nécessaire de prendre des mesures (le trafic entre trop vite), il peut jeter les paquets, ou les marquer avec ECN (RFC 3168).
La section 2 de notre RFC définit la terminologie de CoDel. Parmi les termes importants :
- Temps de passage (sojourn time) : le temps passé par le paquet dans la file d'attente. C'est la donnée de base de CoDel, qui va essayer de minimiser ce temps de passage.
- File persistante (standing queue) : une file d'attente qui reste pleine trop longtemps, « trop » étant de l'ordre du RTT le plus élevé parmi les flots des paquets qui attendent dans la file.
Passons maintenant à une description de haut niveau de CoDel. Son but est de différencier la mauvaise file (qui ne fait qu'ajouter du retard d'acheminement des paquets) de la bonne. Une file d'attente se forme lorsqu'il y a un goulet d'étranglement, parce qu'un lien à forte capacité se déverse dans un lien à faible capacité, ou bien parce que plusieurs liens convergent vers un lien ayant la capacité de seulement l'un d'eux. Une notion importante à ce sujet est celle de BDP, en gros le nombre d'octets en transit pour une connexion donnée, lorsque le débit atteint 100 % de la capacité. Imaginons une connexion TCP dont la fenêtre d'envoi est de 25 paquets (je sais bien que les fenêtres TCP se calculent en octets, pas en paquets, mais c'est le RFC qui fait cet abus de langage, pas moi) et où le BDP est de 20 paquets. En régime permanent, il y aura 5 paquets dans la file d'attente. Si la fenêtre est de 30 paquets, ce seront 10 paquets qui occuperont en permanence la file d'attente, augmentant encore le délai, alors que le débit ne changera pas (20 paquets arriveront par RTT). Au contraire, si on réduit la fenêtre à 20 paquets, la file d'attente sera vide, le délai sera réduit au minimum, alors que le débit n'aura pas changé. Ce résultat contre-intuitif montre que bourrer la connexion de paquets n'est pas forcément le meilleur moyen d'aller « vite ». Et que la taille de la file ne renseigne pas sur le rythme d'envoi des données. Et enfin que les files pleines en permanence n'apportent que du délai. Dans le premier exemple, la file contenant cinq paquets tout le temps était clairement une mauvaise file. Un tampon d'entrée/sortie de 20 paquets est pourtant une bonne chose (pour absorber les variations brutales) mais, s'il ne se vide pas complètement ou presque en un RTT, c'est qu'il est mal utilisé. Répétons : Les bonnes files se vident vite.
CoDel comporte trois composants : un estimateur, un objectif et une boucle de rétroaction. La section 3 de notre RFC va les présenter successivement. Pour citer l'exposé de Van Jacobson à une réunion IETF, ces trois composants sont :
- a) Measure what you’ve got
- b) Decide what you want
- c) If (a) isn’t (b), move it toward (b)
D'abord, l'estimateur. C'est la partie de CoDel qui observe la file d'attente et en déduit si elle est bonne ou mauvaise. Autrefois, la principale métrique était la taille de la file d'attente. Mais celle-ci peut varier très vite, le trafic Internet étant très irrégulier. CoDel préfère donc observer le temps de séjour dans la file d'attente. C'est une information d'autant plus essentielle qu'elle a un impact direct sur le vécu de l'utilisateur, via l'augmentation de la latence.
Bon, et une fois qu'on observe cette durée de séjour, comment en déduit-on que la file est bonne ou mauvaise ? Notre RFC recommande de considérer la durée de séjour minimale. Si elle est nulle (c'est-à-dire si au moins un paquet n'a pas attendu du tout dans la file, pendant la dernière période d'observation), alors il n'y a pas de file d'attente permanente, et la file est bonne.
Le RFC parle de « période d'observation ». Quelle doit être la longueur de cette période ? Au moins un RTT pour être sûr d'écluser les pics de trafic, mais pas moins pour être sûr de détecter rapidement les mauvaises files. Le RFC recommande donc de prendre comme longueur le RTT maximal de toutes les connexions qui empruntent ce tampon d'entrée/sortie.
Et, petite astuce d'implémentation (un routeur doit aller
vite, et utilise souvent des circuits de
calcul plus simples qu'un processeur généraliste), on peut calculer
la durée de séjour minimale avec une seule variable : le temps écoulé
depuis lequel la durée de séjour est inférieure ou supérieure au
seuil choisi. (Dans le pseudo-code de la section 5, et dans le
noyau Linux, c'est à peu près le rôle de first_above_time.)
Si vous aimez les explications avec images, il y en a plein dans cet excellent exposé à l'IETF.
Ensuite, l'objectif (appelé également référence) : il s'agit de fixer un objectif de durée de séjour dans la file. Apparemment, zéro serait l'idéal. Mais cela entrainerait des « sur-réactions », où on jetterait des paquets (et ralentirait TCP) dès qu'une file d'attente se forme. On va plutôt utiliser un concept dû à l'inventeur du datagramme, Leonard Kleinrock, dans « An Invariant Property of Computer Network Power », la « puissance » (power). En gros, c'est le débit divisé par le délai et l'endroit idéal, sur la courbe de puissance, est en haut (le maximum de débit, pour le minimum de délai). Après une analyse que je vous épargne, le RFC recommande de se fixer comme objectif entre 5 et 10 % du RTT.
Enfin, la boucle de rétroaction. Ce n'est pas tout d'observer, il faut agir. CoDel s'appuie sur la théorie du contrôle, pour un système MIMO (Multi-Input Multi-Output). Au passage, si vous ne comprenez rien à la théorie du contrôle et notamment à la régulation PID, je vous recommande chaudement un article qui l'explique sans mathématiques. Placé à la fin de la file d'attente, au moment où on décide quoi faire des paquets, le contrôleur va les jeter (ou les marquer avec ECN) si l'objectif de durée de séjour est dépassé.
Passons maintenant à la section 4 du RFC, la plus concrète,
puisqu'elle décrit précisement CoDel. L'algorithme a deux
variables, TARGET et
INTERVAL (ces noms sont utilisés tels quels
dans le pseudo-code en section 5, et dans l'implémentation dans le
noyau Linux). TARGET est
l'objectif (le temps de séjour dans la file d'attente qu'on ne
souhaite pas dépasser) et INTERVAL est la
période d'observation. Ce dernier est également le seul paramètre
de CoDel qu'il faut définir explicitement. Le RFC recommande 100 ms
par défaut, ce qui couvre la plupart des RTT
qu'on rencontre dans l'Internet, sauf si on parle à des gens très
lointains ou si on passe par des satellites
(cf. M. Dischinger, « Characterizing Residential Broadband
Networks », dans les Proceedings of the Internet
Measurement Conference, San Diego, en 2007, si vous
voulez des mesures). Cela permet, par
exemple, de vendre des routeurs bas de gamme, genre
point d'accès Wifi sans imposer aux
acheteurs de configurer CoDel.
Si on est dans un environnement très différent de celui d'un
accès Internet « normal », il peut être nécessaire d'ajuster les
valeurs (CoDel n'est donc pas réellement
« parameterless »). L'annexe A du RFC en donne
un exemple, pour le cas du centre de
données, où les latences sont bien plus faibles (et les
capacités plus grandes) ;
INTERVAL peut alors être défini en
microsecondes plutôt qu'en millisecondes.
TARGET, lui, va être déterminé
dynamiquement par CoDel. Une valeur typique sera aux alentours de 5
ms (elle dépend évidemment de INTERVAL) : si, pendant une durée égale à INTERVAL, les paquets restent plus longtemps que cela dans la file
d'attente, c'est que c'est une mauvaise file, on jette des
paquets. Au passage, dans le noyau Linux, c'est dans
codel_params_init que ces valeurs sont
fixées :
params->interval = MS2TIME(100); params->target = MS2TIME(5);
Les programmeurs
apprécieront la section 5, qui contient du
pseudo-code, style
C++, mettant en œuvre CoDel. Le choix de C++
est pour profiter de l'héritage, car CoDel est juste une
dérivation d'un classique algorithme tail-drop. On
peut donc le programmer sous forme d'une classe qui hérite d'une
classe queue_t, plus générale.
De toute façon, si vous n'aimez pas C++, vous pouvez lire le
code source du noyau
Linux, qui met en œuvre CoDel depuis longtemps (fichier
net/sched/sch_codel.c, également accessible
via le Web).
(Pour comprendre les exemples de code, notez que packet_t* pointe vers un
descripteur de paquet, incluant entre autres un champ, tstamp, qui stocke
un temps, et que le type time_t est exprimé
en unités qui dépendent de la résolution du système, sachant que
la milliseconde est suffisante, pour du trafic Internet « habituel ».) Presque tout le travail de CoDel est fait au moment où le
paquet sort de la file d'attente. À l'entrée, on se contente
d'ajouter l'heure d'arrivée, puis on appelle le traitement
habituel des files d'attente :
void codel_queue_t::enqueue(packet_t* pkt)
{
pkt->tstamp = clock();
queue_t::enqueue(pkt);
}
Le gros du code est dans le sous-programme
dodequeue qui va déterminer si le paquet
individuel vient de nous faire changer d'état :
dodequeue_result codel_queue_t::dodequeue(time_t now)
{
...
// Calcul de *la* variable importante, le temps passé dans la
// file d'attente
time_t sojourn_time = now - r.p->tstamp;
// S'il est inférieur à l'objectif, c'est bon
if (sojourn_time_ < TARGET || bytes() <= maxpacket_) {
first_above_time_ = 0;
} else {
// Aïe, le paquet est resté trop longtemps (par rapport à TARGET)
if (first_above_time_ == 0) {
// Pas de panique, c'est peut-être récent, attendons
// INTERVAL avant de décider
first_above_time_ = now + INTERVAL;
} else if (now >= first_above_time_) {
// La file ne se vide pas : jetons le paquet
r.ok_to_drop = true;
}
}
return r;
}
Le résultat de dodequeue est ensuite utilisé
par dequeue qui fait se fait quelques
réflexions supplémentaires avant de jeter réellement le paquet.
Ce code est suffisamment simple pour pouvoir être mis en œuvre dans le matériel, par exemple ASIC ou NPU.
L'annexe A du RFC donne un exemple de déclinaison de CoDel pour le cas d'un centre de données, où les RTT typiques sont bien plus bas que sur l'Internet public. Cette annexe étudie également le cas où on applique CoDel aux files d'attente des serveurs, pas uniquement des routeurs, avec des résultats spectaculaires :
- Dans le serveur, au lieu de jeter le paquet bêtement, on prévient directement TCP qu'il doit diminuer la fenêtre,
- Le RTT est connu du serveur, et peut donc être mesuré au
lieu d'être estimé (on en a besoin pour calculer
INTERVAL), - Les paquets de pur contrôle (
ACK, sans données) ne sont jamais jetés, car ils sont importants (et de petite taille, de toute façon).
Sur l'Internet public, il serait dangereux de ne jamais jeter les paquets de pur contrôle, ils pourraient être envoyés par un attaquant. Mais, dans le serveur, aucun risque.
Également à lire : un article de synthèse sur le blog de l'IETF.
L'article seul
RFC 8307: Well-Known URIs for the WebSocket Protocol
Date de publication du RFC : Janvier 2018
Auteur(s) du RFC : C. Bormann (Universitaet Bremen
TZI)
Chemin des normes
Première rédaction de cet article le 3 janvier 2018
Il existe une norme pour un préfixe de chemin dans un
URI, préfixe nommée
.well-known, et après lequel plusieurs noms
sont normalisés, pour des ressources « bien connues »,
c'est-à-dire auxquelles on peut accéder sans lien qui y mène. Le
RFC 8615 normalise ce
.well-known. Son prédécesseur n'était prévu à l'origine que
pour les plans http: et
https:. Ce très court
RFC l'a étendu aux plans
ws: et wss:, ceux des
Web sockets du RFC 6455. Depuis, notre RFC a été intégré dans la nouvelle
norme de .well-known, le RFC 8615.
Les gens de CoAP avaient déjà étendu
l'usage de .well-known en permettant (RFC 7252) qu'il soit utilisé pour les plans
coap: et coaps:.
Il existe un registre IANA des
suffixes (les termes après .well-known). Ce
registre est le même quel que soit le plan d'URI utilisé. Il ne
change donc pas suite à la publication de ce RFC.
L'article seul
Fiche de lecture : Le médecin qui voulut être roi
Auteur(s) du livre : Guillaume Lachenal
Éditeur : Seuil
9-782021-142563
Publié en 2017
Première rédaction de cet article le 3 janvier 2018
Voici un excellent livre sur le colonialisme, à travers le cas d'un médecin français, Jean-Joseph David, qui, en poste à Wallis, puis au Cameroun, a obtenu les pleins pouvoirs, et s'est lancé dans une utopie, créer une société parfaite.
C'est une banalité de parler de pouvoir médical et de dire que le médecin se sent souvent placé au dessus des autres humains. Mais ici, dans les deux pays, David a en effet réussi à avoir la totalité des pouvoirs, médical, mais aussi économique, administratif, policier et judiciaire (il pouvait punir, et il ne s'en privait pas). Tout partait pourtant d'une idée sympathique, celle de la « médecine sociale », l'idée, en rupture avec la médecine pasteurienne, qu'on ne pouvait pas considérer la maladie comme le résultat de la seule action des microbes, mais qu'il fallait prendre en compte tout l'environnement. Mais cette idée a vite mené à un dérapage qu'on doit pouvoir qualifier de totalitaire. Le médecin s'est en effet senti en droit de réorganiser toute la société selon ses vues, évidemment sans jamais demander leur avis aux habitants.
Jean-Joseph David était-il gentil ou méchant ? Il traitait bien les indigènes, mais comme un éleveur traite bien son troupeau. Il ne les considérait pas comme des citoyens, même pas complètement comme des humains, quand il parlait d'« améliorer la race » ou bien d'amener beaucoup d'enfants à l'âge adulte pour que la France ait beaucoup de tirailleurs. Et ses utopies ont parfois eu des conséquences graves. Il était clairement mégalomane (« la mégalomanie est une maladie tropicale », note un ancien des interventions en Afrique à l'auteur) mais était aussi le produit de son époque (la culture du Pharo, où tous ces médecins coloniaux étaient formés par d'anciens coloniaux) et de l'éloignement (depuis Yaoundé, le gouverneur français le laissait faire ce qu'il voulait).
Le titre du livre fait évidemment référence à Kipling mais, ici, le héros ne cherche pas juste à être roi et à en avoir les avantages, il veut vraiment transformer la société.
Le livre est un peu décousu, d'abord parce qu'on a peu d'archives sur David (une grande partie a disparu dans les troubles qu'a connu le Cameroun par la suite), ensuite parce que ce n'est pas un roman, mais un travail plutôt universitaire, avec beaucoup de notions de sociologie et d'anthropologie qui nécessiteront que l·e·a lect·eur·rice s'accroche. Mais cela vaut la peine, il y a eu peu de descriptions de ce genre d'« utopies coloniales » où un mégalomane, profitant du pouvoir que lui donnait la force militaire de la France, se disait « je vais enfin pouvoir remodeler la société ». On est choqués de sa dictature et en même temps, c'est fascinant de se demander « et moi, si j'avais un tel pouvoir, j'en ferais quoi ? »
- Le court article de Libération sur ce livre,
- Un article plus détaillé et plus intéressant dans la Vie des Idées, insistant sur les contradictions du colonialisme, et l'importance de ne pas en faire une analyse manichéenne,
- Un interview de l'auteur sur TV5 Monde.
L'article seul
Fiche de lecture : La mer des Cosmonautes
Auteur(s) du livre : Cédric Gras
Éditeur : Paulsen
Publié en 2017
Première rédaction de cet article le 1 janvier 2018
Il fait froid dehors, en ce début 2018 ? Voici un livre pour se réchauffer : partez en Antarctique avec les polyarniks russes.
Ce n'est pas un roman, mais un témoignage de l'auteur, qui est allé en Antarctique (en été, quand même…) à bord du Akademik Fedorov et en a rapporté plein d'histoires de travailleurs polaires. Et, oui, la mer des Cosmonautes du titre existe vraiment.
Le temps des explorateurs polaires avec trois types et quinze chiens qui se lançaient à l'assaut du continent blanc est passé : les bases sont maintenant bien plus grandes et peuplées, avec une débauche de matériel. Dans les bases russes, on trouve tous les fleurons de l'ex-industrie soviétique, devenues souvent épaves, de l'Iliouchine 14 au GAZ-69. On est maintenant dans l'exploitation plus que l'exploration. Mais les conditions de vie restent difficiles : le matériel casse, les humains s'épuisent, l'accident guette dès qu'on sort, il faut parfois allumer un feu sous le bulldozer pour qu'il démarre. Et les Russes prennent apparemment moins de précautions avec le matériel humain, alimentant le cimetière qui jouxte une des bases.
Mais pourquoi trouve-t-on des volontaires pour l'Antarctique ? À l'époque soviétique, une des raisons était le prestige attaché au métier de polyarnik. Leur prestige ne le cédait qu'aux cosmonautes, héros souvent cités par les polyarniks nostalgiques « à cette époque, on était quasiment aussi adulés que les cosmonautes », et les gamins dans les cours d'école jouaient en alternance au cosmonaute et au travailleur polaire. Tout ceci s'est effondré avec l'Union Soviétique, au point que, dans certaines bases, il a fallu vendre les breloques à étoile rouge aux touristes états-uniens de la base voisine, pour pouvoir se financer. Il n'y a plus qu'en Biélorussie, gelée dans les années Brejnev, que les polyarniks sont encore accueillis avec médailles et discours, à leur retour.
Aujourd'hui, la Russie continue l'exploitation antarctique, mais avec un nombre de bases réduit. Des nouveaux pays sont venus, et on s'échange les visites de courtoisie, dans ce territoire démilitarisé. Le travailleur polaire continue de bénéficier d'avantages matériels conséquents, et garde un peu de prestige, pas à cause de l'Antarctique, mais à cause des escales exotiques que fait le navire avant d'atteindre le continent blanc. Et puis, certains travailleurs le confient à l'auteur : après plusieurs rotations en Antarctique, ils ne se voient pas vraiment reprendre une vie « normale ».
En ligne, les photos de l'auteur.
L'article seul
Articles des différentes années : 2024 2023 2022 2021 2020 2019 2018 Précédentes années
Syndication : Flux Atom avec seulement les résumés et Flux Atom avec tout le contenu.
{kind=link}